你们所有人都必须熟悉什么是 PDF。事实上,它们是最重要和最广泛使用的数字媒体之一。 PDF 代表便携式文档格式。它使用.pdf扩展名。它用于可靠地呈现和交换文档,独立于软件、硬件或操作系统。
由Adobe发明,PDF 现在是由国际标准化组织 (ISO) 维护的开放标准。 PDF 可以包含链接和按钮、表单域、音频、视频和业务逻辑。
在本文中,我们将学习如何进行各种操作,例如:
- 从 PDF 中提取文本
- 旋转 PDF 页面
- 合并 PDF
- 拆分PDF
- 给PDF页面添加水印
使用简单的Python脚本!
安装
我们将使用第三方模块 PyPDF2。
PyPDF2 是一个构建为 PDF 工具包的Python库。它能够:
- 提取文档信息(标题、作者……)
- 逐页拆分文档
- 逐页合并文档
- 裁剪页面
- 将多个页面合并为一个页面
- 加密和解密PDF文件
- 和更多!
要安装 PyPDF2,请从命令行运行以下命令:
此模块名称区分大小写,因此请确保y为小写,其他所有内容均为大写。本教程/文章中使用的所有代码和 PDF 文件均可在此处获得。
1.从PDF文件中提取文本
Python
# importing required modules
import PyPDF2
# creating a pdf file object
pdfFileObj = open('example.pdf', 'rb')
# creating a pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# printing number of pages in pdf file
print(pdfReader.numPages)
# creating a page object
pageObj = pdfReader.getPage(0)
# extracting text from page
print(pageObj.extractText())
# closing the pdf file object
pdfFileObj.close()Python
# importing the required modules
import PyPDF2
def PDFrotate(origFileName, newFileName, rotation):
# creating a pdf File object of original pdf
pdfFileObj = open(origFileName, 'rb')
# creating a pdf Reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# creating a pdf writer object for new pdf
pdfWriter = PyPDF2.PdfFileWriter()
# rotating each page
for page in range(pdfReader.numPages):
# creating rotated page object
pageObj = pdfReader.getPage(page)
pageObj.rotateClockwise(rotation)
# adding rotated page object to pdf writer
pdfWriter.addPage(pageObj)
# new pdf file object
newFile = open(newFileName, 'wb')
# writing rotated pages to new file
pdfWriter.write(newFile)
# closing the original pdf file object
pdfFileObj.close()
# closing the new pdf file object
newFile.close()
def main():
# original pdf file name
origFileName = 'example.pdf'
# new pdf file name
newFileName = 'rotated_example.pdf'
# rotation angle
rotation = 270
# calling the PDFrotate function
PDFrotate(origFileName, newFileName, rotation)
if __name__ == "__main__":
# calling the main function
main()Python
# importing required modules
import PyPDF2
def PDFmerge(pdfs, output):
# creating pdf file merger object
pdfMerger = PyPDF2.PdfFileMerger()
# appending pdfs one by one
for pdf in pdfs:
pdfmerger.append(pdf)
# writing combined pdf to output pdf file
with open(output, 'wb') as f:
pdfMerger.write(f)
def main():
# pdf files to merge
pdfs = ['example.pdf', 'rotated_example.pdf']
# output pdf file name
output = 'combined_example.pdf'
# calling pdf merge function
PDFmerge(pdfs=pdfs, output=output)
if __name__ == "__main__":
# calling the main function
main()Python
# importing the required modules
import PyPDF2
def PDFsplit(pdf, splits):
# creating input pdf file object
pdfFileObj = open(pdf, 'rb')
# creating pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# starting index of first slice
start = 0
# starting index of last slice
end = splits[0]
for i in range(len(splits)+1):
# creating pdf writer object for (i+1)th split
pdfWriter = PyPDF2.PdfFileWriter()
# output pdf file name
outputpdf = pdf.split('.pdf')[0] + str(i) + '.pdf'
# adding pages to pdf writer object
for page in range(start,end):
pdfWriter.addPage(pdfReader.getPage(page))
# writing split pdf pages to pdf file
with open(outputpdf, "wb") as f:
pdfWriter.write(f)
# interchanging page split start position for next split
start = end
try:
# setting split end position for next split
end = splits[i+1]
except IndexError:
# setting split end position for last split
end = pdfReader.numPages
# closing the input pdf file object
pdfFileObj.close()
def main():
# pdf file to split
pdf = 'example.pdf'
# split page positions
splits = [2,4]
# calling PDFsplit function to split pdf
PDFsplit(pdf, splits)
if __name__ == "__main__":
# calling the main function
main()Python
# importing the required modules
import PyPDF2
def add_watermark(wmFile, pageObj):
# opening watermark pdf file
wmFileObj = open(wmFile, 'rb')
# creating pdf reader object of watermark pdf file
pdfReader = PyPDF2.PdfFileReader(wmFileObj)
