确保流畅的功能和高效的运行时服务器的商业需求使得数据库设计人员非常重要地制定系统和代码,巧妙地避免多用户事务中的任何类型的不一致,如果不怀疑读取中的内存管理标准-heavy、write-heavy 和所有此类商业数据库。本文将充分介绍为数据库开发人员社区提出和实现的经典锁定架构。
我们应该尽量忽略一般的锁定技术,即基于数据库的粒度或级别。所以我们在看锁的种类的可行性的时候可以分别处理。
定义 :
锁的正式定义如下:
A Lock is a variable assigned to any data item in order to keep track of the status of that data item so that isolation and non-interference is ensured during concurrent transactions.
从根本上说,数据库锁的存在是为了防止两个或多个数据库用户同时对同一数据项执行任何更改。因此,将此技术解释为同步访问的一种方式是正确的,这与使用时间戳和多版本时间戳的其他协议集形成鲜明对比。通俗地说,这可以进一步简化为隐喻的“锁”,它被放置在数据项上,以便其他用户无法解锁执行任何更新查询的能力。
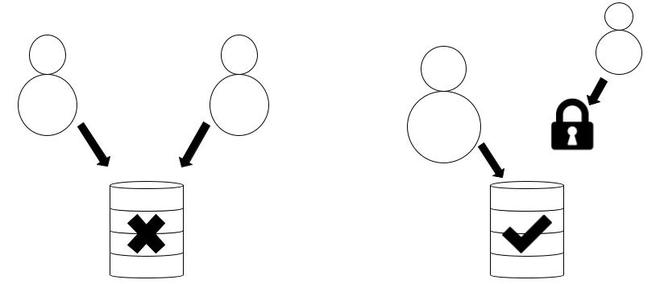
情况 1:不允许同时访问交易。案例2:对其他交易加锁是可行的
在上面描述的情况 2 中,如果右侧的用户/会话尝试更新,它将遇到LOCK WAIT状态或以其他方式停止,直到对数据项的访问被解锁。在某些情况下 – 如果停顿超过时间限制 – 会话将终止并返回错误语句。
我们将研究这些锁作为事务并发解决方案在行业中引入的多种方式。
二元锁:
请记住,锁基本上是一个保存值的变量。二元锁是一个变量,它只能保存 2 个可能的值,即1(表示锁定状态)或0(表示未锁定状态) 。此锁通常与数据库中的每个数据项相关联(可能在表级、行级甚至整个数据库级)。

如果项目 X 被解锁,那么相应的对象 lock(X) 将返回值 0。因此,当用户/会话开始更新项目 X 的内容时,lock(X) 的值设置为 1。由于这样,只要更新查询持续,其他用户就不能访问项目 X——甚至读取或写入它!
有两种操作用于实现二进制锁。它们是 lock_data() 和 unlock_data()。下面讨论了算法(由于 DBMS 脚本的多样性,只讨论了算法):
锁定操作:
lock_data(X):
label: if lock(X) == 0
{
then lock(X) = 1;
}
else //when lock(X) == 1 or item X is locked
{
wait (until item is unlocked or lock(X)=0) //wait for the user to finish the update query
go to label
}请注意’标签: ‘ 字面上是行的标签,可以在稍后的步骤中引用以将执行转移到。 else 块中的“wait”命令基本上将所有其他想要访问 X 的事务放入队列中。由于它监视或保持其他事务的调度直到对项目的访问被解锁,所以它通常被认为是在 lock_data(X) 操作之外,即在外部定义。
解锁操作:
unlock_data(X):
lock(X) = 0 //we unlock access to item X
if (transactions are in queue)
{
then grant access or 'wake' the next transaction in line;
}二元锁的优点:
- 它们易于实现,因为它们实际上是互斥的并且完美地建立了隔离。
- 二元锁对系统的要求较少,因为系统必须只保留锁定项目的记录。该系统是锁管理器子系统,它是当今所有 DBMS 的一个功能。
二元锁的缺点:
- 二元锁是高度限制性的。
- 它们甚至不允许阅读项目 X 的内容。因此,它们不用于商业用途。
共享锁或独占锁:
控制这些类型锁的动机是二元锁的限制性。在这里,我们看一下允许其他事务进行读取查询的锁,因为READ 查询是非冲突的。然而,如果一个事务需要对项目 X 进行写查询,那么必须给予该事务对项目 X 的独占访问权限。因此,我们需要一种多模式锁,即共享/独占锁。它们也称为读/写锁。
与二进制锁不同,读/写锁可以设置为 3 个值,即SHARED 、 EXCLUSIVE或UNLOCKED 。因此,我们的锁,即 lock(X),可能反映以下任一值:
- 读锁定 –
如果一个事务只需要读取 item X 的内容,并且锁只允许读取。这也称为共享锁。 - 写锁定 –
如果事务需要更新或写入项 X,则锁必须限制所有其他事务并提供对当前事务的独占访问。因此,这些锁也称为排他锁。 - 解锁 –
一旦一个事务完成了它的读或更新操作,就不会持有锁并且数据项被解锁。在这种状态下,任何排队的事务都可以访问该项目。
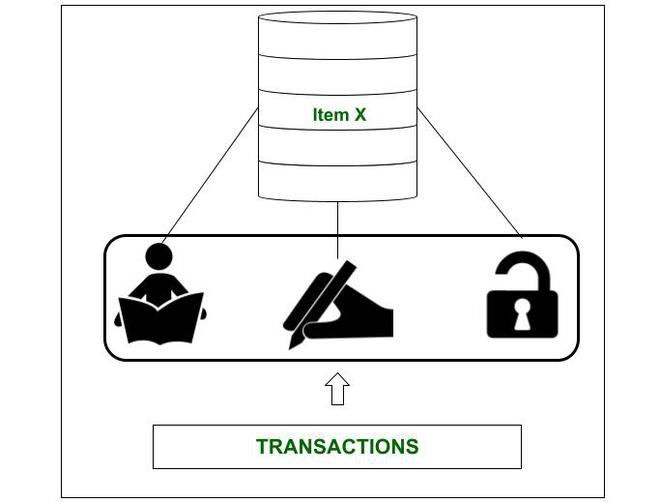
Shared/Exclusive 锁可以持有 3 种状态中的任何一种。
实现这些锁最流行的方法是引入一个 LOCK-TABLE,它跟踪数据项上的读锁数量和不同项目上具有写锁的事务。该表已在下面进行了描述。
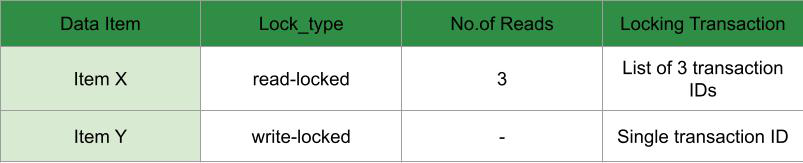
请注意,如果一个项目是写锁定的,由于它现在是独占的,因此在逻辑上应该没有读取。因此,“锁定交易”列仅包含一个值——当前交易的交易 ID。如果一个项目被读锁定,它被多个事务共享,因此,“锁定事务”列列出了所有事务的事务 ID。由于锁可能持有 3 个状态,因此必须有 3 个操作来执行对这些状态的更改。这些如下:
read_lock 操作 –
read_lock(X):
label: if lock(X) = "unlocked"
{
then lock(X) = "read-locked";
no_of_reads = 1; //since only the first transaction in queue is now able to read item X
}
else if lock(X) = "read-locked"
{
then no_of_reads +=1; //simply increment as a new transaction is now reading the item X
}
else //lock(X) write-locked
{
wait (until lock(X) is "unlocked");//transactions observe a LOCK WAIT during this time
go to label;
}当 lock(X) 设置为“写锁定”(在最后的 else 子句中)时,该项目将被事务以独占方式访问。为了让其他事务访问它, LOCK WAIT必须结束(更新过程必须完成)并且 lock(X) = “unlocked”。这就是我们在下一行等待的内容。
write_lock 操作 –
write_lock(X):
label: if lock(X) = "unlocked"
{
then lock(X) = "write-locked"
}
else //if a read-lock is issued to item X
{
wait (until lock(X) is "unlocked"); //so that the lock manager may wake up the next transaction
go to label;
}如果某个项目被解锁,我们只需对其进行写锁定以授予对当前事务的独占访问权限。现在锁管理器系统必须将所有其他事务放入队列中。如果项目处于读锁定状态,则不能直接发出写锁定。该项目必须先解锁,然后才能被写锁定。这样做时,锁管理器系统也会唤醒排队的事务。
解锁操作——
unlock(X):
if lock(X) = "write-locked"
{
then lock(X) = "unlocked";
//the transactions in queue, if any, may now access item X in the manner they demand
}
else if lock(X) = "read-locked"
{
then
no_of_reads-=1; //the transaction is done reading.
