Pandas – 合并两个具有不同列的数据框
Pandas支持三种数据结构。它们是系列、数据框和面板。数据框是一种二维数据结构,这里的数据以行和列的表格格式存储。我们可以通过多种方式创建数据框。
这里我们使用Python中的列表数据结构创建一个数据框。
Python3
# import required module
import pandas
# assig data
l=["vignan","it","sravan","subbarao"]
# create data frame
df = pandas.DataFrame(l)
# display dataframe
dfPython3
# importing pandas module
import pandas as pd
# dictionary with list object in
# values ie college details
details = {
'Name': ['Sravan', 'Sai', 'Mohan', 'Ishitha'],
'College': ['Vignan', 'Vignan', 'Vignan', 'Vignan'],
'Physics': [99, 76, 71, 93],
'Chemistry': [97, 67, 65, 89],
'Data Science': [93, 65, 65, 85]
}
# converting to dataframe using DataFrame()
df = pd.DataFrame(details)
# print data frame
dfPython3
# creating another data
details1 = {
'Name': ['Harsha', 'Saiteja', 'abhilash', 'harini'],
'College': ['vvit', 'vvit', 'vvit', 'vvit'],
'Physics': [69, 76, 51, 43],
'Chemistry': [67, 67, 55, 89],
'Maths': [73, 65, 61, 85]
}
# create dataframe
df1 = pd.DataFrame(details1)
# display dataframe
df1Python3
# concat dataframes
pd.concat([df, df1], axis=0, ignore_index=True)Python3
# concat when axis = 1
pd.concat([df, df1], axis=1, ignore_index=True)Python3
# Import pandas library
import pandas as pd
# initialize list of lists
data = [['sravan', 98.00], ['jyothika', 90.00], ['vijay', 79.34]]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns=['Name', 'Marks'])
# print dataframe.
dfPython3
# initialize list of lists
data1 = [['Haseen', 88.00, 5], ['ramya', 54.00, 5], ['haritha', 56.34, 4]]
# Create the pandas DataFrame
df1 = pd.DataFrame(
data1, columns=['Name', 'Marks', 'Total subjects registered'])
# print dataframe.
df1Python3
# concatenating data frame
pd.concat([df, df1], axis=0, ignore_index=True)输出:

在上面的示例中,我们创建了一个数据框。让我们合并具有不同列的两个数据框。可以使用concat()加入不同的列 方法。
Syntax: pandas.concat(objs: Union[Iterable[‘DataFrame’], Mapping[Label, ‘DataFrame’]], axis=’0′, join: str = “‘outer'”)
- DataFrame: It is dataframe name.
- Mapping: It refers to map the index and dataframe columns
- axis: 0 refers to the row axis and1 refers the column axis.
- join: Type of join.
注意:如果数据框列匹配。然后空值被 NaN 值替换。
循序渐进的方法:
- 打开 jupyter 笔记本
- 导入必要的模块
- 创建数据框
- 执行操作
- 分析结果。
以下是基于上述方法的一些示例:
示例 1
在这个例子中,我们将根据大学连接学生的分数。
蟒蛇3
# importing pandas module
import pandas as pd
# dictionary with list object in
# values ie college details
details = {
'Name': ['Sravan', 'Sai', 'Mohan', 'Ishitha'],
'College': ['Vignan', 'Vignan', 'Vignan', 'Vignan'],
'Physics': [99, 76, 71, 93],
'Chemistry': [97, 67, 65, 89],
'Data Science': [93, 65, 65, 85]
}
# converting to dataframe using DataFrame()
df = pd.DataFrame(details)
# print data frame
df
输出:

蟒蛇3
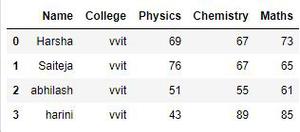
# creating another data
details1 = {
'Name': ['Harsha', 'Saiteja', 'abhilash', 'harini'],
'College': ['vvit', 'vvit', 'vvit', 'vvit'],
'Physics': [69, 76, 51, 43],
'Chemistry': [67, 67, 55, 89],
'Maths': [73, 65, 61, 85]
}
# create dataframe
df1 = pd.DataFrame(details1)
# display dataframe
df1
输出:
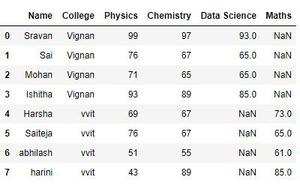
蟒蛇3
# concat dataframes
pd.concat([df, df1], axis=0, ignore_index=True)
蟒蛇3
# concat when axis = 1
pd.concat([df, df1], axis=1, ignore_index=True)

示例 2:
存储标记和主题详细信息
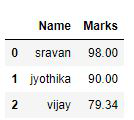
蟒蛇3
# Import pandas library
import pandas as pd
# initialize list of lists
data = [['sravan', 98.00], ['jyothika', 90.00], ['vijay', 79.34]]
# Create the pandas DataFrame
df = pd.DataFrame(data, columns=['Name', 'Marks'])
# print dataframe.
df
输出:
蟒蛇3
# initialize list of lists
data1 = [['Haseen', 88.00, 5], ['ramya', 54.00, 5], ['haritha', 56.34, 4]]
# Create the pandas DataFrame
df1 = pd.DataFrame(
data1, columns=['Name', 'Marks', 'Total subjects registered'])
# print dataframe.
df1
输出:

蟒蛇3
# concatenating data frame
pd.concat([df, df1], axis=0, ignore_index=True)
输出:
