多语言 Google Meet Summarizer – Python项目
2020 年初,我们面临着 21 世纪最大的危机——COVID-19 大流行。在混乱中,这一代人最终找到了通过在生活的其他各个方面引入自动化来完成工作的方法。大流行之后,我们发现用于日常通信的视频会议工具增长了 87%。从在线聚会、大学讲座、商务会议,几乎所有的交流都托管到互联网上,互联网是虚拟的,蚕食了无意义的交流机会。事实上,从各个领域的员工那里收集的数据表明,人们经常会错过重要的点,因为他们发现记录这些会议是一项耗时、分散注意力且非常无聊的任务,并且在这些毫无成效的会议上浪费了超过 370 亿美元.因此出现了对自动文本摘要的需求。

该项目的目的是通过应用核心机器学习技术对在线会议进行转录和总结,以生成会议纪要和多语种总结音频,从而让用户更好地理解主题。
chrome 扩展提出的功能是——
- 满足转录
- 使用提取和抽象模型进行总结。
- 多语言音频生成。
提供的附加功能 –
- NPTEL/MOOC讲座总结
- 作为 Twitter Tweet Shortner。
工具和技术
- 前端: Reactjs、Material-UI、Bootstrap、HTML、CSS、Javascript
- 后端: Django,Django Rest API
- 数据库: SQLite
- 机器学习库: NLTK、Torch
先决条件
了解Python、NLP 库、Rest API 的使用以及使用 Reactjs 进行 Web 开发的良好工作经验。
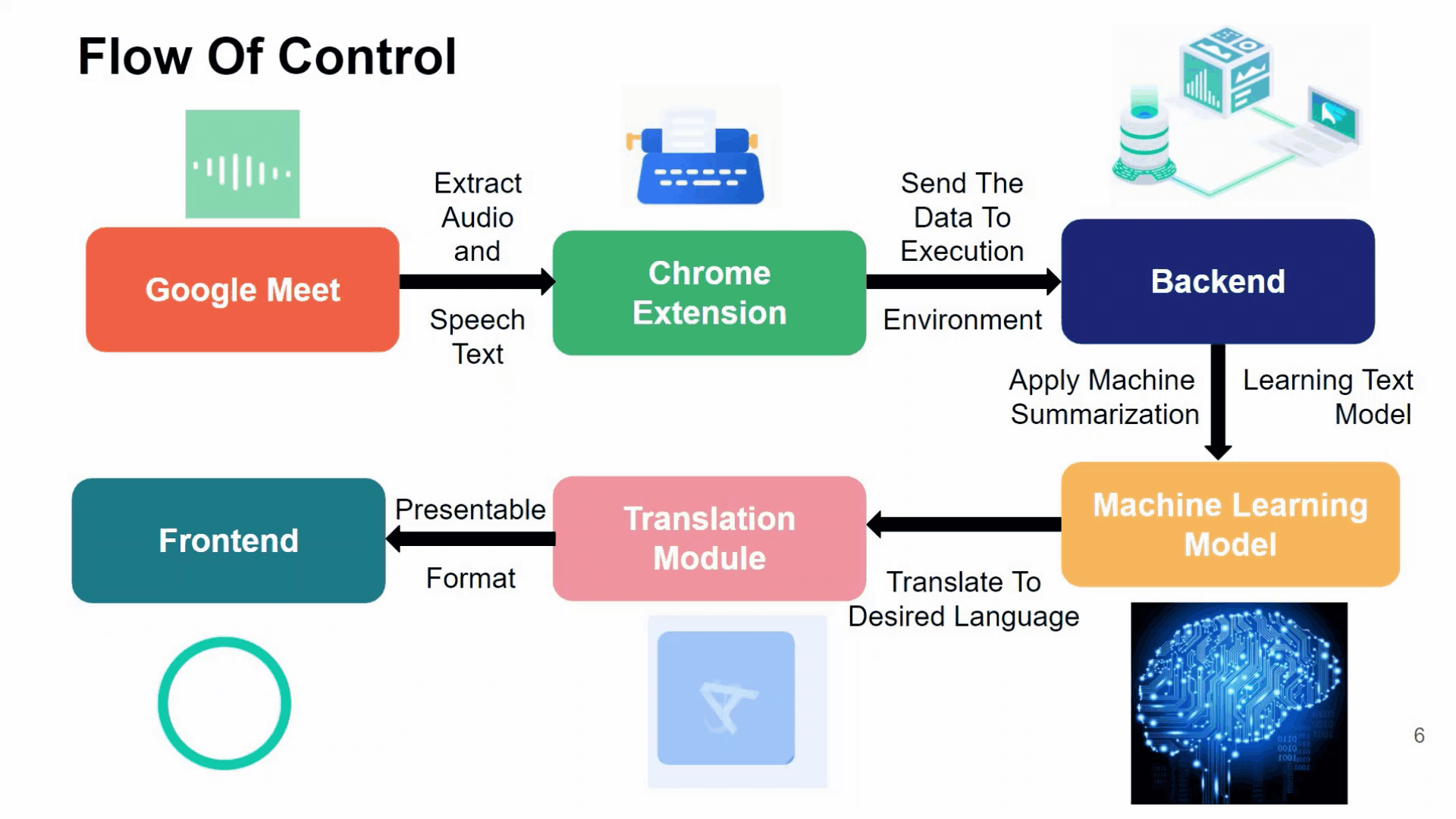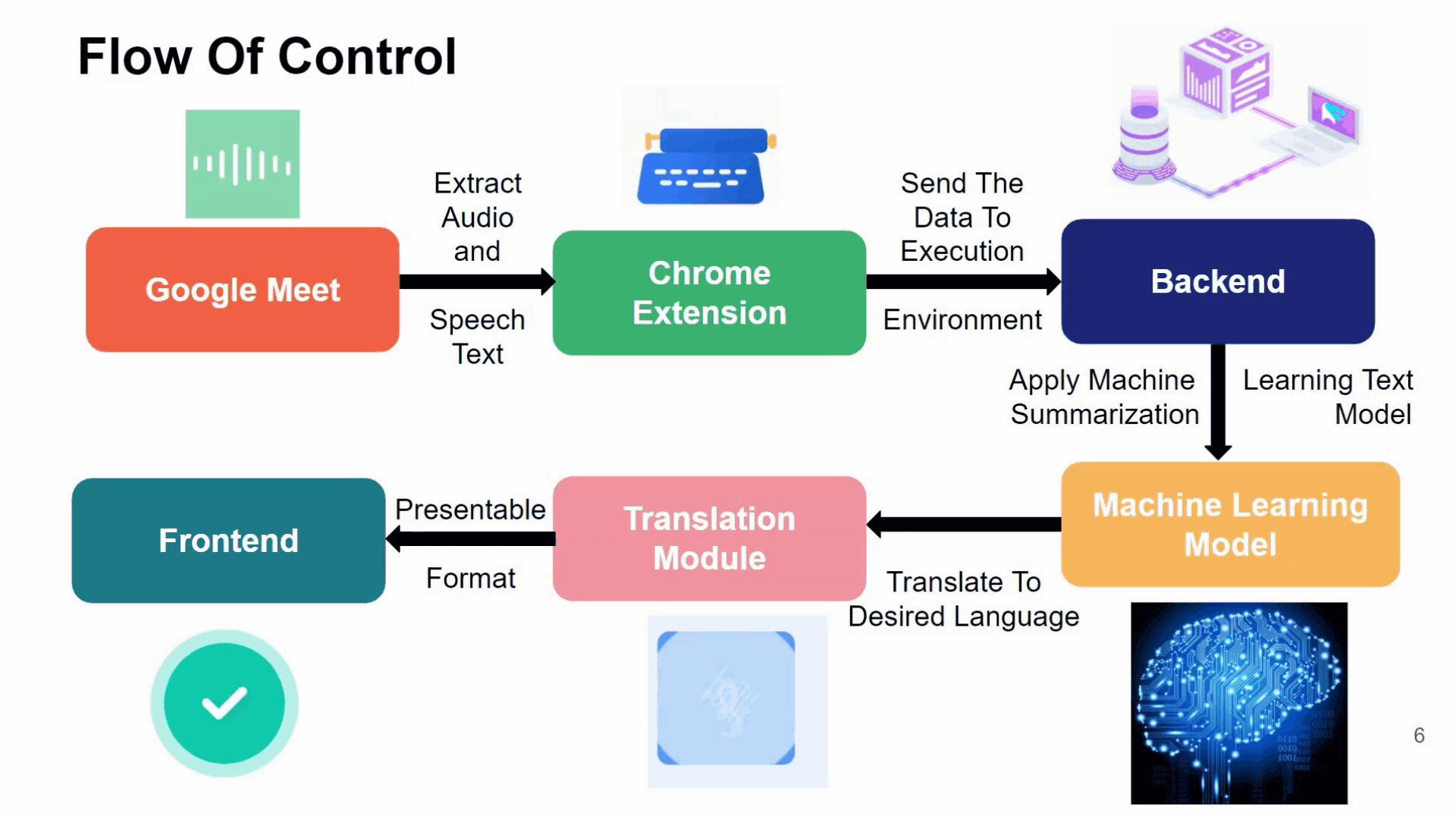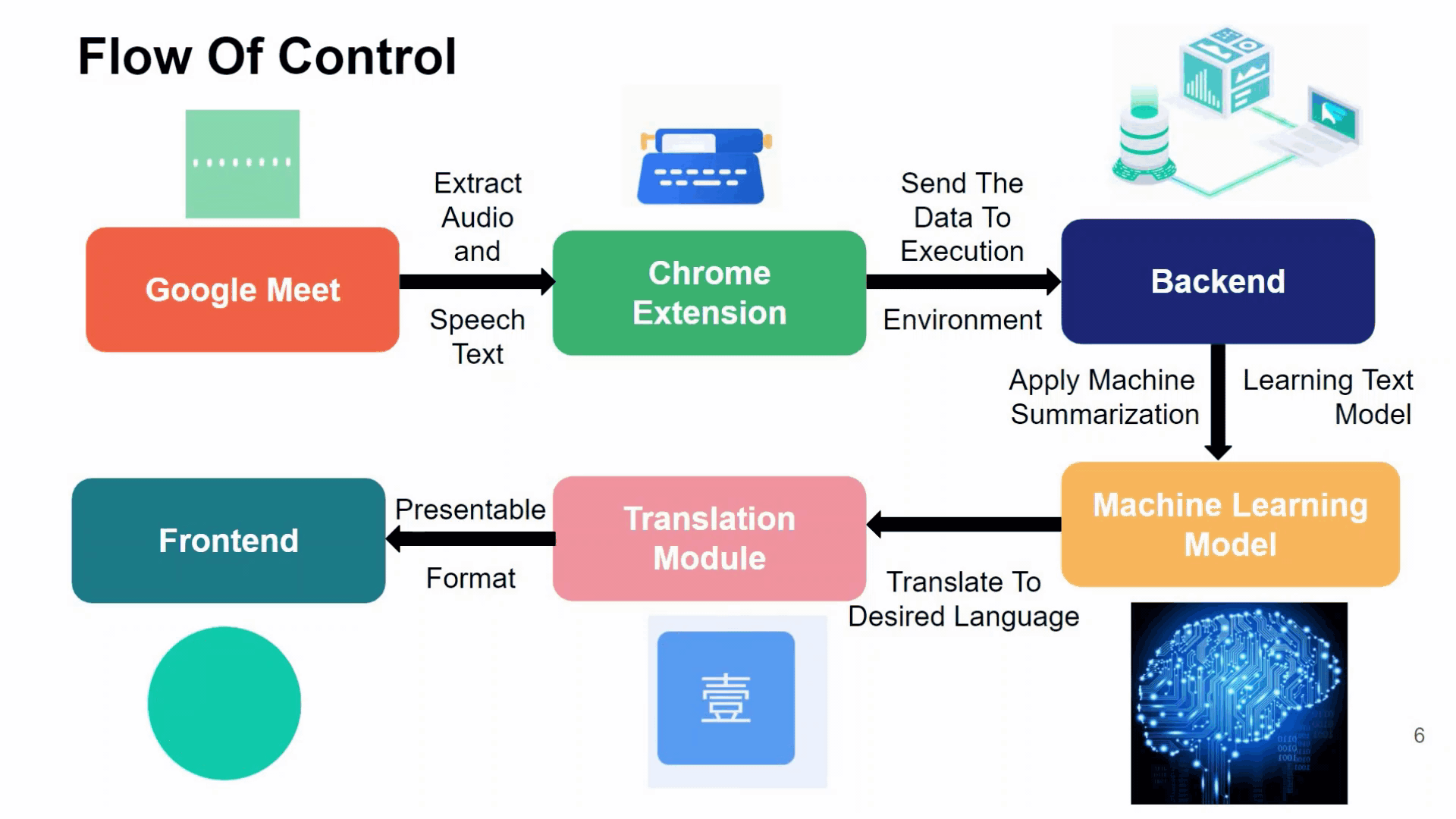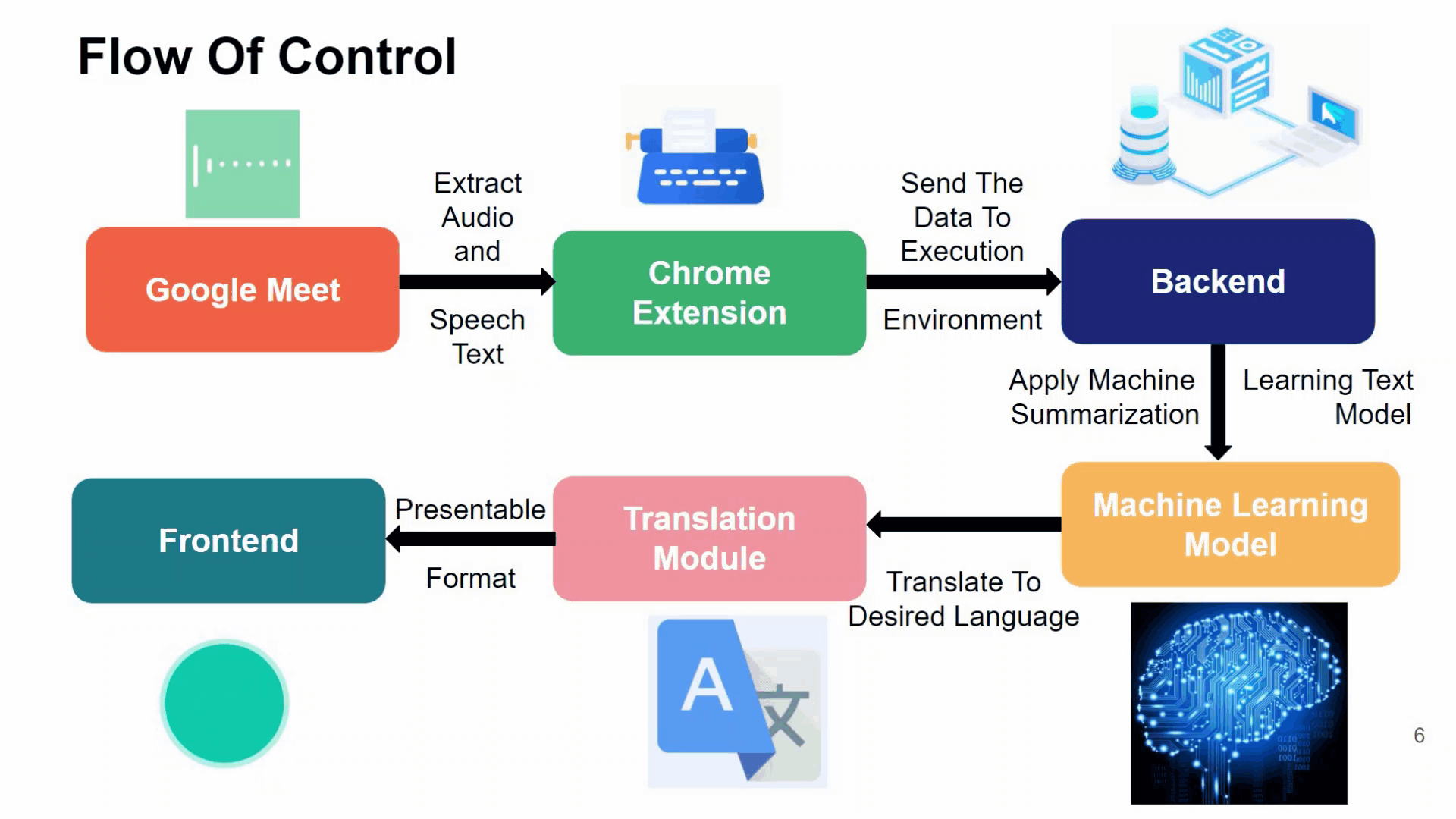
控制流
- 用户登录网站并启用 chrome 扩展。
- chrome 扩展从 Google meet 中提取关于每个演讲者的音频,并通过 chrome 扩展转录它。
- 这个提取的成绩单被进一步发送到后端,在那里应用硬核机器学习技术进行文本摘要。
- 然后将此经过超处理的文本定向到翻译人员,以将摘录翻译成用户所需的语言
- 然后可以根据用户的意愿下载或什至在仪表板上收听该成绩单。
这就是多语言 Google Meet Summarizer 如何为流行病驱动的自动化做出贡献。
步骤 B 步骤实施
