论文下载链接:论文|第二学期| 2016-17
时间: 3小时
总分数:100
注意:-
- 共分为三个部分。 A节为20分, B节为30分, C节为50分。
- 尝试所有问题。每个问题都带有标记。
- 必要时假定合适的数据。
尝试以下两个问题中的任何一个:(2 * 15 = 30)
3)用语法定义结构。另外,编写一个比较两个给定日期的程序。要存储日期使用结构,请说包含三个成员的日期,即日期,月份和年份。如果日期相等,则显示消息为“等于”,否则显示为“不相等”。
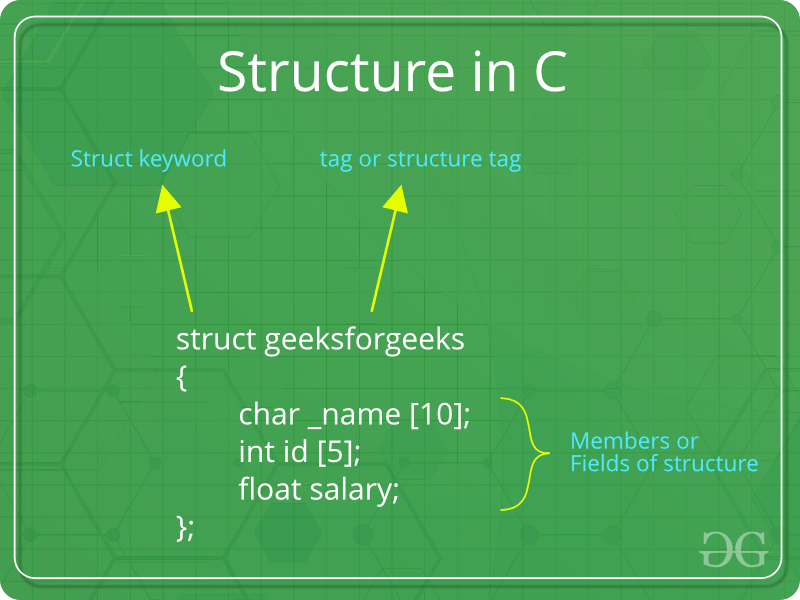
如何建立结构?
‘struct’关键字用于创建结构。以下是一个示例。
struct address {
char name[50];
char street[100];
char city[50];
char state[20];
int pin;
};
如何声明结构变量?
结构变量既可以用结构声明来声明,也可以像基本类型一样声明为单独的声明。
// A variable declaration with structure declaration.
struct Point {
int x, y;
} p1; // The variable p1 is declared with 'Point'
// A variable declaration like basic data types
struct Point {
int x, y;
};
int main()
{
struct Point p1; // The variable p1 is declared like a normal variable
}
注意:在C++中,在声明变量之前,struct关键字是可选的。在C语言中,它是强制性的。
比较两个给定日期的程序:
#include
// Declaring the structure of Date
struct Date {
int date;
int month;
int year;
};
// Driver code
int main()
{
int date1, date2, month1,
month2, year1, year2;
// Get the first date
scanf("%d", &date1);
printf("Enter the first date: %d", date1);
scanf("%d", &month1);
printf("\nEnter the first month: %d", month1);
scanf("%d", &year1);
printf("\nEnter the first year: %d", year1);
// Initialise the structure with first date
struct Date Date1 = { date1, month1, year1 };
// Get the second date
scanf("%d", &date2);
printf("\nEnter the second date: %d", date2);
scanf("%d", &month2);
printf("\nEnter the second month: %d", month2);
scanf("%d", &year2);
printf("\nEnter the second year: %d", year2);
// Initialise the structure with first date
struct Date Date2 = { date2, month2, year2 };
printf("\nThe given dates are: ");
// Comparing the Dates
if (Date1.date == Date2.date
&& Date1.month == Date2.month
&& Date1.year == Date2.year) {
printf("Equal");
}
else {
printf("Unequal");
}
return 0;
}
输出:
Enter the first date: 10
Enter the first month: 11
Enter the first year: 2018
Enter the second date: 10
Enter the second month: 11
Enter the second year: 2018
The given dates are: Equal
4在以下内容上写上简短的注释(任意两个):
主要在堆栈中执行以下三个基本操作:
- 推送:在堆栈中添加一个项目。如果堆栈已满,则称其为溢出条件。
- 弹出:从堆栈中删除一个项目。这些项目以推入的相反顺序弹出。如果堆栈为空,则称其为下溢条件。
- 窥视或顶部:返回堆栈的顶部元素。
- isEmpty:如果堆栈为空,则返回true,否则返回false。
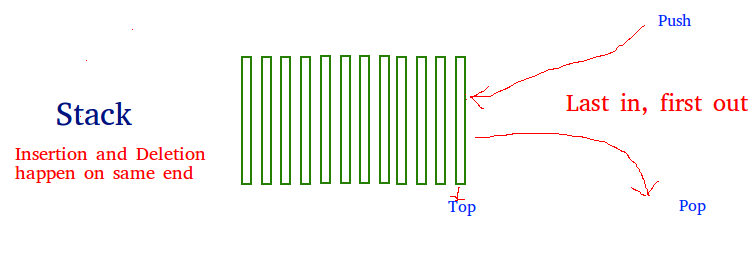
如何实际理解堆栈?
