在本文中,我们将讨论Apache Spark的入门部分,以及spark的历史以及为何spark重要。让我们一一讨论。
根据Databrick的定义,“ Apache Spark是一个闪电般的统一分析引擎,适用于大数据和机器学习。它最初是2009年在加州大学伯克利分校开发的。”
Databricks是包括Yahoo!在内的Spark的主要贡献者之一。英特尔等。Apache spark是用于数据处理的最大的开源项目之一。它是一种快速的内存数据处理引擎。

火花的历史:
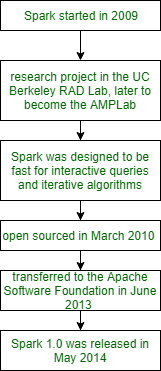
Spark于2009年在加州大学伯克利分校的研发实验室开始,该实验室现在称为AMPLab。然后在2010年,Spark在BSD许可下成为开源。此后,Spark于2013年6月转移到ASF(Apache软件基金会)。Spark研究人员以前从事Hadoop map-reduce的工作。在加州大学伯克利分校的研发实验室中,他们观察到这对于迭代和交互式计算工作效率低下。在Spark中,它支持内存中存储和高效的故障恢复,Spark的设计旨在快速进行交互式查询和迭代算法。在下面给出的图中,我们将描述Spark的历史。我们来看一下。
Spark的特点:
- Apache Spark可用于执行批处理。
- Apache Spark还可以用于执行流处理。对于流处理,我们使用的是Apache Storm / S4。
- 它可以用于交互处理。以前,我们使用Apache Impala或Apache Tez进行交互处理。
- Spark对执行图形处理也很有用。 Neo4j / Apache Graph用于图形处理。
- Spark可以实时和批处理模式处理数据。
因此,可以说Spark是用于数据处理的功能强大的开源引擎。
参考 :
Apache Spark参考