Avinash Lakshman 和 Prashant Malik 最初在 Facebook 开发了 Cassandra,以支持 Facebook 收件箱搜索功能。 Facebook 于 2008 年 7 月发布了 Cassandra 作为谷歌代码的开源项目。它于 2009 年 3 月成为 Apache 孵化器项目。它于 2010 年 2 月 17 日成为顶级项目之一。在互联网革命、移动设备和电子商务的推动下,现代应用程序已经超越了关系数据库。出于必要,新一代数据库应运而生,以应对大规模、全球分布的数据管理挑战。
Cassandra 为一些世界上最知名的品牌提供在线服务和移动后端支持,包括 Apple、Netflix 和 Facebook。
Apache Cassandra 的架构:
在本节中,我们将描述 Apache Cassandra 的以下组件。
基本术语:
Node
Data center
Cluster操作:
Read Operation
Write Operation存储引擎:
CommitLog
Memtables
SSTablesData Replication Strategies让我们一一讨论。
基本术语:
- 节点:
Node 是 Apache Cassandra 中的基本组件。它是实际存储数据的地方。例如:如图所示,IP 地址为 10.0.0.7 的节点包含数据(包含一个或多个表的键空间)。
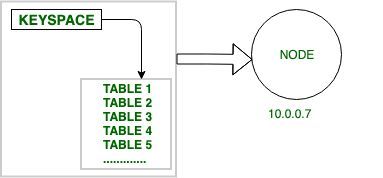
- 图 –节点
- 数据中心:
数据中心是节点的集合。
例如:
DC – N1 + N2 + N3 ….
DC: Data Center
N1: Node 1
N2: Node 2
N3: Node 3 - 簇:
它是许多数据中心的集合。
例如:
C = DC1 + DC2 + DC3….
C: Cluster
DC1: Data Center 1
DC2: Data Center 2
DC3: Data Center 3 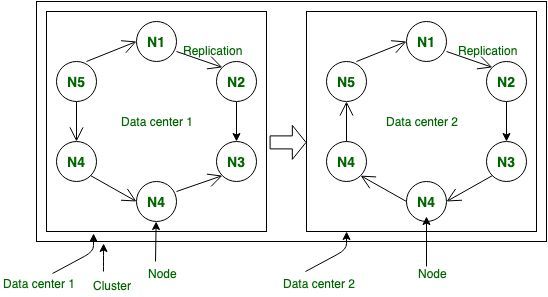
- 图 –节点、数据中心、集群
操作:
- 读操作:
在读取操作中,协调器可以向副本发送三种类型的读取请求。接受写入请求的节点称为该特定操作的协调器。- 步骤 1:直接请求:
在此操作中,协调器节点将读取请求发送到其中一个副本。 - 第 2 步:摘要请求:
在此操作中,协调器将联系由一致性级别指定的副本。例如:一致性二;它只是意味着数据中心中的任何两个节点都会确认。 - 第 3 步:阅读修复请求:
如果存在节点间数据不一致的任何情况,则发起后台读取修复请求,以确保最新数据在节点间可用。
- 步骤 1:直接请求:
- 写操作:
- 步骤1:
在写入操作中,一旦我们收到请求,它就会首先转储到提交日志中以确保数据被保存。 - 第2步:
将数据插入表中,该表也写入 MemTable 中,该表保存数据直到数据填满。 - 第 3 步:
如果 MemTable 达到其阈值,则数据将刷新到 SS 表。
- 步骤1:

- 图 – Cassandra 中的写操作
存储引擎:
- 提交日志:
提交日志是写入磁盘或 memTable 时的第一个入口点。在 apache Cassandra 中提交日志的目的是在数据节点关闭时解决服务器同步问题。 - 内存表:
在将数据写入 Commit log 之后,然后将数据写入 Mem-table。数据暂时写入Mem-table。 - SS表:
一旦 Mem-table 达到某个阈值,则数据将刷新到 SSTable 磁盘文件。
数据复制策略:
基本上它用于备份以确保没有单点故障。在这个策略中,Cassandra 使用复制来实现高可用性和持久性。每个数据项都在 N 台主机上复制,其中 N 是“每个实例”配置的复制因子。
有两种类型的复制策略:简单策略和网络拓扑策略。这些解释如下。
- 简单策略:
在此策略中,它允许定义单个整数 RF(replication_factor)。它确定应包含每行副本的节点数。例如,如果 replication_factor 是 2,那么两个不同的节点应该存储每一行的副本。它对所有节点一视同仁,忽略任何配置的数据中心或机架。简单策略的 CQL(Cassandra 查询语言)查询。使用 CREATE KEYSPACE 语句创建密钥空间:
create_keyspace_statement ::=
CREATE KEYSPACE [ IF NOT EXISTS ] keyspace_name
WITH options -
例如:
CREATE KEYSPACE User_data
WITH replication = {'class': 'SimpleStrategy',
'replication_factor' : 2}; -
要检查密钥空间架构,请使用以下 CQl 查询。
DESCRIBE KEYSPACE User_data-
简单策略的图形表示。

- 图 –简单策略
- 网络拓扑策略:
在此策略中,它允许为集群中的每个数据中心指定一个复制因子。即使您的集群仅使用一个数据中心。此策略应优先于 SimpleStrategy,以便以后更轻松地向集群添加新的物理或虚拟数据中心。网络拓扑策略的 CQL(Cassandra 查询语言)查询。
CREATE KEYSPACE User_data
WITH replication = {'class': 'NetworkTopologyStrategy', 'DC1' : 2, 'DC2' : 3}
AND durable_writes = false; - 要检查密钥空间架构,请使用以下 CQl 查询。
DESCRIBE KEYSPACE User_data-
网络拓扑策略的图示。
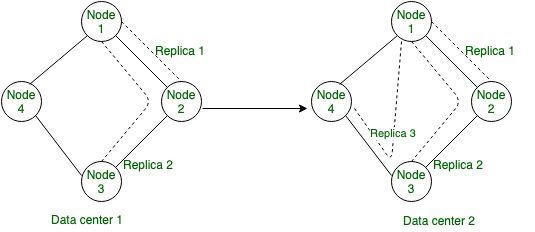
- 图 –网络拓扑策略
Cassandra 中的表结构:
USE User_data;
CREATE TABLE User_table (
User_id int,
User_name text,
User_add text,
User_phone text,
PRIMARY KEY (User_id)
);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1000, ‘Ashish’, ‘Noida’, ‘8077178539’);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1001, ‘Ashish Gupta’, ‘Bangalore’);
Insert into User_data (User_id, User_name, User_add, User_phone )
VALUES(1002, ‘Abi’); 输出:
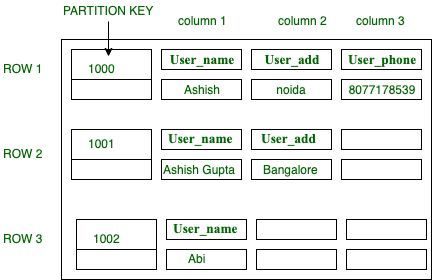
图 –表结构
Apache Cassandra 的应用:
Cassandra 擅长的一些应用程序用例包括:
- 实时大数据工作负载
- 时间序列数据管理
- 高速设备数据消费与分析
- 媒体流管理(例如,音乐、电影)
- 社交媒体(即非结构化数据)输入和分析
- 在线网络零售(例如,购物车、用户交易)
- 实时数据分析
- 在线游戏(例如,实时消息传递)
- 利用 Web 服务的软件即服务 (SaaS) 应用程序
- 在线门户(例如,医疗保健提供者/患者互动)
- 大多数写入密集型系统