1. Chrome 扩展
chrome 扩展的主要任务是从 Google Meet 的 DOM 元素中提取 google meet 标题。它利用了由 Google Meet 的内置功能生成的字幕容器——打开字幕。会议转录如下——
- 在selenium的帮助下,“打开字幕”按钮的 Xpath 被追踪出来。
- 该代码通过自动点击字幕按钮自动激活 Google Meet 字幕。
- 然后我们追踪字幕容器的 Xpath 并提取在容器内滚动的自动生成的文本。
- 最后,我们将文本附加到一个带有说话者姓名和时间戳的字符串。
然后将完整的文本发送到后端进行处理。
2. 前端和后端
- 第一步将是为用户创建一个身份验证系统,以便能够登录并将他们的会议记录保存在数据库中。
- 在 Django 中创建一个用户模型。
- 使用 djangorestframework_simplejwt 应用程序在 Django 中实现 JWT(JSON Web 令牌)。
- 为令牌生成和身份验证创建相应的 REST 视图。
- 还可以根据喜好使用 JWT 进行社交身份验证而不是电子邮件注册。
- 下一步将是创建一个用于存储用户会面记录信息的数据库。在类似的行上创建一个标准的 SQL 关系,如下所示。
- 成绩单(成绩单 ID、所有者姓名、成绩单日期、主机名、成绩单标题、会议持续时间、内容)。
- 根据要提供给用户的 CRUD 功能,还可以使用其他字段和模式。
- 创建用于在数据库中保存新成绩单的 REST API。 chrome 扩展将使用此 API,它将发送其成绩单以及元信息,如时间戳、主机名等。
API 处理接收到的信息并将其存储在数据库中。 - 为要用于汇总的每个 NLP 模型创建单独的 API。前端会将成绩单发送到此 API。 API 使用 NLP 模型并将汇总文本返回给前端。 API 只是运行下面描述的 ML NLP 脚本。创建用于将文本翻译成多种语言的 API。
Python3
'''
Translation Code
'''
from googletrans import Translator
LANGUAGE_CODES = {
'ENGLISH': 'en',
'HINDI': 'hi',
'MARATHI': 'mr',
'ARABIC': 'ar',
'BENGALI': 'bn',
'CHINESE': 'zh-CN',
'FRENCH': 'fr',
'GUJRATI': 'gu',
'JAPANESE': 'ja',
