您还可以阅读我们之前讨论过的关于上下文无关语法分类的文章。
Çontext˚FREEģrammars(CFGS)被分类基于:
- 派生树的数量
- 字符串
根据派生树的数量,CFG 被细分为 2 种类型:
- 歧义文法
- 明确的语法
歧义语法:甲CFG是如果存在对于给定的输入字符串即超过一个派生树到所述暧昧,多于一个L EFT中号OST d erivationŤREE(LMDT)或R飞行中号OST d erivationŤREE(RMDT)。定义: G = (V,T,P,S) 是一个 CFG,当且仅当 T* 中存在一个字符串比解析树上的字符串多。
其中 V 是一组有限的变量。
T 是一个有限的终端集。
P 是形式为 A -> α 的有限产生式集合,其中 A 是一个变量,而 α ∈ (V ∪ T)* S 是一个称为起始符号的指定变量。例如: 1. 让我们考虑这个语法: E -> E+E|id
我们可以从这个语法创建 2 个解析树来获得一个字符串id+id+id :
以下是最左推导生成的2个解析树:
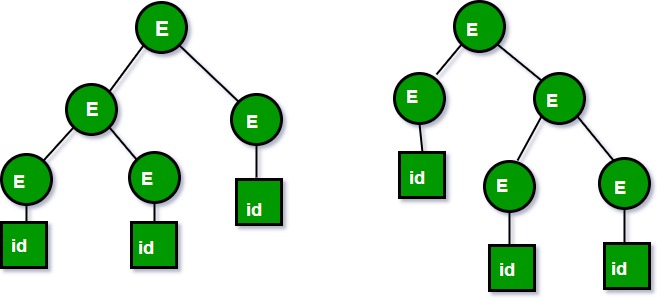
上述两种解析树都来自相同的语法规则,但两种解析树是不同的。因此语法是有歧义的。 2. 现在让我们考虑以下语法:
Set of alphabets ∑ = {0,…,9, +, *, (, )}
E -> I
E -> E + E
E -> E * E
E -> (E)
I -> ε | 0 | 1 | … | 9
从上面的语法 String 3*2+5可以通过两种方式推导出来:
I) First leftmost derivation II) Second leftmost derivation
E=>E*E E=>E+E
=>I*E =>E*E+E
=>3*E+E =>I*E+E
=>3*I+E =>3*E+E
=>3*2+E =>3*I+E
=>3*2+I =>3*2+I
=>3*2+5 =>3*2+5
下面是一些歧义语法的例子:
- S-> aS |Sa| Є
- E-> E + E | E*E| ID
- A -> AA | (一) |一种
- S -> SS|AB , A -> Aa|a , B -> Bb|b
而以下语法是明确的:
- S -> (L) | a, L -> LS |秒
- S -> AA , A -> aA , A -> b
固有歧义语言:让 L 成为上下文无关语言 (CFL)。如果每个具有语言 L = L(G) 的上下文无关文法 G 都是歧义的,则称 L 是固有歧义的语言。歧义是语法而非语言的属性。歧义语法不太可能对编程语言有用,因为同一个字符串(程序)的两个(或更多)解析树结构意味着该程序有两种不同的含义(可执行程序)。
一种固有的歧义语言绝对不适合作为一种编程语言,因为我们没有任何办法为其所有程序固定一个独特的结构。
例如,
L = {anbncm} ∪ {anbmcm} 注意:文法的歧义是不可判定的,即没有特定的算法来消除文法的歧义,但我们可以通过以下方式消除歧义:消除文法歧义,即重写文法,使得文法表示的语言字符串只有一个派生或解析树可能。