PostgreSQL – 备份数据库
所有商业公司和公司都不会 100% 免受数据威胁。警惕数据损坏、主机或网络故障甚至蓄意破坏存储设施等情况非常重要。因此,备份数据是每个公司赖以确保其在市场上存在的关键活动。服务器备份背后的理念不仅仅是在市场上的竞争能力。以下是经常进行备份的几个原因:
- 数据丢失预防:在网络威胁或灾难等可怕情况下,数据必须以其真实的外观保持活力。
- 企业健康:所有企业都必须审查他们的记录,以保持对所有级别的数据库安全性的依赖和了解。
- 培养责任感:备份服务器是公司在信息安全方面获得消费者信任的最流畅方式。
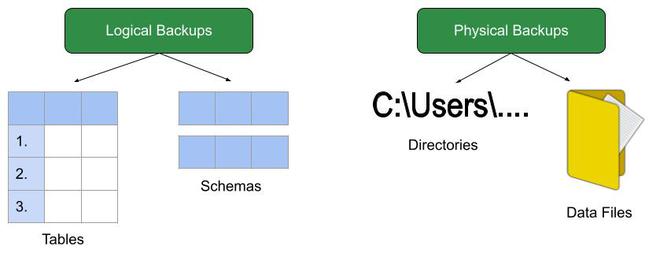
PostgreSQL 在市场上占有显着的份额,将 MySQL 置于无可争议的领先地位。正如任何具有如此高标准的数据库管理系统的惯例一样,PostgreSQL 提供了一组逻辑和物理备份。对于那些不知道区别的人:
- 逻辑备份包含有关数据库的信息,例如表和模式,而物理备份包含信息的文件和目录。
- 与物理备份相比,逻辑备份的大小更小。
从概念上讲,有多个级别的备份(差异、完整、增量等),但这不是本文的目标。我们将处理 PostgreSQL 为其用户提供的方法。在这里,我们将重点介绍其中的 3 个——
- 文件系统级备份
- SQL 转储
- 连续或重复归档
文件系统级备份
文件系统级备份是物理备份。这个想法是制作创建数据库的所有文件的副本。这意味着我们正在查看 PostgreSQL 用于将数据写入数据库的数据库集群和目录。解释这一点的一种方法是将自己想象成发表研究论文的科学家,并使用大量以前的书面工作来定义您的工作。您参考的作品形成了一个框架和布局,指导您整个写作过程。 PostgreSQL 尝试复制的文件是框架和布局以及包含数据的指南(特别是一堆.dat文件)。
抄袭声明:
tar -cf backup.tar /%p $PATH TO DATA FILE/%f $FILENAME
OR
rsync -v /var/lib/pgsql/13/backups/ /Directory 2/请注意,会创建一个.tar文件,即磁带存档。同时,rsync 是一个同步两个目录的命令。因此,如果目录 2 的内容与第一个目录 (/var/lib/....) 的内容不同,那么它会在执行后 - 一种切割形式的复制。
但是,我们必须在执行之前启用存档。显然,简单地复制数据被认为是粗心的;正在进行的事务将影响正在复制的文件的即时状态,从而导致备份状态及其可靠性出现问题。
注意:这是与本文讨论的最后一种方法的故意重叠;它有助于提高备份质量。
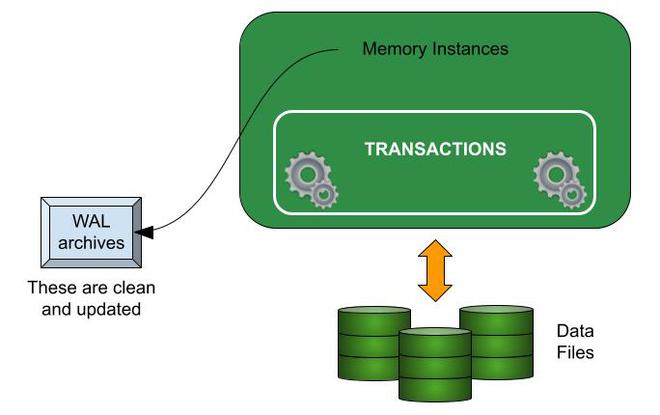
因此,我们首先启用 WAL 归档。 WAL 档案是维护事务所做的所有修改的文件,以保持数据库和实例内存中的数据一致。
WAL files are ‘Write-Ahead Log’ files. All transactions performed are first written to the WAL file before those changes are applied to the actual disk space. WAL archives are copies of the WAL files and exist in a separate directory to avoid plausible crashes.