'KANNADA': 'kn',
'MALAYALAM': 'ml',
'NEPALI': 'ne',
'ORIYA': 'or',
'PORTUGUESE': 'pt',
'PUNJABI': 'pa',
'RUSSIAN': 'ru',
'SPANISH': 'es',
'TAMIL': 'ta',
'TELUGU': 'te',
'URDU': 'ur'
}
def translate_utility(inp_text, inp_lang, op_lang):
inp_lang, op_lang = inp_lang.upper(), op_lang.upper()
translator = Translator()
text_to_translate = translator.translate(
inp_text, src=LANGUAGE_CODES[inp_lang], dest=LANGUAGE_CODES[op_lang])
op_text = text_to_translate.text
return(op_text)Python3
'''
NLTK MODEL CODE
'''
# Tokenizing Sentences
from nltk.tokenize import sent_tokenize
# Tokenizing Words
from nltk.tokenize import word_tokenize
import nltk
from string import punctuation
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
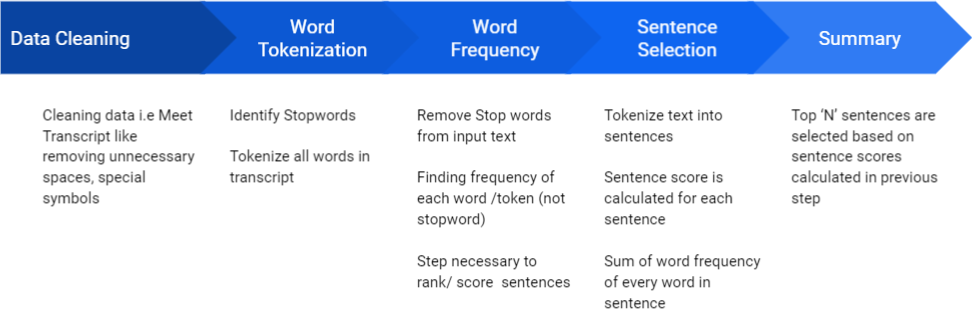
# Cleaning text that is got from meet transcript
def clean(text):
sample = text.split('**')
sample.pop(0)
clean_text = ""
i = 0
for t in sample:
if i % 2 != 0:
clean_text += str(t)
i += 1
return clean_text
# Finding list of stopwords ( Stopwords are
# those which do not add meaning to sentence)
stop_words = set(stopwords.words("english"))