# merging watermark pdf's first page with passed page object.
pageObj.mergePage(pdfReader.getPage(0))
# closing the watermark pdf file object
wmFileObj.close()
# returning watermarked page object
return pageObj
def main():
# watermark pdf file name
mywatermark = 'watermark.pdf'
# original pdf file name
origFileName = 'example.pdf'
# new pdf file name
newFileName = 'watermarked_example.pdf'
# creating pdf File object of original pdf
pdfFileObj = open(origFileName, 'rb')
# creating a pdf Reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# creating a pdf writer object for new pdf
pdfWriter = PyPDF2.PdfFileWriter()
# adding watermark to each page
for page in range(pdfReader.numPages):
# creating watermarked page object
wmpageObj = add_watermark(mywatermark, pdfReader.getPage(page))
# adding watermarked page object to pdf writer
pdfWriter.addPage(wmpageObj)
# new pdf file object
newFile = open(newFileName, 'wb')
# writing watermarked pages to new file
pdfWriter.write(newFile)
# closing the original pdf file object
pdfFileObj.close()
# closing the new pdf file object
newFile.close()
if __name__ == "__main__":
# calling the main function
main()上述程序的输出如下所示:
20
PythonBasics
S.R.Doty
August27,2008
Contents
1Preliminaries
4
1.1WhatisPython?...................................
..4
1.2Installationanddocumentation....................
.........4 [and some more lines...]让我们试着分块理解上面的代码:
pdfFileObj = open('example.pdf', 'rb')- 我们以二进制模式打开example.pdf 。并将文件对象保存为pdfFileObj 。
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)- 在这里,我们创建 PyPDF2 模块的PdfFileReader类的对象,并传递 pdf 文件对象并获取 pdf 阅读器对象。
print(pdfReader.numPages)- numPages属性给出了 pdf 文件中的页数。例如,在我们的例子中,它是 20(见第一行输出)。
pageObj = pdfReader.getPage(0)- 现在,我们创建一个 PyPDF2 模块的PageObject类的对象。 pdf 阅读器对象具有函数getPage() ,它以页码(从索引 0 开始)作为参数并返回页面对象。
print(pageObj.extractText())- Page 对象具有从 pdf 页面中提取文本的函数extractText() 。
pdfFileObj.close()- 最后,我们关闭pdf文件对象。
注意:虽然 PDF 文件非常适合以人们易于打印和阅读的方式布置文本,但软件解析为纯文本并不容易。因此,PyPDF2 在从 PDF 中提取文本时可能会出错,甚至可能根本无法打开某些 PDF。不幸的是,您对此无能为力。 PyPDF2 可能根本无法处理您的某些特定 PDF 文件。
2. 旋转 PDF 页面
Python
# importing the required modules
import PyPDF2
def PDFrotate(origFileName, newFileName, rotation):
# creating a pdf File object of original pdf
pdfFileObj = open(origFileName, 'rb')
# creating a pdf Reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# creating a pdf writer object for new pdf
pdfWriter = PyPDF2.PdfFileWriter()
# rotating each page
for page in range(pdfReader.numPages):
# creating rotated page object
pageObj = pdfReader.getPage(page)
pageObj.rotateClockwise(rotation)
# adding rotated page object to pdf writer
pdfWriter.addPage(pageObj)
# new pdf file object
newFile = open(newFileName, 'wb')
# writing rotated pages to new file
pdfWriter.write(newFile)
