本文重点介绍如何解析给定的 XML 文件并以结构化的方式从中提取一些有用的数据。
XML: XML 代表可扩展标记语言。它旨在存储和传输数据。它被设计为人类和机器可读。这就是为什么 XML 的设计目标强调 Internet 上的简单性、通用性和可用性。
本教程中要解析的 XML 文件实际上是一个 RSS 提要。
RSS: RSS(Rich Site Summary,通常称为Really Simple Syndication)使用一系列标准的网络提要格式来发布经常更新的信息,如博客条目、新闻标题、音频、视频。 RSS 是 XML 格式的纯文本。
- RSS 格式本身相对容易被自动化流程和人类阅读。
- 本教程中处理的 RSS 是来自流行新闻网站的热门新闻故事的 RSS 提要。你可以在这里查看。我们的目标是处理此 RSS 提要(或 XML 文件)并将其保存为其他格式以备将来使用。
Python模块:本文将重点介绍在Python使用内置的 xml 模块来解析 XML,主要关注该模块的 ElementTree XML API。
执行:
#Python code to illustrate parsing of XML files
# importing the required modules
import csv
import requests
import xml.etree.ElementTree as ET
def loadRSS():
# url of rss feed
url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml'
# creating HTTP response object from given url
resp = requests.get(url)
# saving the xml file
with open('topnewsfeed.xml', 'wb') as f:
f.write(resp.content)
def parseXML(xmlfile):
# create element tree object
tree = ET.parse(xmlfile)
# get root element
root = tree.getroot()
# create empty list for news items
newsitems = []
# iterate news items
for item in root.findall('./channel/item'):
# empty news dictionary
news = {}
# iterate child elements of item
for child in item:
# special checking for namespace object content:media
if child.tag == '{http://search.yahoo.com/mrss/}content':
news['media'] = child.attrib['url']
else:
news[child.tag] = child.text.encode('utf8')
# append news dictionary to news items list
newsitems.append(news)
# return news items list
return newsitems
def savetoCSV(newsitems, filename):
# specifying the fields for csv file
fields = ['guid', 'title', 'pubDate', 'description', 'link', 'media']
# writing to csv file
with open(filename, 'w') as csvfile:
# creating a csv dict writer object
writer = csv.DictWriter(csvfile, fieldnames = fields)
# writing headers (field names)
writer.writeheader()
# writing data rows
writer.writerows(newsitems)
def main():
# load rss from web to update existing xml file
loadRSS()
# parse xml file
newsitems = parseXML('topnewsfeed.xml')
# store news items in a csv file
savetoCSV(newsitems, 'topnews.csv')
if __name__ == "__main__":
# calling main function
main()
上面的代码将:
- 从指定的 URL 加载 RSS 提要并将其保存为 XML 文件。
- 解析 XML 文件以将新闻保存为字典列表,其中每个字典都是一个新闻项目。
- 将新闻项目保存到 CSV 文件中。
让我们试着分块理解代码:
- 加载和保存 RSS 提要
def loadRSS(): # url of rss feed url = 'http://www.hindustantimes.com/rss/topnews/rssfeed.xml' # creating HTTP response object from given url resp = requests.get(url) # saving the xml file with open('topnewsfeed.xml', 'wb') as f: f.write(resp.content)在这里,我们首先通过向 RSS 提要的 URL 发送 HTTP 请求来创建一个 HTTP 响应对象。响应的内容现在包含我们在本地目录中保存为topnewsfeed.xml的 XML 文件数据。
