给定一个大小为 N的字符串S由小写字母和一个整数 Q组成,该整数 Q 表示对 S 的查询次数。我们的任务是为所有查询 Q 打印子字符串 L 到 R 中重复字符的数量。
注: 1 ≤N ≤ 10 6和 1 ≤ Q≤ 10 6
例子:
Input :
S = “geeksforgeeks”, Q = 2
L = 1 R = 5
L = 4 R = 8
Output :
1
0
Explanation:
For the first query ‘e’ is the only duplicate character in S from range 1 to 5.
For the second query theres is no duplicate character in S.
Input :
S = “Geekyy”, Q = 1
L = 1 R = 6
Output :
2
Explanation:
For the first query ‘e’ and ‘y’ are duplicate characters in S from range 1 to 6.
天真的方法:
最简单的方法是维护一个大小为 26 的频率数组,以存储每个字符的计数。对于每个查询,给定范围 [L, R] 我们将遍历子字符串 S[L] 到 S[R] 并继续计算每个字符的出现次数。现在,如果任何字符的频率大于 1,那么我们将加 1 来回答。
有效的方法:
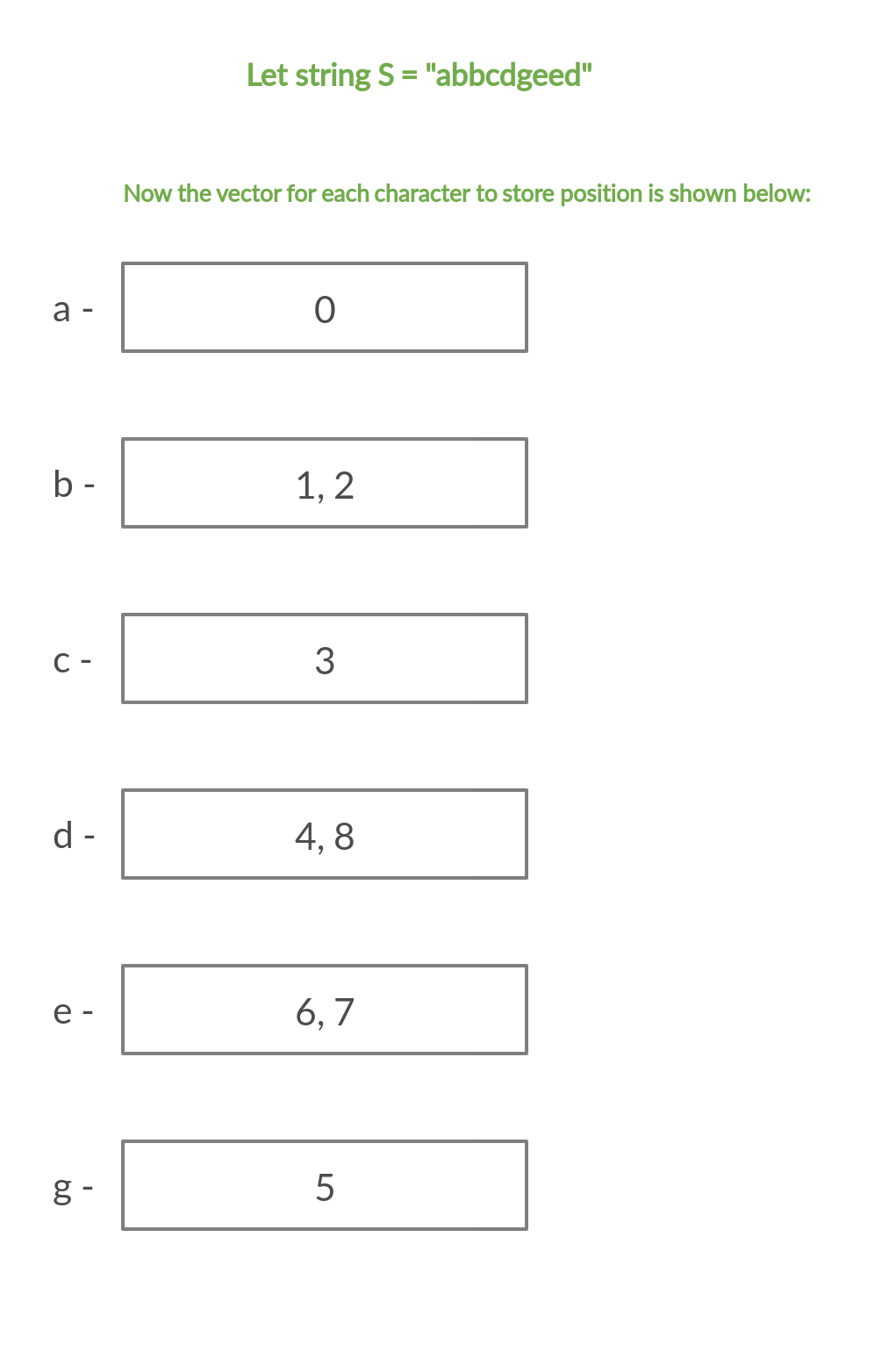
为了以有效的方式解决上述问题,我们将存储每个字符出现在动态数组中的字符串中的位置。对于每个给定的查询,我们将遍历所有 26 个小写字母。如果当前字母在子串 S[L: R] 中,那么对应向量中大于或等于 L的第一个元素的下一个元素应该存在并且小于或等于 R 。
下图显示了我们如何在动态数组中存储字符:
下面是上述方法的实现:
CPP
// CPP implementation to Find the total
// number of duplicate character in a
// range L to R for Q number of queries in a string S
#include
using namespace std;
// Vector of vector to store
// position of all characters
// as they appear in string
vector > v(26);
// Function to store position of each character
void calculate(string s)
{
for (int i = 0; i < s.size(); i++) {
// Inserting position of each
// character as they appear
v[s[i] - 'a'].push_back(i);
}
}
// Function to calculate duplicate
// characters for Q queries
void query(int L, int R)
{
// Variable to count duplicates
int duplicates = 0;
// Iterate over all 26 characters
for (int i = 0; i < 26; i++) {
// Finding the first element which
// is less than or equal to L
auto first = lower_bound(v[i].begin(),
v[i].end(), L - 1);
// Check if first pointer exists
// and is less than R
if (first != v[i].end() && *first < R) {
