1.分层数据模型:
分层数据模型是最早的数据模型类型。它由IBM在1968年开发。它以树状结构组织数据。层次模型包括以下内容:
- 它包含通过分支连接的节点。
- 最顶层的节点称为根节点。
- 如果在顶层出现多个节点,则可以将这些节点称为根段。
- 每个节点只有一个父节点。
- 一位父母可能有很多孩子。
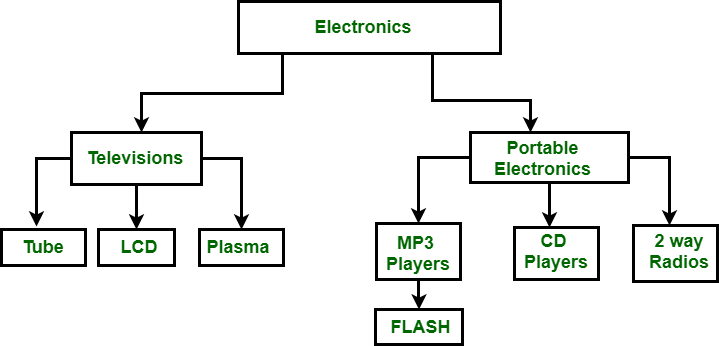
在上图中,“电子”是具有两个子级的根节点,即“电视”和“便携式电子”。这两个人还有更多的孩子,他们将其作为父母。
例如:电视有孩子,例如电子管,液晶显示器和等离子,这三台电视作为父级。它遵循一对多的关系。
2.网络数据模型:
它是分层数据模型的高级版本。为了组织数据,它使用有向图而不是树结构。这个孩子可以有一个以上的父母。它使用两个数据结构的概念,即记录和集合。
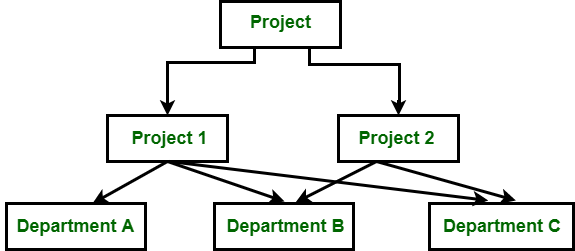
在上图中,项目是具有两个子节点的根节点,即项目1和项目2。项目1有3个孩子,项目2有2个孩子。共有5个孩子,即A部门,B部门和C部门,它们是与网络相关的孩子,因为我们说过这种模式可以有多个父母。因此,对于部门B和部门C有两个父母,即项目1和项目2。
分层数据模型与网络数据模型之间的区别:
| Hierarchical Data Model | Network Data Model |
|---|---|
| In this model, to store data hierarchy method is used. | In this model, you could create a network that shows how data is related to each other. |
| It implements 1:1 and 1:n relations. | It implements 1:1, 1:n and also many to many relations. |
| To organize records, it uses tree structure. | To organize records, it uses graphs. |
| Records are linked with the help of pointers. | Records are linked with the help of linked list. |
| Insertion anomaly exits in this model i.e. child node cannot be inserted without the parent node. | There is no insertion anomaly. |
| Deletion anomaly exists in this model i.e. it is difficult to delete the parent node. | There is no deletion anomaly. |
| It is used to access the data which is complex and asymmetric. | It is used to access the data which is complex and symmetric. |
| This model lacks data independence. | There is partial data independence in this model. |