在本文中,我们将讨论SQL的概述,并将主要关注概念和查询,并借助示例来理解它们。让我们一一讨论。
概述 :
SQL是一种计算机语言,用于以结构化格式存储,处理和检索数据。该语言是IBM发明的。 SQL在这里代表结构化查询语言。通过将数据库与SQL查询进行交互,我们可以处理大量数据。有几种SQL支持的数据库服务器,例如MySQL,PostgreSQL,sqlite3等。可以通过这些数据库服务器以安全且结构化的格式存储数据。 SQL查询通常用于更好地进行数据处理和业务洞察。
SQL数据库:
在这里,我们将讨论查询并在示例的帮助下进行理解。
查询1:
显示现有数据库–
让我们考虑一下现有的数据库,例如nformation_schema,mysql,performance_schema,sakila,student,sys和world。如果要显示现有数据库,则将使用show database查询,如下所示。
SHOW DATABASES; 输出 :
| Existing database Name |
|---|
| information_schema |
| mysql |
| performance_schema |
| sakila |
| student |
| sys |
| world |
查询2:
删除数据库–
假设我们要删除数据库,即student。
DROP DATABASE student;
SHOW DATABASES; | Database Name |
|---|
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
查询3:
创建数据库–
假设我们要创建一个数据库,即银行。
CREATE DATABASE bank;
SHOW DATABASES;| Database Name |
|---|
| bank |
| information_schema |
| mysql |
| performance_schema |
| sakila |
| sys |
| world |
查询4:
使用数据库–
USE bank;查询5:
创建表–
此处的数据类型可以是varchar,整数,日期等。
CREATE TABLE table_name (
column1 datatype,
column2 datatype,
....
);例子 –
CREATE TABLE IF NOT EXISTS Employee (
EmployeeID int,
FirstName varchar(55),
LastName varchar(55),
Email varchar(150),
DOB date
);查询6:
显示同一数据库中的表–
SHOW TABLES;查询7:
删除表格–
DROP TABLE table_name;查询8:
将值插入到现有表中–
INSERT INTO Employee
VALUES(1111,'Dipak','Bera','dipakbera@gmail.com','1994-11-22');查询9:
提取表中的值–
SELECT * FROM Employee;查询10:
不为空–
当我们在表中插入一个值(行)时,我们可以指定哪一列不接受空值。这将在创建表时完成。
CREATE TABLE table_name (
column1 datatype NOT NULL,
column2 datatype,
....
);查询11:
独特 –
我们还可以指定特定列中的条目应该唯一。
CREATE TABLE table_name (
column1 datatype UNIQUE,
column2 datatype,
....
);例子 –
CREATE TABLE demo_table
(
EmployeeID int NOT NULL UNIQUE,
FirstName varchar(55),
LastName varchar(55)
); SQL中的关键概念:
在这里,我们将讨论一些重要的概念,例如键,联接操作,具有子句,order by等。让我们一一讨论。
- 首要的关键 –
约束PRIMARY KEY建议对应于指定列的条目既不能为空,也不可以重复。
CREATE TABLE IF NOT EXISTS Customer(
CustID int NOT NULL,
FName varchar(55),
LName varchar(55),
Email varchar(100),
DOB date,
CONSTRAINT customer_custid_pk PRIMARY KEY(CustID)
);- 外键–
FOREIGN KEY用于在当前表和包含主键的上一个表之间建立连接。
CREATE TABLE Account(
AccNo int NOT NULL,
AType varchar(20),
OBal int,
OD date,
CurBal int,
CONSTRAINT customer_AccNo_fk FOREIGN KEY(AccNo) REFERENCES Customer(CustID)
);- 此处,“客户”表中的“帐户编号”列由“客户”表中的“ CustID”列引用。在这里,帐户表是子表,而客户表是父表。
订购依据:
这 ORDER BY关键字用于按升序或降序显示结果。默认情况下,它是按升序排列的。
句法 –
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;- 方案1:
假设我们的帐户表如下。
| AccNo | AType | OBal | OD | CurBal |
|---|---|---|---|---|
| 1111 | savings | 1000 | 1990-11-09 | 6000 |
| 1114 | current | 2000 | 1992-10-07 | 1000 |
| 1113 | current | 7000 | 1992-11-03 | 4000 |
| 1112 | savings | 1000 | 2003-12-12 | 3000 |
- 现在,我们将按以下方式使用Order By命令。
SELECT * FROM Account ORDER BY CurBal; 输出 :
(默认情况下,按升序排列)
| AccNo | AType | OBal | OD | CurBal |
|---|---|---|---|---|
| 1114 | current | 2000 | 1992-10-07 | 1000 |
| 1112 | savings | 1000 | 2003-12-12 | 3000 |
| 1113 | current | 7000 | 1992-11-03 | 4000 |
| 1111 | savings | 1000 | 1990-11-09 | 6000 |
- 方案2:
对于降序:
SELECT * FROM Account ORDER BY CurBal DESC;输出 :
| AccNo | AType | OBal | OD | CurBal |
|---|---|---|---|---|
| 1111 | savings | 1000 | 1990-11-09 | 6000 |
| 1113 | current | 7000 | 1992-11-03 | 4000 |
| 1112 | savings | 1000 | 2003-12-12 | 3000 |
| 1114 | current | 2000 | 1992-10-07 | 1000 |
通过…分组 :
此关键字用于对结果进行分组。
例子 –
SELECT COUNT(AType) FROM Account GROUP BY AType;输出 :
| AType | count(AType) |
|---|---|
| savings | 2 |
| current | 2 |
加盟概念:
在这里,我们将讨论联接概念,如下所示。
- 左加入:
LEFT JOIN关键字返回左表(表1)中的所有记录以及右表(表2)中的匹配记录。
句法 –
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;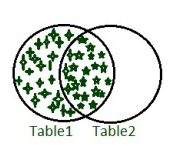
左联接
- 正确加入:
RIGHT JOIN关键字返回右表(table2)中的所有记录以及左表(table1)中的匹配记录。 - 句法 –
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;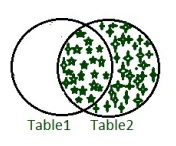
正确加入
- 内部联接 :
INNER JOIN关键字从两个表中返回所有匹配的记录。 - 句法 –
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;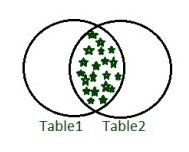
内部联接
- 完全加入:
FULL JOIN或FULL OUTER JOIN关键字返回两个表中的所有记录。 - 句法 –
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name = table2.column_name;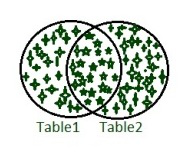
完全加入
- 笔记 –
MySQL的最新版本未使用此关键字。而是使用关键字UNION。这里的语法如下。
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;- 自我加入:
这是同一表的别名之间的常规联接。 - 句法 –
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;条款:
此子句用于过滤我们的数据。
句法 –
SELECT column1, column2, ...
FROM table_name
WHERE condition;例子 –
SELECT AccNo,CurBal FROM Account WHERE CurBal>=1000;输出 :
| AccNo | CurBal |
|---|---|
| 1111 | 6000 |
| 1113 | 4000 |
| 1114 | 1000 |
有条款:
这是必需的,因为WHERE子句不支持聚合函数,例如count,min,max,avg,sum等。
SELECT column1, column2, ...
FROM table_name
HAVING condition;例子 –
SELECT AccNo,CurBal FROM Account HAVING CurBal=MAX(CurBal);输出 :
| AccNo | CurBal |
|---|---|
| 1111 | 6000 |