先决条件 – Cassandra 简介,数据建模概述
在本文中,我们将讨论如何在 Cassandra 中设计模型。建模设计是任何应用程序的关键部分之一。因此,让我们通过一个示例来讨论如何为任何应用程序创建更好的模型,我们将看到我们如何做到这一点。
正如您将看到的,Cassandra 有一种与 RDBMS 建模不同的数据建模方法。我们可以在讨论数据建模时看到差异。在 RDBMS 中,我们可以在创建表的同时执行 JOINS,也可以通过在相关表中使用外键来避免重复。
在 Cassandra 中,我们可以说情况并非如此,Cassandra 是一个分布式系统,我们可以在需要时对数据进行非规范化。在 RDBMS 中,我们可以通过 JOIN 检索和获取,而在 Cassandra 中,这可能很昂贵,因为我们可以通过分区键检索数据,而在 Cassandra 中,数据跨越 Cassandra 中的节点。
设计模型时要牢记目标——
- 数据均匀分布:
在集群中,数据的均匀分布是关键目标之一,对于单列主键将是分区键,对于复合主键,分区键将是分区键和集群键。我们应该有一个基于唯一性的主键(PK),例如我们可以说像 ID、电子邮件、用户名这样应该被选为 PK,在这种情况下,节点集群将被充分利用。 - 最小化读取次数:
在 Cassandra 中,我们必须提前知道系统中需要的查询,然后相应地设计模型。在 Cassandra 中,如果单个查询从多个分区获取数据,那么这会影响系统性能,从而导致系统变慢。在 RDBMS 中,我们有这样的自由,我们可以在首先设计模式后创建查询,以显示它与非关系模型的实际区别。
用例:
访问该网站的人数和管理层希望遵循下面给出的详细信息。我们来看一下。
- 所有员工名单
- 所有域的列表。
- 按域划分的员工列表
现在,让我们一一创建表。首先,我们将创建表域。
CREATE TABLE Domain (
D_id int,
D_name text,
D_info text,
PRIMARY KEY(D_id)
); 现在,我们将创建 Employee 表。
CREATE TABLE Employee (
username Varchar,
E_name text,
E_age int,
PRIMARY KEY(username)
); 现在,我们将向域表中插入一些数据。
INSERT INTO Domain(D_id, D_name, D_info)
VALUES (1, 'database', '50 member');
INSERT INTO Domain(D_id, D_name, D_info)
VALUES (2, 'Management', '10 member');
INSERT INTO Domain(D_id, D_name, D_info)
VALUES (3, 'Networking', '15 member');
INSERT INTO Domain(D_id, D_name, D_info)
VALUES (4, 'software', '50 member'); 现在,我们将向 Employee 表中插入一些数据。
INSERT INTO Employee(username, E_name, E_age)
VALUES ('Alpha007', 'Ashish', 23);
INSERT INTO Employee(username, E_name, E_age)
VALUES ('Alice007', 'Alice', 23);
INSERT INTO Employee(username, E_name, E_age)
VALUES ('Bob007', 'Bob', 23); 在 RDBMS 的情况下,我们可以使用 Domain_id 作为 Employees 表中的外键,通过 JOIN 我们可以获得数据,但我们是在 Cassandra 中设计模型。因此,在 Cassandra 的情况下,我们必须创建另一个表来满足每个要求。
CREATE TABLE Employees_by_Domains (
username varchar,
E_name text,
D_name text,
E_age int,
PRIMARY KEY(D_name, E_age)
); 在Employees by Domains 表中,主键有两部分,第一个是D_name 主键,第二个是E_age,它是集群键,记录由E_age 集群。
insert into Employees_by_Domains(username, E_name, D_name, E_age)
VALUES ('Ashish001', 'Rana', 'Software Er.', 23);
insert into Employees_by_Domains(username, E_name, D_name, E_age)
VALUES ('Alice007', 'Alice', 'Database', 25);
insert into Employees_by_Domains(username, E_name, D_name, E_age)
VALUES ('Bob007', 'Bob', 'Networking', 26); 现在,我们将看到每个表的结果并根据用例获取数据。
我们来看一下。
要查看域表的结果,请使用下面给出的以下 CQL 查询。
Select *
from Domain; 输出:

要查看 Employee 表的结果,请使用下面给出的以下 CQL 查询。
Select *
from Employee; 输出:

要查看Employees_by_Domains 表的结果,请使用下面给出的以下CQL 查询。
Select *
from Employees_by_Domains; 输出:

要获取令牌值,请使用下面给出的以下 CQL 查询。
select token(username)
from Employee; 输出:
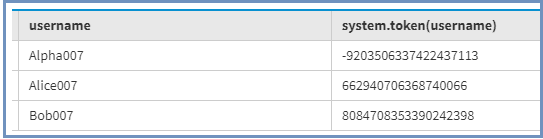
每个用户名的每个令牌值都是唯一的,令牌将跨节点传播。当我们将执行以下查询时:
SELECT *
FROM Employee
where username = 'Alpha007' 它将返回数据并根据此 (-9203506337422437113) 令牌值选择节点。