有许多现实生活中的堆栈示例。考虑一下在食堂中相互堆叠的盘子的简单示例。位于顶部的板是第一个要卸下的板,即,已放置在最底部位置的板在堆栈中保留的时间最长。因此,可以简单地看出它遵循LIFO / FILO命令。
堆栈上操作的时间复杂度:
push(),pop(),isEmpty()和peek()都花费O(1)的时间。在任何这些操作中,我们都不会运行任何循环。
堆栈的应用:
- 符号平衡
- 后缀/前缀转换的中缀
- 在许多地方都可以重做-撤消功能,例如编辑器,photoshop。
- Web浏览器中的前进和后退功能
- 用于许多算法,例如河内塔,树木遍历,股票跨度问题,直方图问题。
- 其他应用程序可以是回溯,骑士之旅问题,迷宫中的老鼠,N皇后问题和数独求解器
- 在图算法中,例如拓扑排序和强连接的组件
执行:
有两种方法可以实现堆栈:
- 使用数组
- 使用链表
使用数组实现堆栈
// C program for array implementation of stack
#include
#include
#include
// A structure to represent a stack
struct Stack {
int top;
unsigned capacity;
int* array;
};
// function to create a stack of given capacity. It initializes size of
// stack as 0
struct Stack* createStack(unsigned capacity)
{
struct Stack* stack = (struct Stack*)malloc(sizeof(struct Stack));
stack->capacity = capacity;
stack->top = -1;
stack->array = (int*)malloc(stack->capacity * sizeof(int));
return stack;
}
// Stack is full when top is equal to the last index
int isFull(struct Stack* stack)
{
return stack->top == stack->capacity - 1;
}
// Stack is empty when top is equal to -1
int isEmpty(struct Stack* stack)
{
return stack->top == -1;
}
// Function to add an item to stack. It increases top by 1
void push(struct Stack* stack, int item)
{
if (isFull(stack))
return;
stack->array[++stack->top] = item;
printf("%d pushed to stack\n", item);
}
// Function to remove an item from stack. It decreases top by 1
int pop(struct Stack* stack)
{
if (isEmpty(stack))
return INT_MIN;
return stack->array[stack->top--];
}
// Driver program to test above functions
int main()
{
struct Stack* stack = createStack(100);
push(stack, 10);
push(stack, 20);
push(stack, 30);
printf("%d popped from stack\n", pop(stack));
return 0;
}
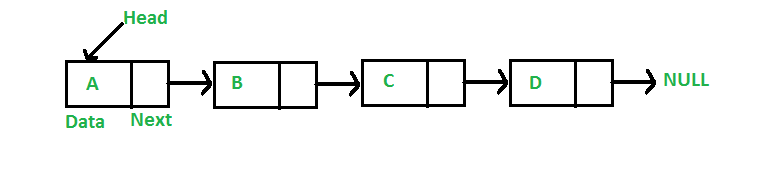
为什么要链接列表?
