使用Python编辑 PDF
因此,让我们从“编辑”的确切含义开始。因此,编校是一种编辑形式,其中将多个文本源组合并稍作修改以制作单个文档。简而言之,每当您看到任何文档中的任何部分被涂黑以隐藏某些信息时,它就被称为编辑。对 PDF 执行相同的任务称为PDF 编辑。
如果有人在 PDF 上使用过任何类型的数据提取,那么他们就会知道处理 PDF 是多么痛苦。考虑一个场景,您想与某人共享 PDF,但 PDF 中的某些部分您不想被泄露。所以,你可以做的是,你可以编辑文本。使用 Adobe Acrobat 之类的工具编辑文本非常容易,但如果您希望这是一个自动化的过程怎么办。假设您在一家公司工作,该公司与所得税部门共享其用户在其网站上的购买,但由于严格的隐私政策,他们希望从交易收据中删除用户个人身份信息 (PII)的安全性。如果用户群很大,则无法手动完成,因此您需要某种自动化来完成。这就是Python的用武之地。有一个名为PyMuPDF的神奇库,它是一个用于处理 pdf 并对其执行各种操作的库。所以,让我们看看我们将如何做到这一点。
首先,您需要安装 Python3 和 PyMuPDF。要安装 PyMuPDF,只需打开终端并在其中输入以下内容
pip3 install PyMuPDF对于此演示,我们将仅编辑 PDF 中的电子邮件 ID。您可以将相同的逻辑应用于任何其他 PII
方法:
- 阅读 PDF 文件
- 逐行遍历 pdf 并查找每次出现的任何电子邮件 ID。电子邮件 ID 有一个模式,因此我们将使用正则表达式来识别电子邮件
- 一旦我们遇到一封电子邮件,我们将其添加到一个列表中,然后在最后一行的末尾返回该列表
- 现在,我们需要简单地搜索 pdf 中获取的电子邮件 ID 的出现。 PyMuPDF 使查找 PDF 中的任何文本变得非常容易。它返回将出现文本的矩形的四个坐标。
- 一旦我们有了所有的文本框,我们就可以简单地遍历这些框并从 PDF 中编辑每个框
下面是上述方法的实现,我添加了内联注释以便更好地理解代码。
使用的PDF文件:
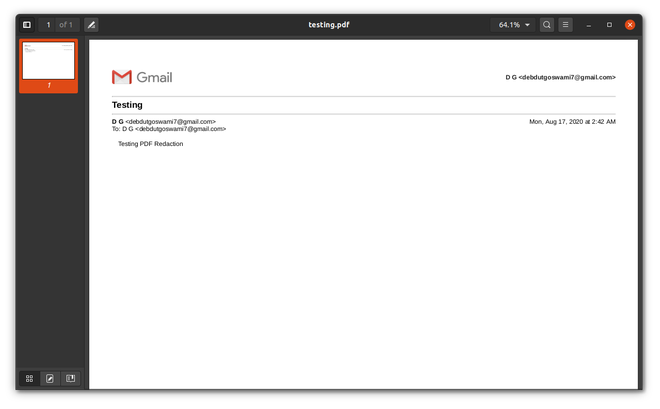
前
Python3
# imports
import fitz
import re
class Redactor:
# static methods work independent of class object
@staticmethod
def get_sensitive_data(lines):
""" Function to get all the lines """
# email regex
EMAIL_REG = r"([\w\.\d]+\@[\w\d]+\.[\w\d]+)"
for line in lines:
# matching the regex to each line
if re.search(EMAIL_REG, line, re.IGNORECASE):
search = re.search(EMAIL_REG, line, re.IGNORECASE)
# yields creates a generator
# generator is used to return
# values in between function iterations
yield search.group(1)
# constructor
def __init__(self, path):
self.path = path
def redaction(self):
""" main redactor code """
# opening the pdf
doc = fitz.open(self.path)
# iterating through pages
for page in doc:
# _wrapContents is needed for fixing
# alignment issues with rect boxes in some
# cases where there is alignment issue
page._wrapContents()
# getting the rect boxes which consists the matching email regex
sensitive = self.get_sensitive_data(page.getText("text")
.split('\n'))
for data in sensitive:
areas = page.searchFor(data)
# drawing outline over sensitive datas
[page.addRedactAnnot(area, fill = (0, 0, 0)) for area in areas]
# applying the redaction
page.apply_redactions()
# saving it to a new pdf
doc.save('redacted.pdf')
print("Successfully redacted")
# driver code for testing
if __name__ == "__main__":
# replace it with name of the pdf file
path = 'testing.pdf'
redactor = Redactor(path)
redactor.redaction()输出:
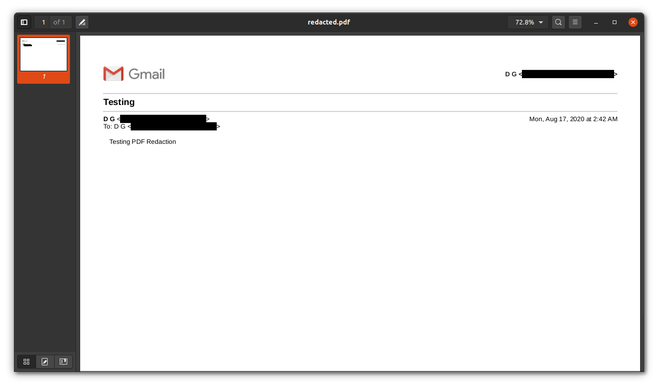
后