# closing the original pdf file object
pdfFileObj.close()
# closing the new pdf file object
newFile.close()
def main():
# original pdf file name
origFileName = 'example.pdf'
# new pdf file name
newFileName = 'rotated_example.pdf'
# rotation angle
rotation = 270
# calling the PDFrotate function
PDFrotate(origFileName, newFileName, rotation)
if __name__ == "__main__":
# calling the main function
main()
在这里你可以看到rotated_example.pdf的第一页在旋转后的样子(右图):
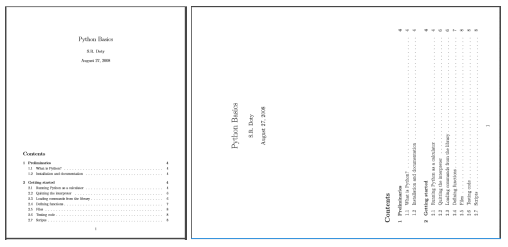
与上述代码相关的一些要点:
- 对于旋转,我们首先创建原始 pdf 的 pdf 阅读器对象。
pdfWriter = PyPDF2.PdfFileWriter()- 旋转的页面将被写入新的 pdf。为了写入 pdf,我们使用 PyPDF2 模块的PdfFileWriter类的对象。
for page in range(pdfReader.numPages):
pageObj = pdfReader.getPage(page)
pageObj.rotateClockwise(rotation)
pdfWriter.addPage(pageObj)- 现在,我们迭代原始pdf的每一页。我们通过pdf阅读器类的getPage()方法获取页面对象。现在,我们通过页面对象类的rotateClockwise()方法旋转页面。然后,我们通过传递旋转的页面对象,使用 pdf writer 类的addPage()方法将页面添加到 pdf writer 对象。
newFile = open(newFileName, 'wb')
pdfWriter.write(newFile)
pdfFileObj.close()
newFile.close()- 现在,我们必须将 pdf 页面写入一个新的 pdf 文件。首先,我们打开新的文件对象,并使用 pdf writer 对象的write()方法将 pdf 页面写入其中。最后,我们关闭原来的pdf文件对象和新的文件对象。
3.合并PDF文件
Python
# importing required modules
import PyPDF2
def PDFmerge(pdfs, output):
# creating pdf file merger object
pdfMerger = PyPDF2.PdfFileMerger()
# appending pdfs one by one
for pdf in pdfs:
pdfmerger.append(pdf)
# writing combined pdf to output pdf file
with open(output, 'wb') as f:
pdfMerger.write(f)
def main():
# pdf files to merge
pdfs = ['example.pdf', 'rotated_example.pdf']
# output pdf file name
output = 'combined_example.pdf'
# calling pdf merge function
PDFmerge(pdfs=pdfs, output=output)
if __name__ == "__main__":
# calling the main function
main()
上述程序的输出是一个合并的pdf,由合并example.pdf和rotated_example.pdf得到的combined_example.pdf 。
让我们来看看这个程序的重要方面:
pdfMerger = PyPDF2.PdfFileMerger()- 对于合并,我们使用预建类PyPDF2模块PdfFileMerger。
在这里,我们创建一个pdf合并类的对象pdfMerger
for pdf in pdfs:
pdfmerger.append(open(focus, "rb"))- 现在,我们使用append()方法将每个 pdf 的文件对象附加到 pdf 合并对象。
with open(output, 'wb') as f:
pdfMerger.write(f)- 最后,我们使用pdf合并对象的write方法将pdf页面写入输出pdf文件。
4. 拆分PDF文件
Python
# importing the required modules
import PyPDF2
def PDFsplit(pdf, splits):
# creating input pdf file object
pdfFileObj = open(pdf, 'rb')
# creating pdf reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# starting index of first slice
start = 0
# starting index of last slice
end = splits[0]
for i in range(len(splits)+1):
# creating pdf writer object for (i+1)th split
pdfWriter = PyPDF2.PdfFileWriter()
# output pdf file name
outputpdf = pdf.split('.pdf')[0] + str(i) + '.pdf'
# adding pages to pdf writer object
for page in range(start,end):
pdfWriter.addPage(pdfReader.getPage(page))