数组可用于存储相似类型的线性数据,但是数组具有以下限制。
1)数组的大小是固定的:因此,我们必须提前知道元素数量的上限。而且,通常,所分配的存储器与用途无关而等于上限。
2)在元素数组中插入新元素非常昂贵,因为必须为新元素创建空间,并且要创建空间,必须移动现有元素。
例如,在系统中,如果我们在ID []数组中维护ID的排序列表。
id [] = [1000,1010,1050,2000,2040]。
如果要插入新的ID 1005,则要保持排序顺序,我们必须将所有元素都移到1000(不包括1000)之后。
除非使用某些特殊技术,否则删除数组也很昂贵。例如,要删除id []中的1010,必须移动1010之后的所有内容。
相对于阵列的优势
1)动态尺寸
2)易于插入/删除
缺点:
1)不允许随机访问。我们必须从第一个节点开始顺序访问元素。因此,我们无法使用其默认实现对链接列表进行有效的二进制搜索。在这里阅读。
2)列表的每个元素都需要用于指针的额外存储空间。
3)不适合缓存。由于数组元素是连续的位置,因此存在引用位置,而在链接列表的情况下则不存在。
表示:
链接列表由指向链接列表的第一个节点的指针表示。第一个节点称为头。如果链表为空,则head的值为NULL。
列表中的每个节点至少由两部分组成:
1)资料
2)指向下一个节点的指针(或引用)
在C语言中,我们可以使用结构表示节点。下面是一个带有整数数据的链表节点的示例。
// A linked list node
struct Node {
int data;
struct Node* next;
};
int main() { /* ... */ }
我们还可以在C和C++中提供命令行参数。在操作系统的命令行外壳程序中,在程序名称之后给出命令行参数。
为了传递命令行参数,我们通常使用两个参数定义main():第一个参数是命令行参数的数量,第二个是命令行参数的列表。
int main(int argc, char *argv[]) { /* ... */ }
或者
int main(int argc, char **argv) { /* ... */ }
- argc(ARGument Count)为int,存储用户传递的命令行参数数量,包括程序名称。因此,如果我们将值传递给程序,则argc的值为2(一个用于参数,一个用于程序名称)
- argc的值应为非负数。
- argv(ARGument Vector)是列出所有参数的字符指针数组。
- 如果argc大于零,则从argv [0]到argv [argc-1]的数组元素将包含指向字符串的指针。
- Argv [0]是程序的名称,之后,直到argv [argc-1]为止,每个元素都是命令行参数。
5. C中有哪些不同的文件打开模式。假设一个文件包含学生的记录,而每个记录都包含一个学生的姓名和年龄。编写一个C程序来读取这些记录,并按名称按顺序显示它们。
- “ r” –搜索文件。如果文件成功打开,则fopen()将其加载到内存中并设置一个指向其中第一个字符的指针。如果无法打开文件,则fopen()返回NULL。
- “ w” –搜索文件。如果文件存在,其内容将被覆盖。如果该文件不存在,则会创建一个新文件。如果无法打开文件,则返回NULL。
- “ a” –搜索文件。如果文件成功打开,则fopen()将其加载到内存中并设置一个指向文件中最后一个字符的指针。如果该文件不存在,则会创建一个新文件。如果无法打开文件,则返回NULL。
- “ r +” –搜索文件。如果成功打开,则fopen()将其加载到内存中并设置一个指向其中第一个字符的指针。如果无法打开文件,则返回NULL。
- “ w +” –搜索文件。如果文件存在,其内容将被覆盖。如果该文件不存在,则会创建一个新文件。如果无法打开文件,则返回NULL。
- “ a +” –搜索文件。如果文件成功打开,则fopen()将其加载到内存中并设置一个指向文件中最后一个字符的指针。如果该文件不存在,则会创建一个新文件。如果无法打开文件,则返回NULL。
C程序读取这些记录并按名称将其显示在排序的顺序中:
// C program to read Student records
// like id, name and age,
// and display them in sorted order by Name
#include
#include
#include
// struct person with 3 fields
struct Student {
char* name;
int id;
char age;
};
// setting up rules for comparison
// to sort the students based on names
int comparator(const void* p, const void* q)
{
return strcmp(((struct Student*)p)->name,
((struct Student*)q)->name);
}
// Driver program
int main()
{
int i = 0, n = 5;
struct Student arr[n];
// Get the students data
arr[0].id = 1;
arr[0].name = "bd";
arr[0].age = 12;
arr[1].id = 2;
arr[1].name = "ba";
arr[1].age = 10;
arr[2].id = 3;
arr[2].name = "bc";
arr[2].age = 8;
arr[3].id = 4;
arr[3].name = "aaz";
arr[3].age = 9;
arr[4].id = 5;
arr[4].name = "az";
arr[4].age = 10;
// Print the Unsorted Structure
printf("Unsorted Student Records:\n");
for (i = 0; i < n; i++) {
printf("Id = %d, Name = %s, Age = %d \n",
arr[i].id, arr[i].name, arr[i].age);
}
// Sort the structure
// based on the specified comparator
qsort(arr, n, sizeof(struct Student), comparator);
// Print the Sorted Structure
printf("\n\nStudent Records sorted by Name:\n");
for (i = 0; i < n; i++) {
printf("Id = %d, Name = %s, Age = %d \n",
arr[i].id, arr[i].name, arr[i].age);
}
return 0;
}
输出:
Unsorted Student Records:
Id = 1, Name = bd, Age = 12
Id = 2, Name = ba, Age = 10
Id = 3, Name = bc, Age = 8
Id = 4, Name = aaz, Age = 9
Id = 5, Name = az, Age = 10
Student Records sorted by Name:
Id = 4, Name = aaz, Age = 9
Id = 5, Name = az, Age = 10
Id = 2, Name = ba, Age = 10
Id = 3, Name = bc, Age = 8
Id = 1, Name = bd, Age = 12