步骤 1:首先以特权用户身份连接到数据库,然后运行以下命令来启动备份。 /db 是您要备份的数据库的名称。
SELECT pg_start_backup('label',false,false);
tar -cf -z backup_name.tar /db $the name of the database you wish to backup- -cf :这表示“自定义格式”。通过包含此内容,用户声明存档文件将具有自定义格式。这在重新导入文件时引入了灵活性。
- -z :命令的此属性指示 postgreSQL 压缩输出文件。
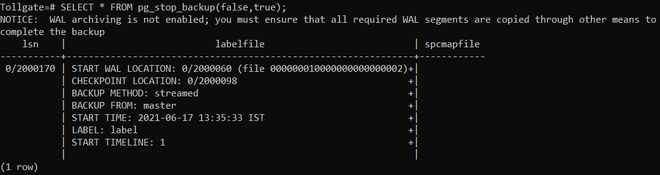
第 2 步:告诉数据库终止备份模式。
SELECT * FROM pg_stop_backup(false, true);该命令的作用还在于创建一个.backup文件,帮助识别第一个和最后一个存档日志。这在恢复数据库时很重要。
在很可能用户忘记启用 WAL 归档的情况下,这会显示在 shell 上:
在 postgresql.conf 文件中设置以下内容:
-wal_level = replica
-archive_mode = on
-archive_command = 'cp %p /%f'这将启用 WAL 归档。 %p 是路径名,%f 是文件名。只能通过命令行在配置文件中设置参数。
文件系统级备份的缺点:
- 他们需要备份整个数据库。备份模式或仅备份特定表不是一种选择。这同样适用于恢复过程,即必须恢复整个数据库。
- 因此,默认情况下它们会占用更多的存储空间。
- 必须停止服务器才能获得可用的备份。这会导致不必要的开销并破坏业务交易的连续性。
最近的选择:
发出备份的另一种方法是使用pg_basebackup ,原因如下:
- 从备份中恢复更快更安全
- 它是特定于安装版本的
- 备份是通过复制协议完成的
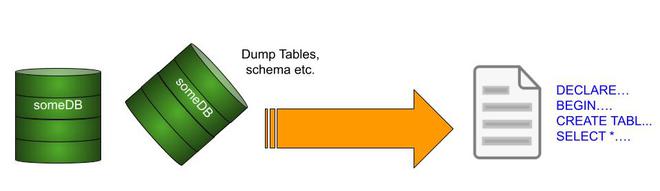
SQL 转储
对于较小的数据库,执行 SQL 转储要方便得多。 SQL 转储是逻辑备份。这意味着该方法将备份用于创建模式和表的所有指令。因此,备份后导出的文件实际上是一个充满 DDL 和 DML 命令的文件。
PostgreSQL 提供了两种可以执行 SQL 转储的方法。
使用 pg_dump
pg_dump是一个简单的命令,它在服务器上创建一个数据库的副本。可以将其视为“将仅一个数据库的目标文件转储到一个新文件中”。在此过程结束时,会创建一个可人工解释的新文件(填充有 SQL 命令)。 pg_dump 使用以下选项:
- -Fc :以自定义格式导出文件 - 上面针对文件系统级备份进行了说明
- -Z :这与压缩数据的命令一起使用。正如人们所料,这用于大型数据库。
- -j : 用于再次使用 pg_dump 启用并行备份
- -a :此选项指定仅备份数据。
- -s :当只需要备份模式时使用。
- -t :当只需要备份数据库的表时使用。
- 以下是用户可以使用 pg_dump 创建 SQL 转储的示例格式:
>> C:\Program Files\PostgreSQL\13\bin
>> pg_dump -U username -W -F p database_name > path_to_output_file.sql
>> Password:
>>(For example)
>> pg_dump -U dbuser04 -W -F p My_University > University_backup.sql用户必须首先导航到安装在终端或 CMD 上的 PostgreSQL 版本的\bin 文件夹。一旦完成,就可以执行命令——如前所述。建议在执行之前在已知位置创建输出文件(不要依赖 PostgreSQL 为您创建它)。在上面的命令中, -W是一个选项,可以通过密码验证用户。 -F用于在后面的字符指定输出文件的格式(记得改变输出文件的扩展名)。所以:
- p = 纯文本文件
- t = tar 文件
- d = 目录格式存档
- c = 自定义格式存档
使用 pg_dumpall:
明显的警告是pg_dump如何被限制为一次创建单个数据库的副本。对于必须备份服务器中的多个数据库的情况,PostgreSQL 提供了pg_dumpall命令。在大多数情况下,它的语法保持不变,除了 – W之外的选项也是如此(老实说,没有人真的想为他们备份的每个数据库输入密码)。
>> C:\Program Files\PostgreSQL\13\bin
>> pg_dumpall -U username -F p > path_to_output_file.sql在许多情况下,公司可能更愿意只制作模式或某些对象定义的副本,而不是真正的数据。这是非常重要的。
>> pg_dumpall --tablespaces-only > path_to_output_file.sql $for only tablespaces
>> pg_dumpall --schema-only > path_to_output_file.sql $for only schemasSQL Dump 的缺点:
基于公司的多个 IT 派别使用 PostgreSQL 服务器进行日常程序,SQL 转储的缺点很容易激发使用其他方法进行备份和恢复。
- 正如我们所见,SQL 转储根据存储在输出文件中的指令字面上重新创建每个变量。事实上,它也适用于重建所有索引。因此,恢复速度的上限是显而易见的。
- 上述的一个主要后果是企业从不欢迎的不必要的开销。
- 从技术上讲,由于同时发生多个转储,语法反转是一个主要问题。
- 作为逻辑导出,SQL 转储可能不是 100% 可移植的。
例子:
考虑一个数据库“crimedb”,它在警察登记处存储所有罪犯的记录。我们将尝试定期备份所有表。
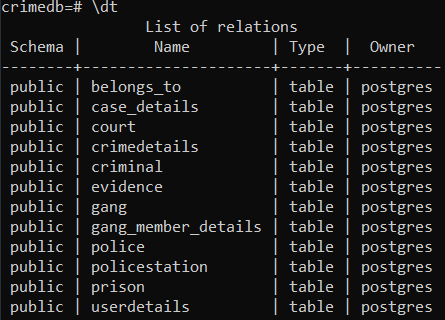
犯罪数据库中所有表的列表

pg_dump 的执行

来自创建的 Postgres 转储文件criminal_backup.sql 的实例
连续归档
与之前讨论的方法相比,这是一个相当复杂的过程。然而,好处占了上风。
连续或重复归档结合了发布文件系统级备份和 WAL 文件备份的想法(从技术上讲,分别启用 WAL 归档)。这似乎又是一次文件系统级备份,但额外强调的是在备份进行时保留而不只是归档 WAL 文件。这使我们能够在离线时拍摄数据库的“同时快照”。另一个区别在于恢复过程——连续归档备份的恢复有很大不同。
本节介绍时间点恢复备份。这是一种连续归档的形式,用户可以将数据备份和恢复到过去的某个时间点。文字游戏基于创建的最新 WAL 档案。
简而言之,程序如下:
- 启用 WAL 归档
- 创建保留 WAL 文件的方式。
- 进行文件系统级备份(这次我们将使用pg_basebackup )。
- 保留备份,以便将 DB 重播到某个时间点。
首先,让我们连接到服务器并在 psql shell 中执行以下操作:
>> show archive_mode;如果存档被禁用,则会显示以下内容:
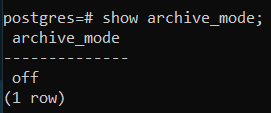
第一步(启用归档)根据操作系统和有时安装的 Postgres 版本因系统而异。所有剩余步骤都遵循一个通用程序。
第 1 步(Windows):
首先,从 Windows 服务管理器中停止 Postgres 服务。
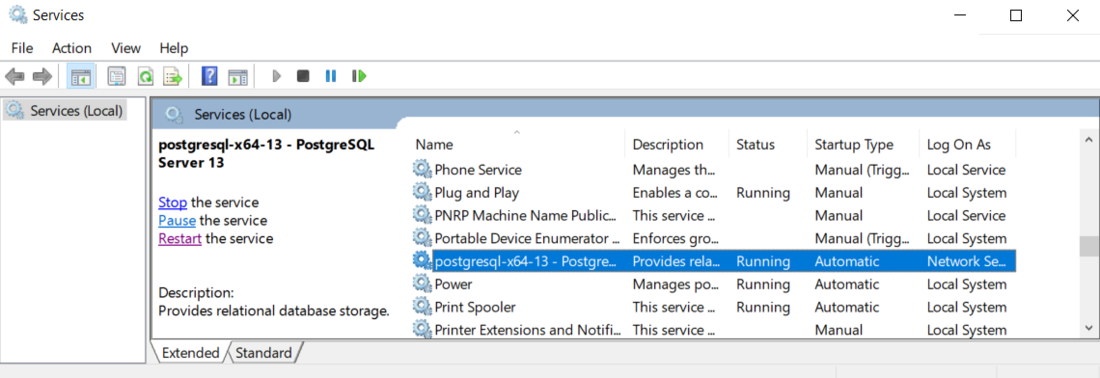