# writing split pdf pages to pdf file
with open(outputpdf, "wb") as f:
pdfWriter.write(f)
# interchanging page split start position for next split
start = end
try:
# setting split end position for next split
end = splits[i+1]
except IndexError:
# setting split end position for last split
end = pdfReader.numPages
# closing the input pdf file object
pdfFileObj.close()
def main():
# pdf file to split
pdf = 'example.pdf'
# split page positions
splits = [2,4]
# calling PDFsplit function to split pdf
PDFsplit(pdf, splits)
if __name__ == "__main__":
# calling the main function
main()
输出将是三个新的 PDF 文件,分别为split 1 (page 0,1), split 2(page 2,3), split 3(page 4-end) 。
上面的Python程序中没有使用新的函数或类。使用简单的逻辑和迭代,我们根据传递的列表splits创建了传递的pdf 的拆分。
5.给PDF页面添加水印
Python
# importing the required modules
import PyPDF2
def add_watermark(wmFile, pageObj):
# opening watermark pdf file
wmFileObj = open(wmFile, 'rb')
# creating pdf reader object of watermark pdf file
pdfReader = PyPDF2.PdfFileReader(wmFileObj)
# merging watermark pdf's first page with passed page object.
pageObj.mergePage(pdfReader.getPage(0))
# closing the watermark pdf file object
wmFileObj.close()
# returning watermarked page object
return pageObj
def main():
# watermark pdf file name
mywatermark = 'watermark.pdf'
# original pdf file name
origFileName = 'example.pdf'
# new pdf file name
newFileName = 'watermarked_example.pdf'
# creating pdf File object of original pdf
pdfFileObj = open(origFileName, 'rb')
# creating a pdf Reader object
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
# creating a pdf writer object for new pdf
pdfWriter = PyPDF2.PdfFileWriter()
# adding watermark to each page
for page in range(pdfReader.numPages):
# creating watermarked page object
wmpageObj = add_watermark(mywatermark, pdfReader.getPage(page))
# adding watermarked page object to pdf writer
pdfWriter.addPage(wmpageObj)
# new pdf file object
newFile = open(newFileName, 'wb')
# writing watermarked pages to new file
pdfWriter.write(newFile)
# closing the original pdf file object
pdfFileObj.close()
# closing the new pdf file object
newFile.close()
if __name__ == "__main__":
# calling the main function
main()
这是原始(左)和带水印(右)pdf文件的第一页的样子:

- 所有过程与页面旋转示例相同。唯一的区别是:
wmpageObj = add_watermark(mywatermark, pdfReader.getPage(page))- 使用add_watermark()函数将页面对象转换为带水印的页面对象。
- 让我们试着理解add_watermark()函数:
wmFileObj = open(wmFile, 'rb')
pdfReader = PyPDF2.PdfFileReader(wmFileObj)
pageObj.mergePage(pdfReader.getPage(0))
wmFileObj.close()
return pageObj- 首先,我们创建一个watermark.pdf的 pdf 阅读器对象。对于传入的page对象,我们使用mergePage()函数,传入watermark pdf reader对象第一页的page对象。这将在传递的页面对象上覆盖水印。
在这里,我们结束了这个关于在Python处理 PDF 文件的长教程。
现在,您可以轻松创建自己的 PDF 管理器!
参考:
- https://automatetheboringstuff.com/chapter13/
- https://pythonhosted.org/PyPDF2/