if no_of_reads == 0 //no transactions reading the item
{
lock(X) = "unlocked";
//transactions in queue, if any, may now access item X in the manner they demand
}
}第一种情况很简单。然而,在第二种情况下,我们必须检查没有更多当前事务共享或读取项目 X 的条件。如果项目 X 正在被读取,我们离开这种情况并在最后一个事务终止时简单地减少 no_of_reads。这里的要点是,一个项目可能“只有在以下情况下才能被解锁:
- “写”操作终止或完成
- 所有“读取”操作终止或完成
以下是共享/排他锁必须遵守的一些规则:
- 事务T必须在所有读取和写入操作完成后发出 unlock(X) 操作。
- 事务T可能不会对已经向自身发出读或写锁的项目发出 read_lock(X) 或 write_lock(X) 操作。
- 事务T不允许发出 unlock(X) 操作,除非它已通过 read_lock(X) 或 write_lock(X) 操作发出。
当我们放宽这些规则时,可以引入一个交换项目锁定状态的新维度。这已在以下文章中进行了解释:DBMS 中基于锁的并发控制协议
共享/排他锁的缺点:
- 不要自行保证计划的可串行化。必须遵循单独的协议来确保这一点。
- 商业上未针对快速交易进行优化;由于锁争用问题,这不是最佳解决方案。
- 性能开销不容忽视。
认证锁:
引入认证锁背后的动机是前面提到的锁未能提供一种高效且有前途的架构,该架构不会影响处理事务的速度。这里我们简单地看一下多模式锁定方案的一种形式,它允许锁具有3 个锁定状态 和1 个解锁状态。
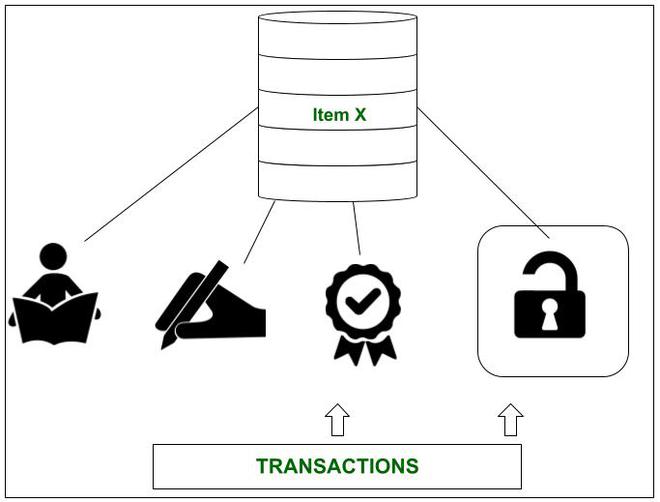
交易可以发出 3 种锁定状态或 1 种解锁状态中的任何一种
项目可能发出的状态是:
- 读锁定–
与前面为共享/排他锁解释的读锁定状态相同 - 写锁定–
与前面为共享/排他锁解释的写锁定状态相同 - 认证锁定–
这是一个排他锁。当必须分别对项目 X 读取和写入 2 个不同的事务时使用此方法。为了实现这一点,将创建数据项的已提交版本和本地版本。提交的版本被所有具有向 X 发出读锁的事务使用。只有当 T 获取了写锁时,T 才能访问 X 的本地版本。一旦由 T 执行了写入或更新操作T 在项目 X 上,T 必须获得一个认证锁,以便数据项目 X 的提交版本可以更新为本地版本的内容,并且本地版本可以被丢弃。 - 解锁–
与前面为共享/排他锁解释的写锁定状态相同
以下是在多版本并发控制技术中如何使用认证锁:

在步骤 2 中,项目 X 的两个版本被创建,即提交版本和本地版本。在步骤 4 中,事务必须对它所做的所有写操作发出认证锁。只有这样我们才能进行下一步。本地版本的更新现已完成。
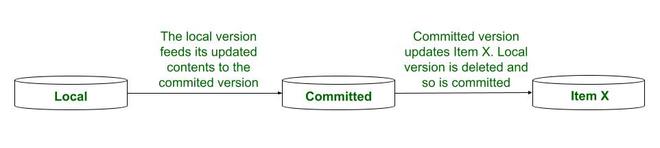
第 5 步
为了让多个事务访问数据项 X 的内容,必须绘制一个兼容性表,以便不返回任何冲突或错误,这可能会延迟进程。
|
Locks on X |
Read | Write | Certify |
| Read |
Yes |
Yes |
No |
| Write |
Yes |
No |
No |
| Certify |
No |
No |
No |
正确解释该表的方法如下。考虑两个事务, T和T’ 。将事务 T 分配给行或列。对 T’ 执行完全相反的操作。现在可以交叉引用 T 和 T’ 向项目 X 发出的锁之间的兼容性。例如,将 T 分配给行,将 T’ 分配给列。如果 T 对 X 发出读锁,而 T’ 对 X 发出写锁,则结果为“是”——这种情况是可行的。但是,如果 T 打算对 X 进行写锁定,而 T’ 打算对 X 进行证明锁定,则结果是“否”——这意味着不可能发生的情况。
还有更多的主题着眼于开发更好和更先进的技术来处理并发控制,例如时间戳、数据项的多版本模型和快照隔离。然而,在建立对可能与并发控制一样复杂的概念的清晰理解时,理解该想法的基本原理是关键。