# Tokenize
def Wtokenize(text):
words = word_tokenize(text)
return words
# Frequency table will be storing frequency of each word
# appearing in input text after removing stop words
# Need: It will be used for finding most relevant sentences
# as we will be applying this dictionary on every sentence
# and find its importance over other
def gen_freq_table(text):
freqTable = dict()
words = Wtokenize(text)
for word in words:
word = word.lower()
if word in stop_words:
continue
if word in freqTable:
freqTable[word] += 1
else:
freqTable[word] = 1
return freqTable
# Sentence Tokenize
def Stokenize(text):
sentences = sent_tokenize(text)
return sentences
# Storing Sentence Scores
def gen_rank_sentences_table(text):
# dictionary storing value for each sentence
sentenceValue = dict()
# Calling function gen_freq_table to get frequency
# of words
freqTable = gen_freq_table(text)
# Calling list of sentences after tokenization
sentences = Stokenize(text)
for sentence in sentences:
for word, freq in freqTable.items():
if word in sentence.lower():
if sentence in sentenceValue:
sentenceValue[sentence] += freq
else:
sentenceValue[sentence] = freq
return sentenceValue
def summary(text):
sum = 0
sentenceValue = gen_rank_sentences_table(text)
for sentence in sentenceValue:
sum += sentenceValue[sentence]
avg = int(sum / len(sentenceValue))
summary = ""
sentences = Stokenize(text)
for sentence in sentences:
if (sentence in sentenceValue) and (sentenceValue[sentence] > (1.2 * avg)):
summary += " " + sentence
return summary
def mainFunc(inp_text):
# getting text cleaned
if("**" not in inp_text):
text = inp_text
else:
cleaned_text = clean(inp_text)
text = cleaned_text
summary_text = summary(text)
print("\nModel Summary: ", summary_text)
return summary_text3. 机器学习算法

蟒蛇3
'''
NLTK MODEL CODE
'''
# Tokenizing Sentences
from nltk.tokenize import sent_tokenize
# Tokenizing Words
from nltk.tokenize import word_tokenize
import nltk
from string import punctuation
from nltk.corpus import stopwords
nltk.download('stopwords')
nltk.download('punkt')
# Cleaning text that is got from meet transcript
def clean(text):
sample = text.split('**')
