先决条件 – ETL(提取、转换和加载)过程
ETL 代表提取、转换和加载。
这是三个数据库功能,它们被合并到一个工具中,用于从一个数据库中提取数据并将数据放入另一个数据库中。
大数据包含范围广泛的海量数据,这些数据可以是结构化的,也可以是非结构化的。 RDBMS 发现处理大量数据具有挑战性。此外,RDBMS 旨在稳定数据保留而不是快速增长。这就是数据仓库的用武之地。
数据仓库支持所有类型的数据,也可以处理快速增长的数据。因此,对于数据分析,数据需要从数据库转移到数据仓库。借助下图可以很好地解释 ETL 过程的工作。
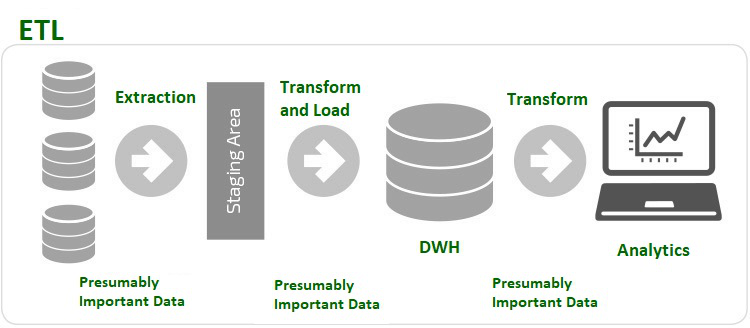
ETL流程
ETL过程的应用是:
- 将数据移入和移出数据仓库。数据库不适合大数据分析,因此需要将数据从数据库移动到数据仓库,这是通过 ETL 过程完成的。
- 数据策略比以往任何时候都更加复杂。 ETL 有助于将大量数据转化为可操作的商业智能。
ETL 中有两种方法:
- 自上而下的方法 :
自顶向下 OLAP 环境中的数据流从从操作数据源中提取数据开始。这些数据被加载到暂存区并经过验证和整合以确保正确性,然后移动到操作数据存储 (ODS)。如果 ODS 阶段是操作数据库的另一个副本,则有时会跳过它。数据并行加载到数据仓库中,以避免从 ODS 中提取数据。数据通常从 ODS 中提取并临时托管在暂存区进行聚合、汇总,然后提取并加载到数据仓库中。
是否需要 ODS 取决于业务需求。如果需要数据仓库中的详细数据,则必须创建 ODS。一旦数据仓库聚合和汇总过程完成,数据集市将从数据仓库中提取数据到暂存区并对其执行一组新的转换。这将有助于按照数据集市的要求以特定结构组织数据。
之后,数据集市可以加载数据,并且 OLAP 环境可供用户使用。数据仓库中的数据是历史数据。 Inmon 提出了一种自顶向下的模型方法,使用传统的数据库建模技术(ER 模型)创建一个集中的企业数据仓库,其中数据存储在 3NF 中。数据仓库现在充当新数据集市的数据源。
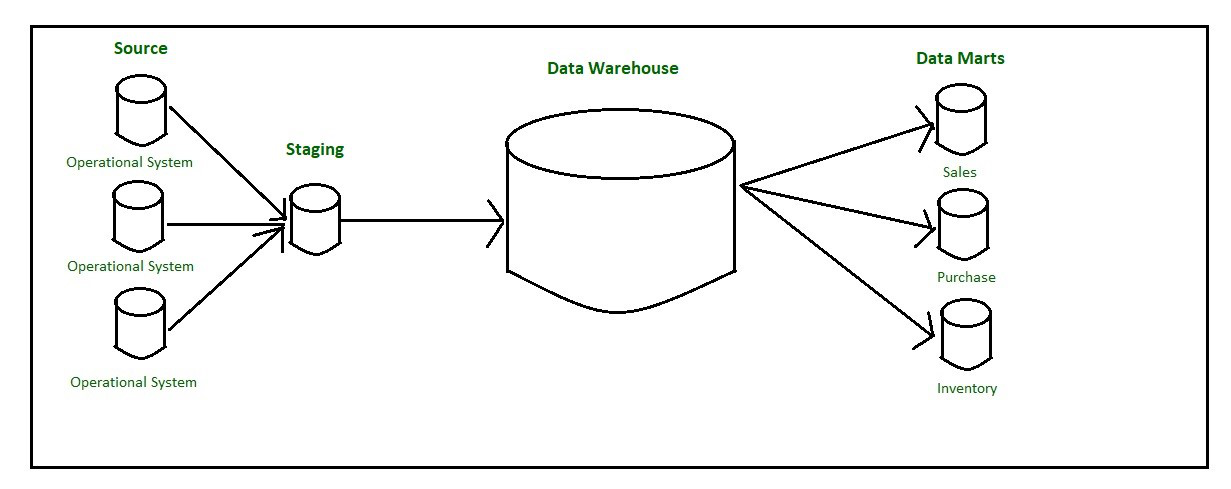
自上而下的方法
- Kimball 方法论(自下而上的方法):
自下而上的方法颠倒了数据仓库和数据集市的位置。数据集市通过暂存区直接加载数据。 ODS 的存在取决于业务需求。自下而上方法中的数据流从将数据从操作数据库中提取到暂存区开始,在该暂存区中对其进行处理和整合,然后加载到 ODS 中。ODS 中的数据将附加到正在加载的新数据中,或者由正在加载的新数据替换。一旦 ODS 被刷新,当前数据将再次被提取到暂存区并进行处理。来自数据集市的数据被汇总、汇总等拉到暂存区,并加载到数据仓库中,并提供给最终用户进行分析。
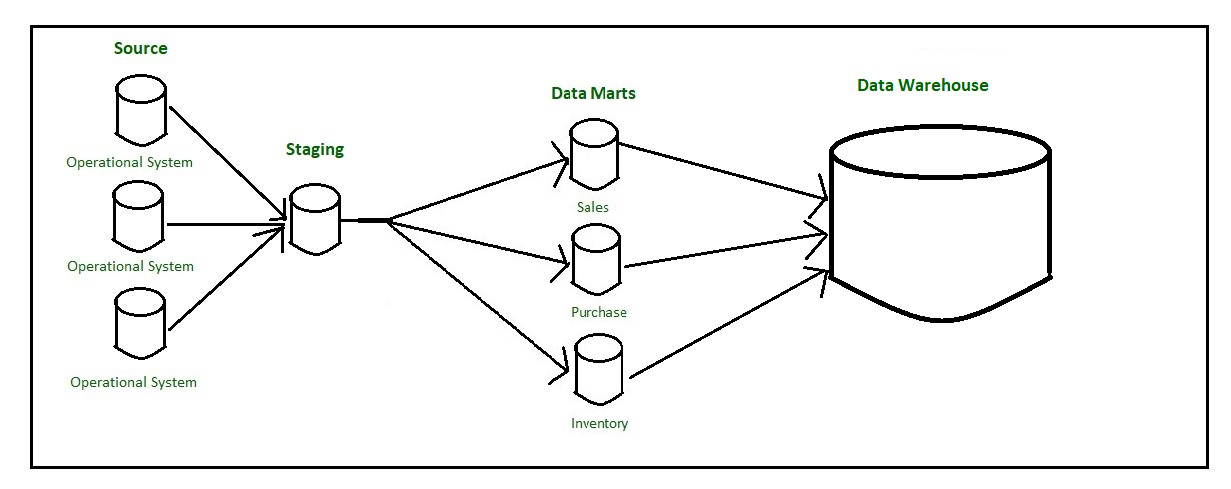
自下而上的方法
ETL工具:
一些最常用的 ETL 工具是 MarkLogic、Oracle、Sybase、Hevo 和 Xplenty。
ETL工具的优点:
- 易于使用。
- 同时加载来自不同目标的数据。
- 根据需要执行数据转换。
- 更适合复杂的规则和转换。
- 内置错误处理功能。
- 基于 GUI 并提供可视化流程。
- 节省成本并产生更高的收入。
ETL工具的缺点:
- 不适合近乎实时的数据访问。
- 更倾向于批量数据处理
- 难以跟上不断变化的需求。