Count-min 草图是一种概率数据结构。 Count-Min 草图是一种汇总大量频率数据的简单技术。 Count-min 草图算法谈到跟踪事物的数量。即,元素在集合中出现的次数。使用 HashTable 或 Map 在Java可以轻松实现查找项目的计数。
尝试使用 MultiSet 作为 Count-min 草图的替代方案
让我们尝试使用 MultiSet 和下面的源代码来实现这个数据结构,并尝试找出这种方法的问题。
// Java program to try MultiSet as an
// alternative to Count-min sketch
import com.google.common.collect.HashMultiset;
import com.google.common.collect.Multiset;
public class MultiSetDemo {
public static void main(String[] args)
{
Multiset blackListedIPs
= HashMultiset.create();
blackListedIPs.add("192.170.0.1");
blackListedIPs.add("75.245.10.1");
blackListedIPs.add("10.125.22.20");
blackListedIPs.add("192.170.0.1");
System.out.println(blackListedIPs
.count("192.170.0.1"));
System.out.println(blackListedIPs
.count("10.125.22.20"));
}
}
输出: 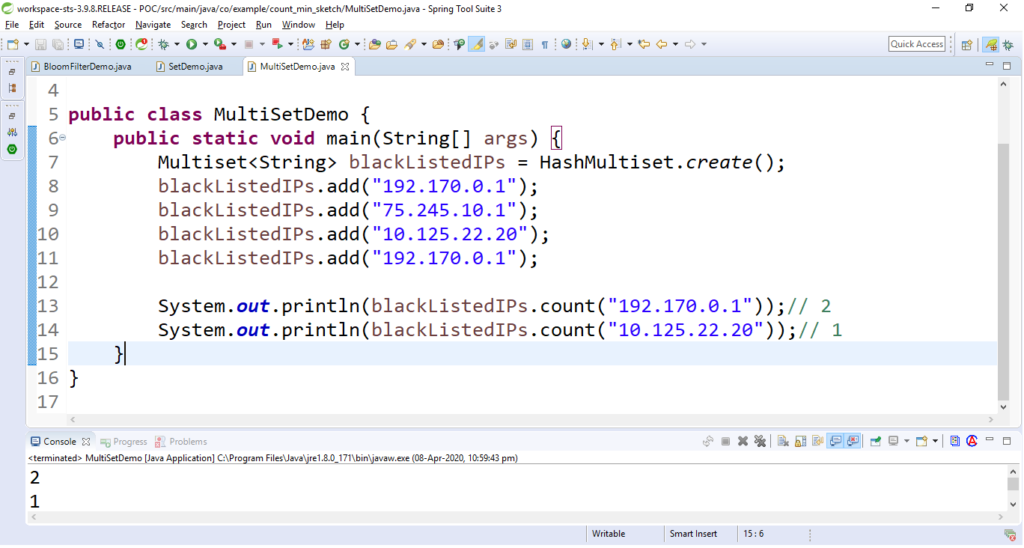
理解使用MultiSet的问题
现在让我们看看这种方法所消耗的时间和空间。
----------------------------------------------
|Number of UUIDs Insertion Time(ms) |
----------------------------------------------
|10 <25 |
|100 <25 |
|1, 000 30 |
|10, 000 257 |
|100, 000 1200 |
|1, 000, 000 4244 |
----------------------------------------------
我们来看看消耗的内存(空间):
----------------------------------------------
|Number of UUIDs JVM heap used(MB) |
----------------------------------------------
|10 <2 |
|100 <2 |
|1, 000 3 |
|10, 000 9 |
|100, 000 39 |
|1, 000, 000 234 |
-----------------------------------------------
我们可以很容易地理解,随着数据的增长,上述方法正在消耗大量的内存和时间来处理数据。如果我们使用count-min 草图算法,这可以优化。
什么是 Count-min 草图,它是如何工作的?
Count-min 草图方法是由Graham Cormode和S. Muthukrishnan提出的。在 2011/12 年发表的使用 count-min 草图近似数据的论文中。 Count-minsketch 用于计算流数据上事件的频率。与Bloom filter一样,Count-min 草图算法也适用于哈希码。它使用多个散列函数将这些频率映射到矩阵(考虑在此处绘制二维数组或矩阵)。
让我们一步一步地看下面的例子。
- 考虑下面有 4 行 16 列的二维数组,行数也等于散列函数的数量。这意味着我们在示例中采用了四个散列函数。用零初始化/标记矩阵中的每个单元格。
注意:您想要的结果越准确,要使用的哈希函数的数量就越多。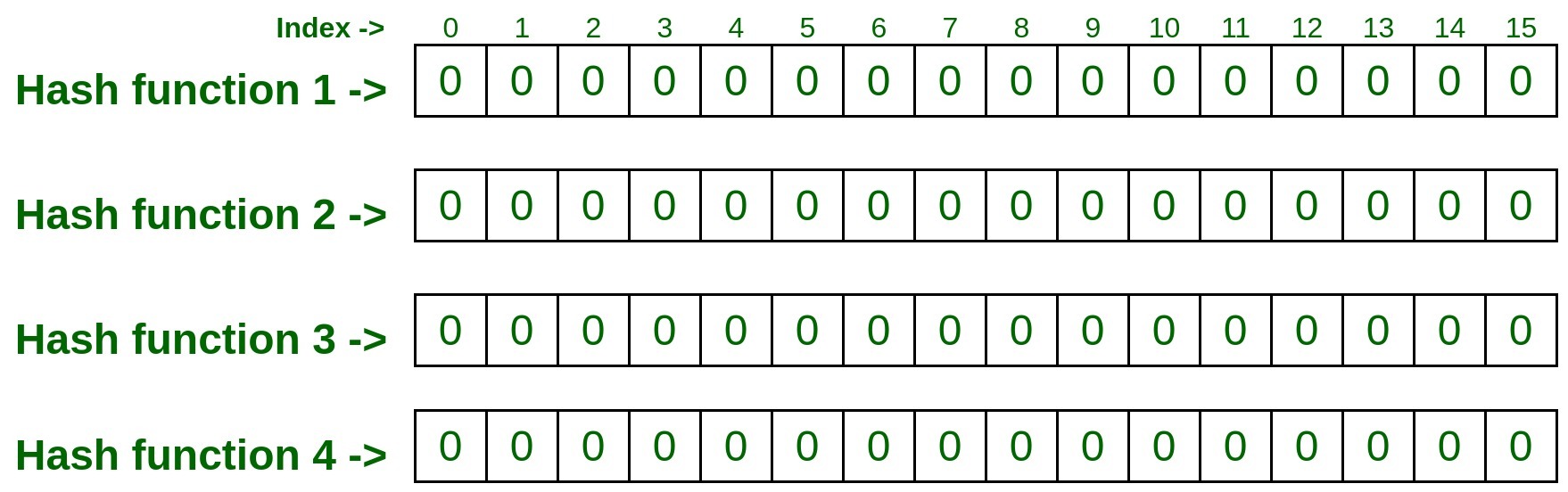
- 现在让我们向它添加一些元素。为此,我们必须使用所有四个散列函数传递该元素,这可能会产生如下结果。
Input : 192.170.0.1hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1现在访问上面所有四个哈希函数检索到的索引并将它们标记为 1。
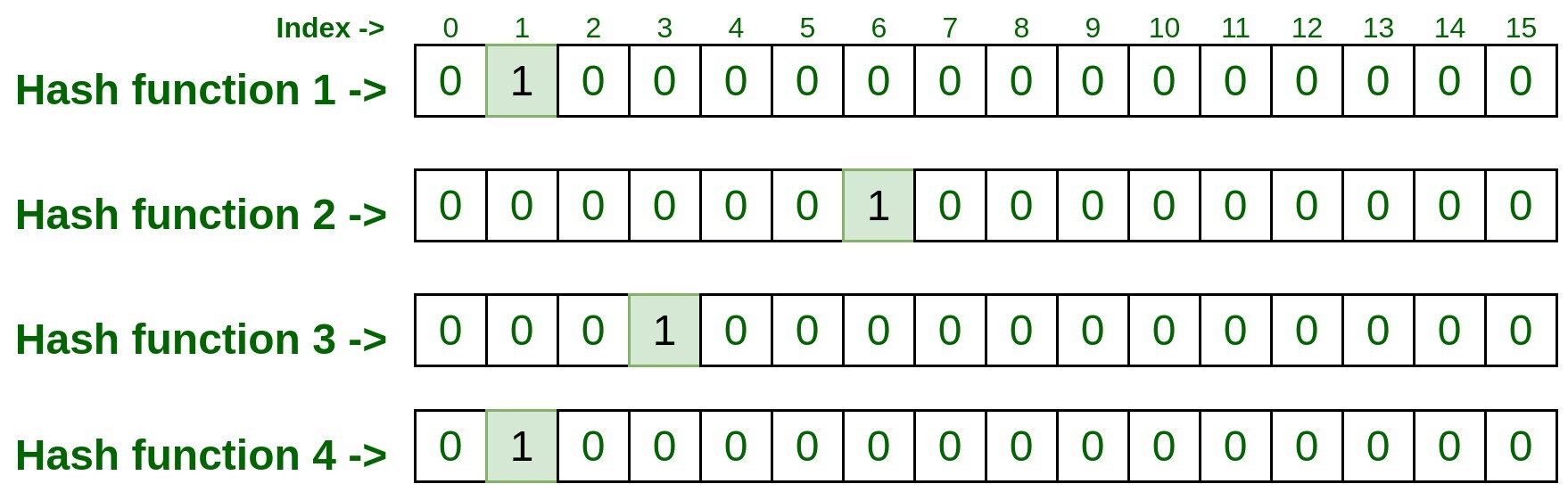
- 类似地,通过将第二个输入传递给所有四个散列函数来处理第二个输入。
Input : 75.245.10.1hashFunction1(75.245.10.1): 1 hashFunction2(75.245.10.1): 2 hashFunction3(75.245.10.1): 4 hashFunction4(75.245.10.1): 6现在,获取这些索引并访问矩阵,如果给定的索引已经被标记为 1。