// Incrementing first pointer to check
// if the next duplicate element exists
first++;
// Check if the next element exists
// and is less than R
if (first != v[i].end() && *first < R)
duplicates++;
}
}
cout << duplicates << endl;
}
// Driver Code
int main()
{
string s = "geeksforgeeks";
int Q = 2;
int l1 = 1, r1 = 5;
int l2 = 4, r2 = 8;
calculate(s);
query(l1, r1);
query(l2, r2);
return 0;
} Python3
# Python implementation to Find the total
# number of duplicate character in a
# range L to R for Q number of queries in a string S
import bisect
# Vector of vector to store
# position of all characters
# as they appear in string
v = [[] for _ in range(26)]
# Function to store position of each character
def calculate(s: str) -> None:
for i in range(len(s)):
# Inserting position of each
# character as they appear
v[ord(s[i]) - ord('a')].append(i)
# Function to calculate duplicate
# characters for Q queries
def query(L: int, R: int) -> None:
# Variable to count duplicates
duplicates = 0
# Iterate over all 26 characters
for i in range(26):
# Finding the first element which
# is less than or equal to L
first = bisect.bisect_left(v[i], L - 1)
# Check if first pointer exists
# and is less than R
if (first < len(v[i]) and v[i][first] < R):
# Incrementing first pointer to check
# if the next duplicate element exists
first += 1
# Check if the next element exists
# and is less than R
if (first < len(v[i]) and v[i][first] < R):
duplicates += 1
print(duplicates)
# Driver Code
if __name__ == "__main__":
s = "geeksforgeeks"
Q = 2
l1 = 1
r1 = 5
l2 = 4
r2 = 8
calculate(s)
query(l1, r1)
query(l2, r2)
# This code is contributed by sanjeev25521
0 `
时间复杂度: O( Q * 26 * log N)
如果您想与行业专家一起参加直播课程,请参阅Geeks Classes Live