获取 Pandas 中列的数据类型 - Python
让我们看看如何获取pandas dataframe中列的数据类型。首先,让我们创建一个 pandas 数据框。
例子:
Python3
# importing pandas library
import pandas as pd
# List of Tuples
employees = [
('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# show the dataframe
dfPython3
# importing pandas library
import pandas as pd
# List of Tuples
employees = [
('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Use Dataframe.dtypes to
# give the series of
# data types as result
datatypes = df.dtypes
# Print the data types
# of each column
datatypesPython3
#importing pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Use Dataframe.dtypes to give
# data type of 'Salary' as result
datatypes = df.dtypes['Salary']
# Print the data types
# of single column
datatypesPython3
# importing pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Print complete details
# about the data frame
df.info()输出:
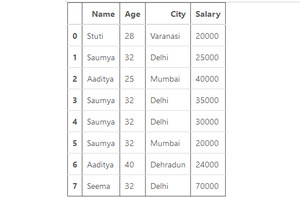
数据框
方法一:使用Dataframe.dtypes 属性。
此属性返回具有每列数据类型的 Series。
Syntax: DataFrame.dtypes.
Parameter: None.
Returns: dtype of each column.
示例 1:获取 Dataframe 的所有列的数据类型。
Python3
# importing pandas library
import pandas as pd
# List of Tuples
employees = [
('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Use Dataframe.dtypes to
# give the series of
# data types as result
datatypes = df.dtypes
# Print the data types
# of each column
datatypes
输出:

数据框的数据类型
示例 2:获取 Dataframe 中单列的数据类型。
Python3
#importing pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Use Dataframe.dtypes to give
# data type of 'Salary' as result
datatypes = df.dtypes['Salary']
# Print the data types
# of single column
datatypes
输出:

单列的数据类型
方法 2:使用Dataframe.info()方法。
此方法用于获取数据框的简明摘要,例如:
- 列名
- 列的数据类型
- 数据框中的行
- 每列中的非空条目
- 它还将打印列数、名称和数据类型。
Syntax: DataFrame.info(verbose=None, buf=None, max_cols=None, memory_usage=None, null_counts=None)
Return: None and prints a summary of a DataFrame.
示例:获取 Dataframe 的所有列的数据类型。
Python3
# importing pandas library
import pandas as pd
# List of Tuples
employees = [('Stuti', 28, 'Varanasi', 20000),
('Saumya', 32, 'Delhi', 25000),
('Aaditya', 25, 'Mumbai', 40000),
('Saumya', 32, 'Delhi', 35000),
('Saumya', 32, 'Delhi', 30000),
('Saumya', 32, 'Mumbai', 20000),
('Aaditya', 40, 'Dehradun', 24000),
('Seema', 32, 'Delhi', 70000)
]
# Create a DataFrame
df = pd.DataFrame(employees,
columns = ['Name', 'Age',
'City', 'Salary'])
# Print complete details
# about the data frame
df.info()
输出:

数据框摘要,包括数据类型