这称为碰撞,这意味着该行的索引已经被一些先前的输入标记,在这种情况下只需增加索引值按 1。在我们的例子中,由于我们已经将第 1 行的索引 1 标记为 1,即 hashFunction1() 被先前的输入标记为 1,所以这次它将增加 1,现在这个单元格条目将是 2,但对于其余的其余行的索引将为 0,因为没有碰撞。
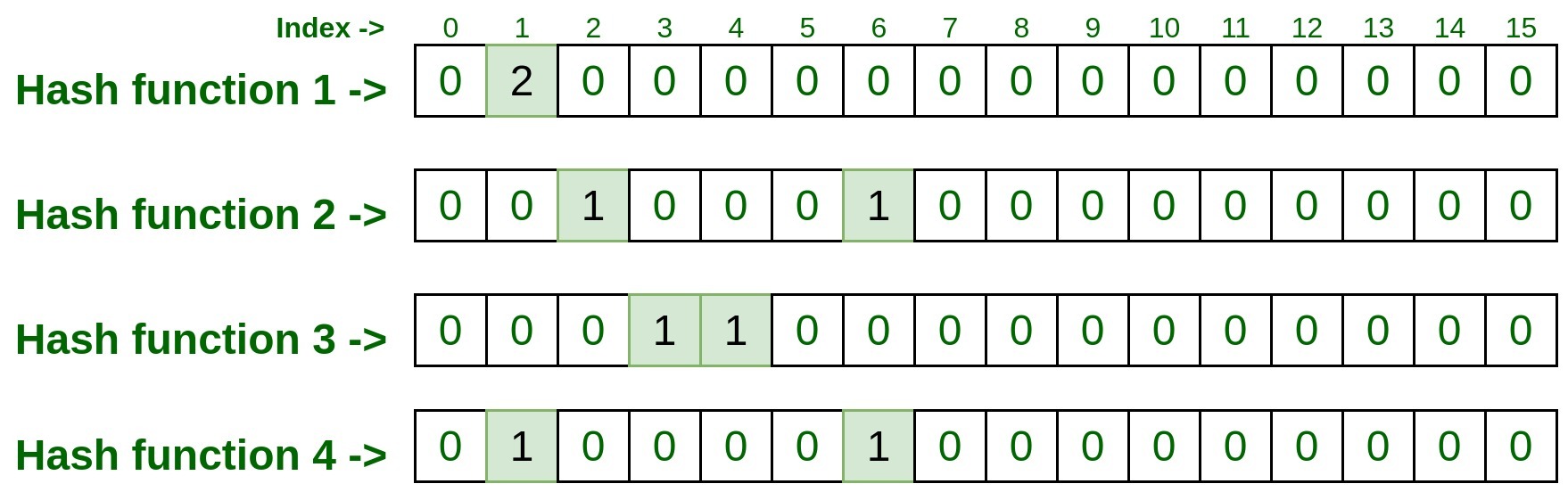
- 让我们处理下一个输入
Input : 10.125.22.20hashFunction1(10.125.22.20): 3 hashFunction2(10.125.22.20): 4 hashFunction3(10.125.22.20): 1 hashFunction4(10.125.22.20): 6让我们在矩阵上表示它,如果已经存在某个条目,请记住将计数增加 1。

- 类似地处理下一个输入。
Input : 192.170.0.1hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1让我们来看看矩阵表示。
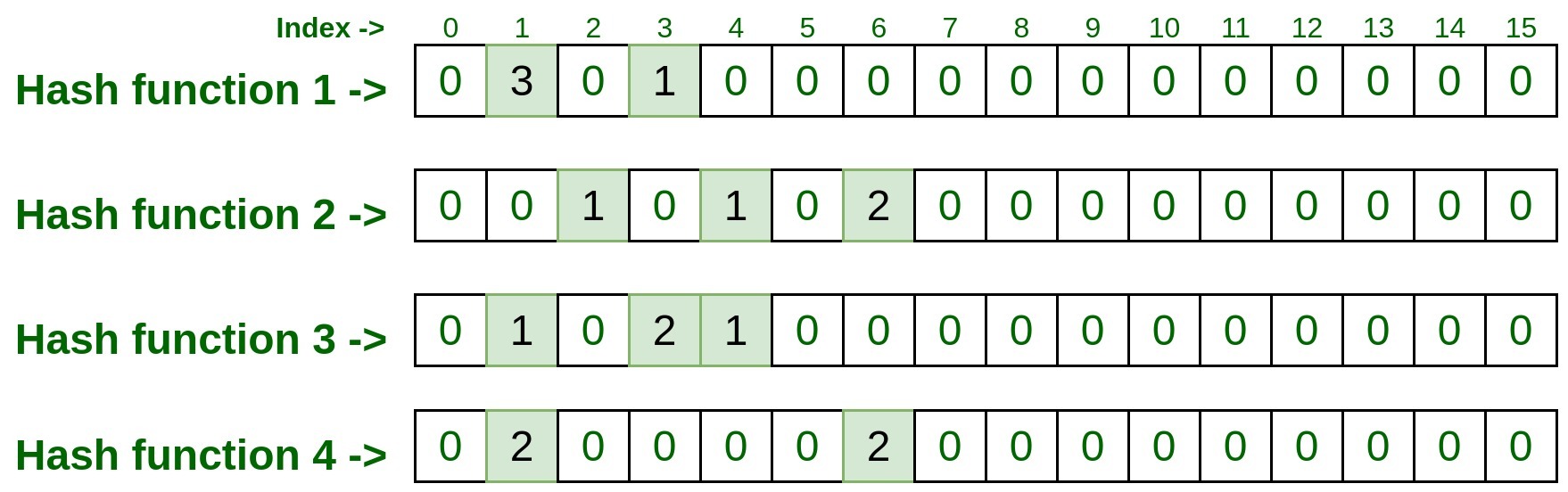
现在让我们测试一些元素并检查它们出现的时间。
-
Test Input #1: 192.170.0.1将上述输入传递给所有四个哈希函数,并获取哈希函数生成的索引号。
hashFunction1(192.170.0.1): 1 hashFunction2(192.170.0.1): 6 hashFunction3(192.170.0.1): 3 hashFunction4(192.170.0.1): 1现在访问每个索引并记下该索引上的条目
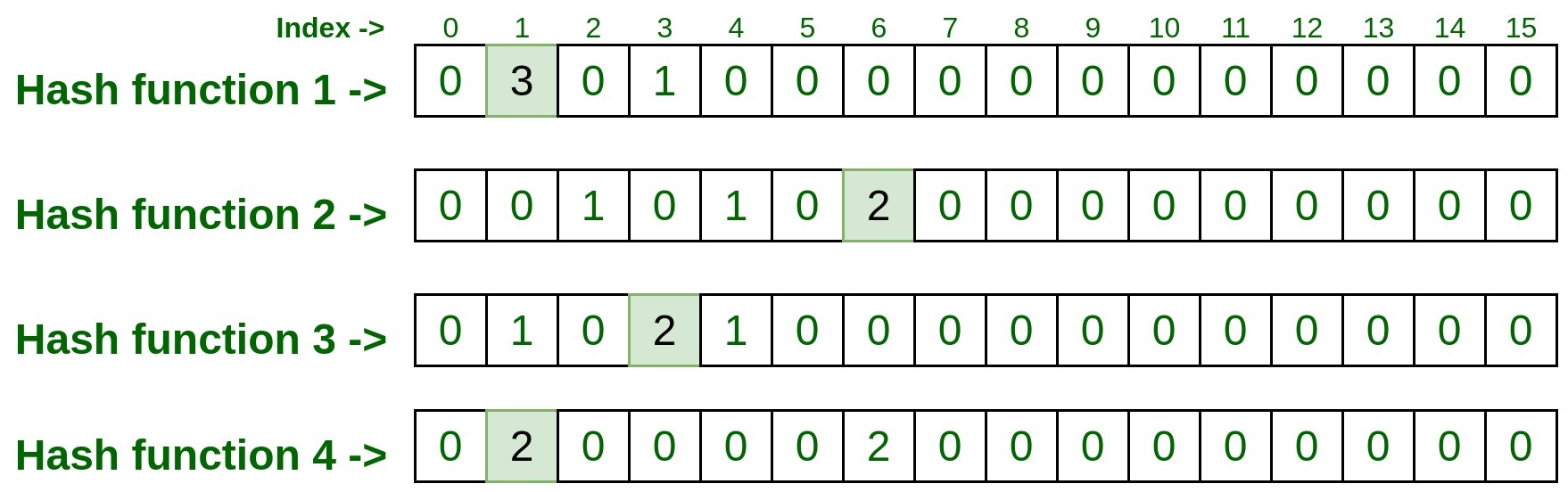
所以每个索引的最后一个条目是3, 2, 2, 2 。现在取这些条目中的最小计数,这就是结果。所以 min(3, 2, 2, 2) 是 2,这意味着上面的测试输入在上面的列表中被处理了两次。 -
Test Input #1: 10.125.22.20将上述输入传递给所有四个哈希函数,并获取哈希函数生成的索引号。
hashFunction1(10.125.22.20): 3 hashFunction2(10.125.22.20): 4 hashFunction3(10.125.22.20): 1 hashFunction4(10.125.22.20): 6现在访问每个索引并记下该索引上的条目
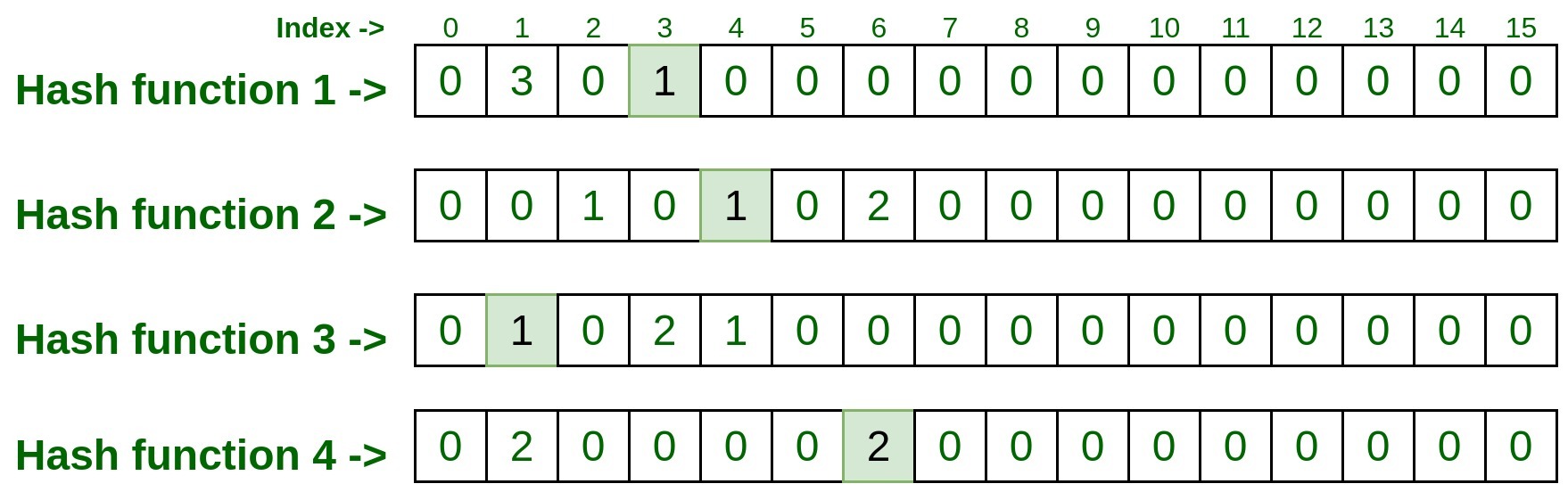
所以每个索引的最后一个条目是1, 1, 1, 2 。现在取这些条目中的最小计数,这就是结果。所以 min(1, 1, 1, 2) 是 1,这意味着上面的测试输入在上面的列表中只处理了一次。
Count-min 草图的问题及其解决方案:
如果一个或多个元素获得相同的散列值,然后它们都增加了怎么办。因此,在这种情况下,由于哈希冲突,该值会增加。因此,有时(在极少数情况下)Count-min 草图由于散列函数而高估了频率。所以我们采用的哈希函数越多,冲突就越少。我们采用的哈希函数越少,碰撞的可能性就越大。因此它总是建议采用更多数量的哈希函数。
Count-min Sketch 的应用:
- 压缩传感
- 联网
- 自然语言处理
- 流处理
- 频率跟踪
- 扩展:重击者
- 扩展:范围查询
在Java使用 Guava 库实现 Count-min 草图:
我们可以使用 Guava 提供的Java库来实现 Count-min 草图。下面是分步实施:
- 使用下面的 maven 依赖项。
com.clearspring.analytics stream 2.9.5 - 详细的Java代码如下:
import com.clearspring.analytics .stream.frequency.CountMinSketch; public class CountMinSketchDemo { public static void main(String[] args) { CountMinSketch countMinSketch = new CountMinSketch( // epsilon 0.001, // delta 0.99, // seed 1); countMinSketch.add("75.245.10.1", 1); countMinSketch.add("10.125.22.20", 1); countMinSketch.add("192.170.0.1", 2); System.out.println( countMinSketch .estimateCount( "192.170.0.1")); System.out.println( countMinSketch .estimateCount( "999.999.99.99")); } }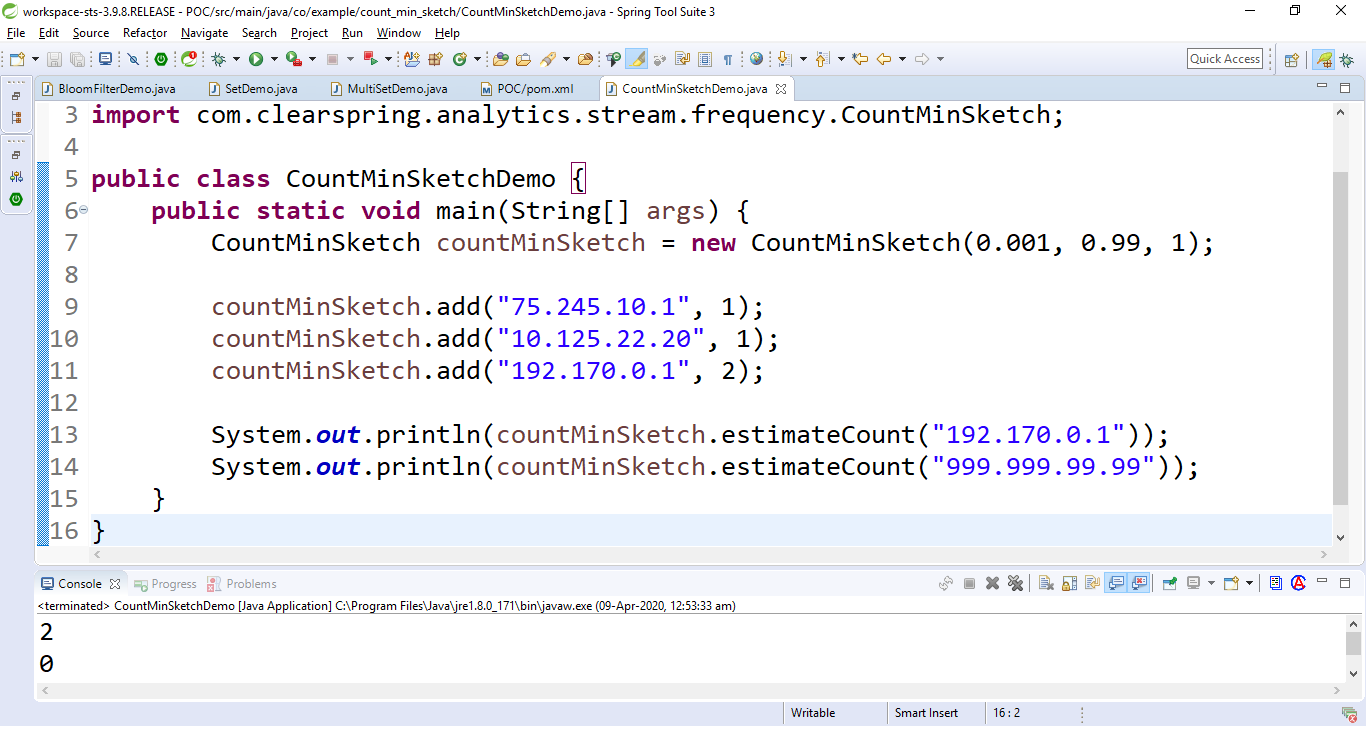
- 上面的例子在构造函数中采用三个参数,它们是
- 0.001 = the epsilon i.e., error rate - 0.99 = the delta i.e., confidence or accuracy rate - 1 = the seed - 现在让我们看看这种方法所消耗的时间和空间。