有关请求模块如何工作的更多见解,请关注这篇文章:
使用Python 的GET 和 POST 请求 - 解析 XML
我们已经创建了parseXML()函数来解析 XML 文件。我们知道 XML 是一种固有的分层数据格式,最自然的表示方式是用树来表示。例如,请看下图: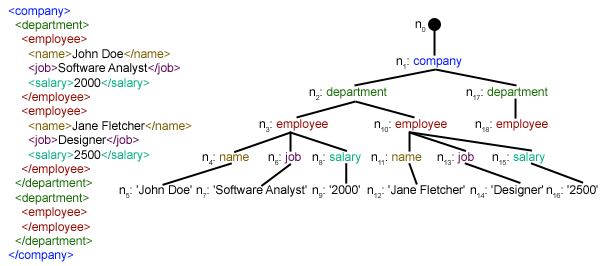
在这里,我们使用xml.etree.ElementTree (简称 ET)模块。为此,Element Tree 有两个类——ElementTree代表整个 XML
文档作为一棵树,元素代表这棵树中的单个节点。与整个文档的交互(读写文件)通常在ElementTree级别上完成。与单个 XML 元素及其子元素的交互是在元素级别完成的。好的,让我们现在通过parseXML()函数:
tree = ET.parse(xmlfile)在这里,我们通过解析传递的xmlfile 来创建一个ElementTree对象。
root = tree.getroot()getroot()函数将树的根作为Element对象返回。
for item in root.findall('./channel/item'):现在,一旦您查看了 XML 文件的结构,您就会注意到我们只对item元素感兴趣。
./channel/item实际上是 XPath 语法(XPath 是一种用于寻址 XML 文档部分的语言)。在这里,我们要查找根元素(由“.”表示)的通道子项的所有项孙项。
您可以在此处阅读有关支持的 XPath 语法的更多信息。for item in root.findall('./channel/item'): # empty news dictionary news = {} # iterate child elements of item for child in item: # special checking for namespace object content:media if child.tag == '{http://search.yahoo.com/mrss/}content': news['media'] = child.attrib['url'] else: news[child.tag] = child.text.encode('utf8') # append news dictionary to news items list newsitems.append(news)现在,我们知道我们正在遍历item元素,其中每个item元素包含一个新闻。因此,我们创建了一个空的新闻字典,我们将在其中存储有关新闻项目的所有可用数据。要遍历元素的每个子元素,我们只需遍历它,如下所示:
for child in item:现在,请注意此处的示例 item 元素:

我们将不得不单独处理命名空间标签,因为它们在解析时会扩展到它们的原始值。所以,我们做这样的事情:
if child.tag == '{http://search.yahoo.com/mrss/}content': news['media'] = child.attrib['url']child.attrib是与元素相关的所有属性的字典。在这里,我们对media:content命名空间标签的url属性感兴趣。
现在,对于所有其他孩子,我们只需:news[child.tag] = child.text.encode('utf8')child.tag包含子元素的名称。 child.text存储该子元素内的所有文本。因此,最后,示例 item 元素被转换为字典,如下所示:
{'description': 'Ignis has a tough competition already, from Hyun.... , 'guid': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... , 'link': 'http://www.hindustantimes.com/autos/maruti-ignis-launch.... , 'media': 'http://www.hindustantimes.com/rf/image_size_630x354/HT/... , 'pubDate': 'Thu, 12 Jan 2017 12:33:04 GMT ', 'title': 'Maruti Ignis launches on Jan 13: Five cars that threa..... }然后,我们只需将此 dict 元素附加到列表newsitems 。
最后,返回此列表。 - 将数据保存到 CSV 文件
现在,我们只需将新闻项目列表保存到 CSV 文件,以便将来可以使用savetoCSV()函数轻松使用或修改它。要了解有关将字典元素写入 CSV 文件的更多信息,请阅读本文:
在Python处理 CSV 文件
所以现在,这是我们格式化的数据现在的样子: 
如您所见,分层的 XML 文件数据已转换为简单的 CSV 文件,以便所有新闻报道都以表格的形式存储。这也使得扩展数据库变得更容易。
此外,您可以直接在他们的应用程序中使用类似 JSON 的数据!这是从不提供公共 API 但提供一些 RSS 提要的网站中提取数据的最佳选择。
上面文章中使用的所有代码和文件都可以在这里找到。
接下来是什么?
- 您可以查看以上示例中使用的新闻网站的更多 RSS 提要。您也可以尝试通过解析其他 rss 提要来创建上述示例的扩展版本。
- 你是板球迷吗?那么这个RSS提要一定是你的兴趣!您可以解析此 XML 文件以获取有关现场板球比赛的信息并用于制作桌面通知程序!
HTML 和 XML 测验