在任务栏中键入 services.msc 并运行它以访问此面板。
现在,前往 \data 目录中的 Postgres.conf 文件。例如C:\Program Files\PostgreSQL\13\data并进行以下参数更改:
>> archive_mode = on
>> archive_command = 'copy "%p" "C:\\server\\archivedir\\%f"'
>> wal_level = replica将 %p 替换为我们希望存档的文件的路径,即pg_wal ,并将 %f 替换为文件名。请确保对目录使用 '\\' 以避免出现任何问题。
现在,启动 Postgres 服务。
第 1 步(Linux):
请按照以下代码中规定的程序进行操作:
$ mkdir db_archive
$ sudo chown postgres:postgres db_archive现在,我们创建了一个目录,我们将在其中写入档案。此外,我们已授予 Postgres 用户写入此目录的权限。我们必须在postgresql.conf文件中配置我们的参数。手动在数据目录或您安装的 PostgreSQL 版本的主目录中找到该文件。然后对文件进行以下更改(打开文件并编辑其内容):
# uncomment archive parameter and set it to the following:
archive_mode = on
archive_command = 'test ! -f /path/to/db_archive/%f && cp %p /path/to/db_archive/%f'
# change wal_level as well
wal_level = replica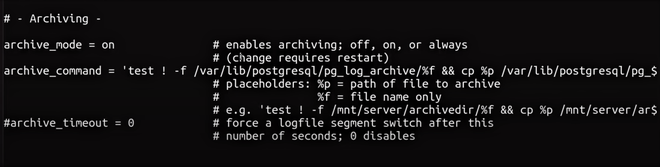
启用归档后的 PostgreSQL.conf 文件
保存并退出文件。您现在必须重新启动数据库服务器才能将这些更改应用到设置中。与此等效的 Linux 是:
$ sudo systemctl restart postgresql.service步骤 2 – 4(两个平台通用):
在您的系统上打开 SQL 提示符或 SQL Shell (psql)。连接到服务器。现在执行以下查询以进行备份。
postgres=# SELECT pg_start_backup('label',false,false)
postgres=# pg_basebackup -Ft -D directory_you_wish_to_backup_to
postgres=# SELECT pg_stop_backup(true,false)pg_start_backup()和pg_stop_backup()可以省略,因为pg_basebackup()能够自行处理控制。返回提示后,用户可以检查创建备份的目录,并放心找到.tar备份文件。由用户指定首选的文件格式类型(p 或 t 或 c)。
现在我们有了文件系统级备份和 WAL 档案,我们可以执行时间点恢复。让我们假设我们的数据库崩溃了,因此我们的数据被破坏、损坏或破坏。
创建备份后停止数据库服务并删除数据目录中的所有数据,因为由于数据库崩溃而不再验证数据。
$ sudo systemctl stop postgres.services
$ or use the windows services panel (if you use Windows)这是可以处理连续存档的程度(我们只创建备份,尚未恢复)。然而,这个过程相当简单和直接,因为我们需要做的就是将备份导入回原始文件夹或 PostgreSQL 在安装时最初使用的默认文件夹/目录。接下来是postgresql.conf文件中的一个小改动,这就是它的全部内容!