----------------------------------------------------------------------------- |Number of UUIDs | Multiset Insertion Time(ms) | CMS Insertion Time(ms) | ----------------------------------------------------------------------------- |10 <25 35 | |100 <25 30 | |1, 000 30 69 | |10, 000 257 246 | |100, 000 1200 970 | |1, 000, 000 4244 4419 | ----------------------------------------------------------------------------- - 现在,让我们看看消耗的内存:
-------------------------------------------------------------------------- |Number of UUIDs | Multiset JVM heap used(MB) | CMS JVM heap used(MB) | -------------------------------------------------------------------------- |10 <2 N/A | |100 <2 N/A | |1, 000 3 N/A | |10, 000 9 N/A | |100, 000 39 N/A | |1, 000, 000 234 N/A | --------------------------------------------------------------------------- - 建议:
------------------------------------------------------------------------------------- |Epsilon | Delta | width/Row (hash functions)| Depth/column| CMS JVM heap used(MB) | ------------------------------------------------------------------------------------- |0.1 |0.99 | 7 | 20 | 0.009 | |0.01 |0.999 | 10 | 100 | 0.02 | |0.001 |0.9999 | 14 | 2000 | 0.2 | |0.0001 |0.99999 | 17 | 20000 | 2 | --------------------------------------------------------------------------------------
结论:
我们观察到,在我们必须以低内存消耗处理大型数据集的情况下,Count-min 草图是一个不错的选择。我们还看到,我们想要的更准确的结果必须增加哈希函数的数量(行数/宽度)。
如果您想与行业专家一起参加直播课程,请参阅Geeks Classes Live