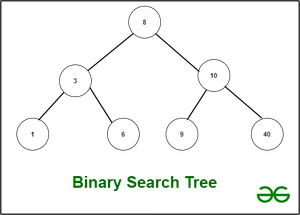
1. 二叉搜索树:
无环图通常用于说明二叉搜索树。树由节点组成。二叉树中的每个节点的子节点不超过两个。根据 BST,每个节点的值都严格高于其左孩子的值,并严格低于其右孩子的值。也就是说,我们可以按排序顺序遍历所有 BST 值。此外,此数据结构中不允许出现重复值。
二叉搜索树有两种类型:平衡的和不平衡的。
假设一个 BST 中的节点数为 n。 O(n) 是插入和删除操作的最坏情况。但是,在平衡二叉搜索树中,例如 AVL 或红黑树,类似操作的时间复杂度为 O(log(n))。另一个要记住的重要一点是,构建一个具有 n 个节点的 BST 需要 O(n * log(n)) 时间。我们必须插入一个节点 n 次,每次都花费 O(log(n))。二叉搜索树的主要好处是我们可以在 O(n) 时间内遍历它并按排序顺序接收我们的所有值。
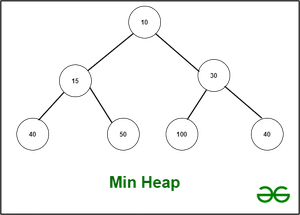
2.堆树:
堆是一棵完全二叉树。
如果节点与根节点之间的距离为 k,则该节点位于树的第 k 层。根的级别为零。在第 k 级,可以存在的最大节点数为 2^k。完全二叉树在每一层都有最大数量的节点。除了最后一层,也必须从左到右填充。记住完全二叉树总是平衡的很重要。
堆与二叉搜索树不同。另一方面,堆不是有序的数据结构。堆通常表示为计算机内存中的数字数组。可能有一个最小堆或最大堆堆。尽管最小堆和最大堆的特征几乎相同,但最大堆的树根是最大的,最小堆的最小。同样,Max-Heap 的基本规则是每个节点的子树都有小于或等于根节点的值。另一方面,Min-Heap 正好相反。这也意味着堆接受重复项。

二叉搜索树与堆:
根本区别在于二叉搜索树不允许重复,而堆允许。 BST 是有序的,而 Heap 不是。因此,如果顺序很重要,那么 BST 是必经之路。如果订单不重要,但我们需要知道插入和删除数据将花费 O(log(n)) 时间,Heap 会确保这会发生。如果树完全不平衡,在二叉搜索树中这可能需要 O(n) 时间(链是最坏的情况)。此外,虽然 Heap 可以在线性时间内构建,但 BST 需要 O(n * log(n)) 构建。
PriorityQueue 和 TreeMap 是这些结构的 Java 实现。默认情况下,PriorityQueue 是一个最大堆。 TreeMap 的主干是一个平衡的二叉搜索树。红黑树用于实现它。