sample.pop(0)
clean_text = ""
i = 0
for t in sample:
if i % 2 != 0:
clean_text += str(t)
i += 1
return clean_text
# Finding list of stopwords ( Stopwords are
# those which do not add meaning to sentence)
stop_words = set(stopwords.words("english"))
# Tokenize
def Wtokenize(text):
words = word_tokenize(text)
return words
# Frequency table will be storing frequency of each word
# appearing in input text after removing stop words
# Need: It will be used for finding most relevant sentences
# as we will be applying this dictionary on every sentence
# and find its importance over other
def gen_freq_table(text):
freqTable = dict()
words = Wtokenize(text)
for word in words:
word = word.lower()
if word in stop_words:
continue
if word in freqTable:
freqTable[word] += 1
else:
freqTable[word] = 1
return freqTable
# Sentence Tokenize
def Stokenize(text):
sentences = sent_tokenize(text)
return sentences
# Storing Sentence Scores
def gen_rank_sentences_table(text):
# dictionary storing value for each sentence
sentenceValue = dict()
# Calling function gen_freq_table to get frequency
# of words
freqTable = gen_freq_table(text)
# Calling list of sentences after tokenization
sentences = Stokenize(text)
for sentence in sentences:
for word, freq in freqTable.items():
if word in sentence.lower():
if sentence in sentenceValue:
sentenceValue[sentence] += freq
else:
sentenceValue[sentence] = freq
return sentenceValue
def summary(text):
sum = 0
sentenceValue = gen_rank_sentences_table(text)
for sentence in sentenceValue:
sum += sentenceValue[sentence]
avg = int(sum / len(sentenceValue))
summary = ""
sentences = Stokenize(text)
for sentence in sentences:
if (sentence in sentenceValue) and (sentenceValue[sentence] > (1.2 * avg)):
summary += " " + sentence
return summary
def mainFunc(inp_text):
# getting text cleaned
if("**" not in inp_text):
text = inp_text
else:
cleaned_text = clean(inp_text)
text = cleaned_text
summary_text = summary(text)
print("\nModel Summary: ", summary_text)
return summary_text
输出
项目在现实生活中的应用
- 用于商务虚拟会议
- 学生用于从讲座中获取简明笔记
- 对视障人士的帮助
- 也作为 Twitter Tweet Shortener
队员
- Tejas Sudhir 小吃
- 亚什·阿格拉瓦尔
- 阿图尔塔克雷
- 阿尤什·凯迪亚
- 亚什·泰尔卡德