特征编码技术——机器学习
众所周知,更好的编码会带来更好的模型,并且大多数算法无法处理分类变量,除非将它们转换为数值。
分类特征一般分为3类:
- 二进制:非此即彼
例子:- 是的,没有
- 真假
- 序数:特定的有序组。
例子:- 低中高
- 冷,热,熔岩热
- 标称:无序组。
例子- 猫、狗、老虎
- 比萨,汉堡,可乐
数据集:要下载文件,请单击链接。
编码数据集
代码:
Python3
# data preprocessing
import pandas as pd
# for linear calculations
import numpy as np
# Plotting Graphs
import seaborn as sns
df = pd.read_csv("Encoding Data.csv")
# displaying top 10 results
df.head(10)Python3
# you can always use simple mapping on binary features.
df['bin_1'] = df['bin_1'].apply(lambda x: 1 if x =='T' else (0 if x =='F' else None))
df['bin_2'] = df['bin_2'].apply(lambda x: 1 if x =='Y' else (0 if x =='N' else None))
sns.countplot(df['bin_1'])
sns.countplot(df['bin_2'])Python3
# labelEncoder present in scikitlearn library
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['ord_2'] = le.fit_transform(df['ord_2'])
sns.set(style ="darkgrid")
sns.countplot(df['ord_2'])Python3
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
# transforming the column after fitting
enc = enc.fit_transform(df[['nom_0']]).toarray()
# converting arrays to a dataframe
encoded_colm = pd.DataFrame(enc)
# concatenating dataframes
df = pd.concat([df, encoded_colm], axis = 1)
# removing the encoded column.
df = df.drop(['nom_0'], axis = 1)
df.head(10)Python3
df = pd.get_dummies(df, prefix = ['nom_0'], columns = ['nom_0'])
df.head(10)Python3
# grouping by frequency
fq = df.groupby('nom_0').size()/len(df)
# mapping values to dataframe
df.loc[:, "{}_freq_encode".format('nom_0')] = df['nom_0'].map(fq)
# drop original column.
df = df.drop(['nom_0'], axis = 1)
fq.plot.bar(stacked = True)
df.head(10)Python3
from sklearn.preprocessing import OrdinalEncoder
ord1 = OrdinalEncoder()
# fitting encoder
ord1.fit([df['ord_2']])
# transforming the column after fitting
df["ord_2"]= ord1.fit_transform(df[["ord_2"]])
df.head(10)Python3
# creating a dictionary
temp_dict ={'Cold':1, 'Warm':2, 'Hot':3}
# mapping values in column from dictionary
df['Ord_2_encod']= df.ord_2.map(temp_dict)
df = df.drop(['ord_2'], axis = 1)
Output: Python3
from category_encoders import BinaryEncoder
encoder = BinaryEncoder(cols =['ord_2'])
# transforming the column after fitting
newdata = encoder.fit_transform(df['ord_2'])
# concatenating dataframe
df = pd.concat([df, newdata], axis = 1)
# dropping old column
df = df.drop(['ord_2'], axis = 1)
df.head(10)Python3
from sklearn.feature_extraction import FeatureHasher
# n_features contains the number of bits you want in your hash value.
h = FeatureHasher(n_features = 3, input_type ='string')
# transforming the column after fitting
hashed_Feature = h.fit_transform(df['nom_0'])
hashed_Feature = hashed_Feature.toarray()
df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1)
df.head(10)Python3
# inserting Target column in the dataset since it needs a target
df.insert(5, "Target", [0, 1, 1, 0, 0, 1, 0, 0, 0, 1], True)
# importing TargetEncoder
from category_encoders import TargetEncoder
Targetenc = TargetEncoder()
# transforming the column after fitting
values = Targetenc.fit_transform(X = df.nom_0, y = df.Target)
# concatenating values with dataframe
df = pd.concat([df, values], axis = 1)
df.head(10)输出:

数据集
让我们使用不同类型的编码技术检查数据集的列。
代码:映射数据集中存在的二进制特征。
Python3
# you can always use simple mapping on binary features.
df['bin_1'] = df['bin_1'].apply(lambda x: 1 if x =='T' else (0 if x =='F' else None))
df['bin_2'] = df['bin_2'].apply(lambda x: 1 if x =='Y' else (0 if x =='N' else None))
sns.countplot(df['bin_1'])
sns.countplot(df['bin_2'])
输出:
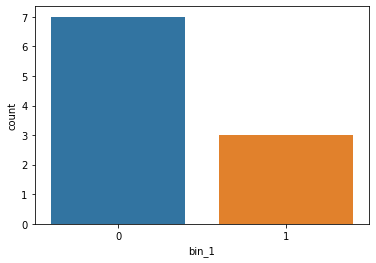
应用映射后的 Bin_1
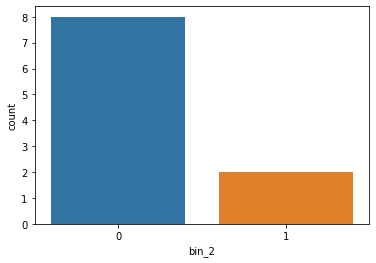
应用映射后的 bin_2
标签编码:标签编码算法非常简单,它考虑了编码的顺序,因此可用于对有序数据进行编码。
代码:
Python3
# labelEncoder present in scikitlearn library
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['ord_2'] = le.fit_transform(df['ord_2'])
sns.set(style ="darkgrid")
sns.countplot(df['ord_2'])
输出:

标签编码后的 ord_2 图
One-Hot Encoding:克服标签编码的缺点,因为它考虑了列中的一些层次结构,这可能会误导数据中存在的名义特征。我们可以使用 One-Hot Encoding 策略。
One-hot 编码分两步处理:
- 将类别拆分到不同的列。
- 将“0”表示其他人,将“1”作为相应列的指示符。
代码:使用 Sklearn 库的 One-Hot 编码
Python3
from sklearn.preprocessing import OneHotEncoder
enc = OneHotEncoder()
# transforming the column after fitting
enc = enc.fit_transform(df[['nom_0']]).toarray()
# converting arrays to a dataframe
encoded_colm = pd.DataFrame(enc)
# concatenating dataframes
df = pd.concat([df, encoded_colm], axis = 1)
# removing the encoded column.
df = df.drop(['nom_0'], axis = 1)
df.head(10)
输出:

输出
代码:使用 pandas 的 One-Hot 编码
Python3
df = pd.get_dummies(df, prefix = ['nom_0'], columns = ['nom_0'])
df.head(10)
输出:

输出
这种方法更可取,因为它提供了良好的标签。
注意: One-hot 编码方法消除了顺序,但它会导致列数大大增加。因此,对于具有更多唯一值的列,请尝试使用其他技术。
频率编码:我们还可以考虑频率分布进行编码。这种方法有时对标称特征有效。
代码:
Python3
# grouping by frequency
fq = df.groupby('nom_0').size()/len(df)
# mapping values to dataframe
df.loc[:, "{}_freq_encode".format('nom_0')] = df['nom_0'].map(fq)
# drop original column.
df = df.drop(['nom_0'], axis = 1)
fq.plot.bar(stacked = True)
df.head(10)
输出:
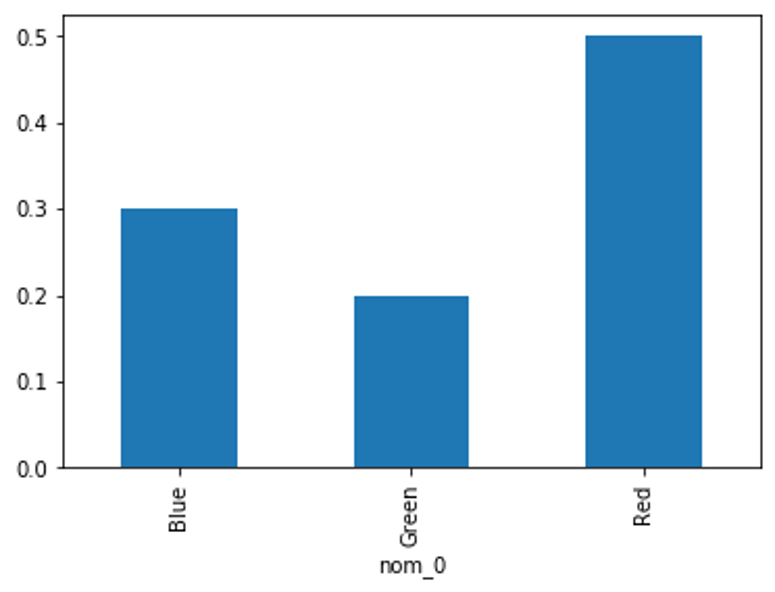
频率分布 (fq)

输出
Ordinal Encoding:我们可以使用 Scikit learn 类中提供的 Ordinal Encoding 对 Ordinal 特征进行编码。它确保变量的序数性质得以维持。
代码:使用 Scikit 学习。
Python3
from sklearn.preprocessing import OrdinalEncoder
ord1 = OrdinalEncoder()
# fitting encoder
ord1.fit([df['ord_2']])
# transforming the column after fitting
df["ord_2"]= ord1.fit_transform(df[["ord_2"]])
df.head(10)
输出:

输出
代码:使用字典手动分配排名
Python3
# creating a dictionary
temp_dict ={'Cold':1, 'Warm':2, 'Hot':3}
# mapping values in column from dictionary
df['Ord_2_encod']= df.ord_2.map(temp_dict)
df = df.drop(['ord_2'], axis = 1)
Output:
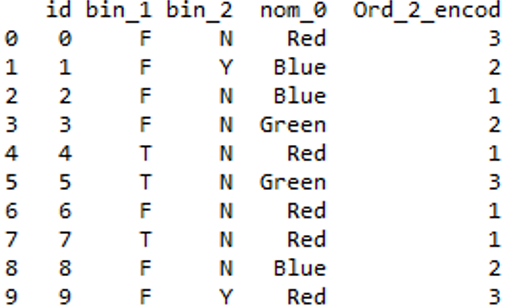
输出
二进制编码:
最初类别被编码为整数,然后转换为二进制代码,然后来自该二进制字符串的数字被放置到单独的列中。
例如:对于 7 : 1 1 1
当类别数量更多时,这种方法是非常可取的。想象一下,如果你有 100 个不同的类别。一种热编码将创建 100 个不同的列,但二进制编码只需要 7 个列。
代码:
Python3
from category_encoders import BinaryEncoder
encoder = BinaryEncoder(cols =['ord_2'])
# transforming the column after fitting
newdata = encoder.fit_transform(df['ord_2'])
# concatenating dataframe
df = pd.concat([df, newdata], axis = 1)
# dropping old column
df = df.drop(['ord_2'], axis = 1)
df.head(10)
输出:
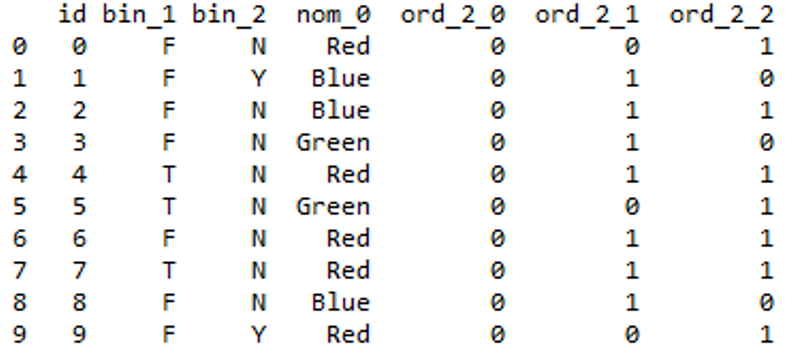
输出
HashEncoding:散列是通过应用散列函数字符字符串转换为唯一散列值的过程。这个过程非常有用,因为它可以处理更多的分类数据并且它的内存使用率很低。
关于散列的文章
代码:
Python3
from sklearn.feature_extraction import FeatureHasher
# n_features contains the number of bits you want in your hash value.
h = FeatureHasher(n_features = 3, input_type ='string')
# transforming the column after fitting
hashed_Feature = h.fit_transform(df['nom_0'])
hashed_Feature = hashed_Feature.toarray()
df = pd.concat([df, pd.DataFrame(hashed_Feature)], axis = 1)
df.head(10)
输出:

输出
您可以进一步从 Dataframe 中删除转换后的特征。
均值/目标编码:目标编码很好,因为它选择了可以解释目标的值。大多数kagglers在他们的比赛中使用它。用目标变量的平均值替换分类值的基本思想。
代码:
Python3
# inserting Target column in the dataset since it needs a target
df.insert(5, "Target", [0, 1, 1, 0, 0, 1, 0, 0, 0, 1], True)
# importing TargetEncoder
from category_encoders import TargetEncoder
Targetenc = TargetEncoder()
# transforming the column after fitting
values = Targetenc.fit_transform(X = df.nom_0, y = df.Target)
# concatenating values with dataframe
df = pd.concat([df, values], axis = 1)
df.head(10)
您可以进一步从 Dataframe 中删除转换后的特征。
输出:

输出