熊猫: Python支持内置库Pandas ,执行数据分析和操作是一种快速有效的方式。 Pandas库处理一维数组(称为系列)和多维数组(称为数据框)中可用的数据。它提供了多种功能和实用程序来执行数据转换和操作。使用numpy模块进行统计建模、过滤、文件操作、排序以及导入或导出是Pandas库的一些关键功能。以更加用户友好的方式处理和挖掘大数据。
PostgreSQL:它是一个开源的关系型数据库管理系统,主要用于各种应用程序的数据存储。 PostgreSQL使用较小的数据集执行数据操作,例如以更简化和更快的方式排序、插入、更新、删除。它通过SQL查询模拟数据分析和转换。它提供灵活的数据存储和复制,具有更高的安全性和完整性。它确保的主要功能是处理并发事务的原子性、一致性、隔离性和持久性 (ACID)。
表现
为了比较两个模块的性能,我们将对以下数据集执行一些操作:
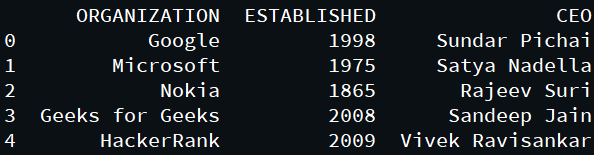
该数据集可以加载到相应的帧中,然后可以针对不同的操作计算它们的性能:
- Select:显示数据集的所有行
Python3
# import required modules
import time
import psycopg2
import pandas
# connect to server and load SQL database
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
db = conn.cursor()
# load pandas dataset
df = pandas.read_csv('gfg.csv')
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
db.execute("SELECT * FROM gfg")
print(db.fetchall())
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print(df)
end = time.time()
print('Time Taken:', end-begin)Python3
# import required modules
import time
import psycopg2
import pandas
# connect to server and load SQL database
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
# load pandas dataset
df = pandas.read_csv('gfg.csv')
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
print('Sorting data...')
cur.execute("SELECT * FROM gfg order by ESTABLISHED")
print(cur.fetchall())
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print('Sorting data...')
df.sort_values(by=['ESTABLISHED'], inplace=True)
print(df)
end = time.time()
print('Time Taken:', end-begin)Python3
# import required modules
import time
import psycopg2
import pandas
# connect to server and load SQL database
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
# load pandas dataset
df = pandas.read_csv('gfg.csv')
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
cur.execute("SELECT * FROM gfg where ESTABLISHED < 2000")
print(cur.fetchall())
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print(df[df['ESTABLISHED'] < 2000])
end = time.time()
print('Time Taken:', end-begin)Python3
# import required modules
import time
import psycopg2
import pandas
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
# connect to server and load SQL database
print('Loading SQL dataset...')
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print('Loading pandas dataset...')
# load pandas dataset
df = pandas.read_csv('gfg.csv')
end = time.time()
print('Time Taken:', end-begin)输出:
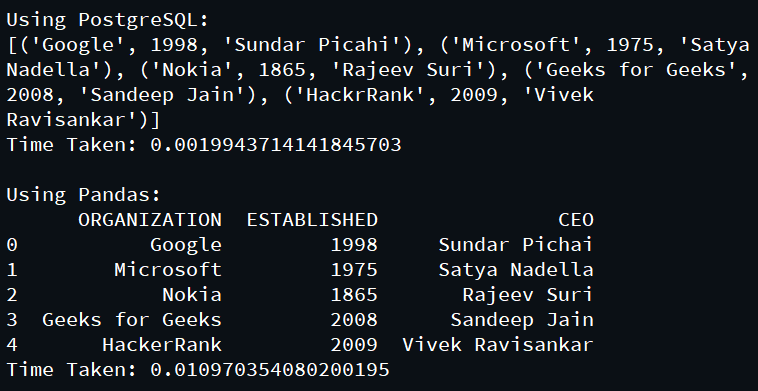
- 排序:按升序对数据进行排序。
蟒蛇3
# import required modules
import time
import psycopg2
import pandas
# connect to server and load SQL database
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
# load pandas dataset
df = pandas.read_csv('gfg.csv')
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
print('Sorting data...')
cur.execute("SELECT * FROM gfg order by ESTABLISHED")
print(cur.fetchall())
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print('Sorting data...')
df.sort_values(by=['ESTABLISHED'], inplace=True)
print(df)
end = time.time()
print('Time Taken:', end-begin)
输出:

- 过滤器:从数据集中提取一些行。
蟒蛇3
# import required modules
import time
import psycopg2
import pandas
# connect to server and load SQL database
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
# load pandas dataset
df = pandas.read_csv('gfg.csv')
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
cur.execute("SELECT * FROM gfg where ESTABLISHED < 2000")
print(cur.fetchall())
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print(df[df['ESTABLISHED'] < 2000])
end = time.time()
print('Time Taken:', end-begin)
输出:

- 加载:加载数据集。
蟒蛇3
# import required modules
import time
import psycopg2
import pandas
print('\nUsing PostgreSQL:')
# computing time taken by PostgreSQL
begin = time.time()
# connect to server and load SQL database
print('Loading SQL dataset...')
db = psycopg2.connect(database="postgres",
user="postgres",
password="12345",
host="127.0.0.1",
port="5432")
cur = db.cursor()
end = time.time()
print('Time Taken:', end-begin)
print('\nUsing Pandas:')
# computing time taken by Pandas
begin = time.time()
print('Loading pandas dataset...')
# load pandas dataset
df = pandas.read_csv('gfg.csv')
end = time.time()
print('Time Taken:', end-begin)
输出:

下表说明了执行这些操作所需的时间:
| Query |
PostgreSQL (Time in seconds) |
Pandas (Time in seconds) |
|---|---|---|
| Select | 0.0019 | 0.0109 |
| Sort | 0.0009 | 0.0069 |
| Filter | 0.0019 | 0.0109 |
| Load | 0.0728 | 0.0059 |
因此,我们可以得出结论,除了加载操作之外,与PostgreSQL相比, pandas模块在几乎所有操作中都很慢。
熊猫 VS PostgreSQL
|
Pandas |
PostgreSQL |
|---|---|
| Setup is easy. | Setup requires tuning and optimization of the query. |
| Complexity is less since it is just a package that needs to be imported. | Configuration and database configurations increase the complexity and time of execution. |
| Math, statistics, and procedural approaches like UDF are handled efficiently. | Math, statistics, and procedural approaches like UDF are not performed well enough. |
| Reliability and scalability are less. | Reliability and scalability are much better. |
| Only technically knowledgeable individuals can perform data manipulation operations. | Easy to read, understand since SQL is a structured language. |
| Cannot be easily integrated with other languages and applications. | Can be easily integrated to provide support with all languages. |
| Security is compromised. | Security is higher due to ACID properties. |
因此,在进行数据检索、处理、连接、过滤等简单数据操作的地方,可以认为 PostgreSQL 更好且易于使用。但是,对于大型数据挖掘和操作,查询优化,争用大于其简单性,因此 Pandas 的性能要好得多。