在本文中,我们将描述如何进行批量读取,这也有助于提高性能。在阅读本文之前,请先了解 Cassandra 中的基本架构。
我们将创建用于练习的数据模式以测试 Cassandra 中的批量读取。
我们来看一下。
首先,我们要创建表。
要创建的表模式:
keyspace name - cluster1
Table name - user_data_app | column-name | Data Types |
|---|---|
| id | uuid |
| name | text |
| status | text |
现在,让我们编写 CQL 查询来创建上面给定的表模式。
create table user_data_app
(
id uuid primary key,
name text,
status text
); 现在,让我们向表中插入数据。下面给出的是在表中插入行的 CQL 查询。
Insert into user_data_app(id, name, status)
values(uuid(), 'Ashish', 'ok');
Insert into user_data_app(id, name, status)
values(uuid(), 'amit', 'in processing');
Insert into user_data_app(id, name, status)
values(uuid(), 'Bhagyesh', 'ok');
Insert into user_data_app(id, name, status)
values(uuid(), 'Alice', 'in processing');
Insert into user_data_app(id, name, status)
values(uuid(), 'Bob', 'ok'); 现在,让我们看看数据添加成功的结果。为了验证结果,使用下面给出的以下 CQL 查询。
SELECT token(id)
FROM user_data_app; 输出:

现在,我们将找出分区列的标记 id,我们可以通过它来执行比较,并且我们将使用它来执行批量读取。
SELECT token(id)
FROM user_data_app; 输出:
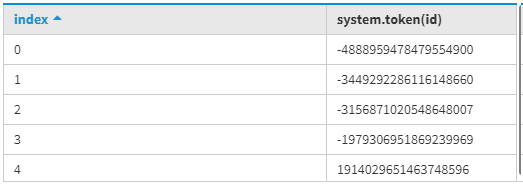
现在,让我们看看下面的 CQL 查询,我们将使用它进行批量读取。
SELECT token(id), id, name, status
FROM user_data_app
WHERE
token(id) >-4888959478479554900
AND
token(id) <= 1914029651463748596; 输出:
