介绍
下载管理器基本上是一个专门用于从互联网下载独立文件的计算机程序。在这里,我们将借助Python的线程创建一个简单的下载管理器。使用多线程可以同时从不同线程以块的形式下载文件。为了实现这一点,我们将创建一个简单的命令行工具,它接受文件的 URL,然后下载它。
先决条件
安装了Python 的Windows 机器。
设置
从命令提示符下载下面提到的包。
- Click 包: Click 是一个Python包,用于使用尽可能少的代码创建漂亮的命令行界面。它是“命令行界面创建工具包”。
pip install click - 请求包:在此工具中,我们将根据 URL(HTTP 地址)下载文件。 Requests 是一个用Python编写的 HTTP 库,它允许您发送 HTTP 请求。您可以使用简单的Python字典添加标题、表单数据、多部分文件和参数,并以相同的方式访问响应数据。
pip install requests - 线程包:要使用线程,我们需要线程包。
pip install threading
执行
(注意:为了便于理解,程序已被拆分为多个部分。确保在运行代码时没有遗漏任何部分代码。)
- 在编辑器中创建新的Python文件
- 首先导入需要编写的包
#N ote: This code will not work on online IDE
# Importing the required packages
import click
import requests
import threading
# The below code is used for each chunk of file handled
# by each thread for downloading the content from specified
# location to storage
def Handler(start, end, url, filename):
# specify the starting and ending of the file
headers = {'Range': 'bytes=%d-%d' % (start, end)}
# request the specified part and get into variable
r = requests.get(url, headers=headers, stream=True)
# open the file and write the content of the html page
# into file.
with open(filename, "r+b") as fp:
fp.seek(start)
var = fp.tell()
fp.write(r.content)
现在我们将实现 download_file函数的实际功能。
- 第一步是使用 click.command() 装饰函数,以便我们可以添加命令行参数。我们还可以为各个命令提供选项。
- 对于我们在输入命令 –help 时的实现,我们将显示可以使用的选项。在我们的程序中有两个选项可以使用。一个是“number_of_threads”,另一个是“name”。 “number_of_threads”默认为4。要更改它,我们可以在运行程序时指定。
- 给出了“name”选项,以便我们可以为要下载的文件命名。可以使用 click.argument() 指定函数的参数。
- 对于我们的程序,我们需要提供我们要下载的文件的 URL。
#Note: This code will not work on online IDE
@click.command(help="It downloads the specified file with specified name")
@click.option('—number_of_threads',default=4, help="No of Threads")
@click.option('--name',type=click.Path(),help="Name of the file with extension")
@click.argument('url_of_file',type=click.Path())
@click.pass_context
def download_file(ctx,url_of_file,name,number_of_threads):
以下代码位于“download_file”函数。
- 在这个函数,我们首先检查“名称”。如果未给出“名称”,则使用来自 url 的名称。
- 下一步是连接到 URL 并获取内容的内容和大小。
r = requests.head(url_of_file)
if name:
file_name = name
else:
file_name = url_of_file.split('/')[-1]
try:
file_size = int(r.headers['content-length'])
except:
print "Invalid URL"
return
创建具有内容大小的文件
part = int(file_size) / number_of_threads
fp = open(file_name, "wb")
fp.write('\0' * file_size)
fp.close()
现在,我们创建线程,并通过其具有的主要功能的处理函数:
for i in range(number_of_threads):
start = part * i
end = start + part
# create a Thread with start and end locations
t = threading.Thread(target=Handler,
kwargs={'start': start, 'end': end, 'url': url_of_file, 'filename': file_name})
t.setDaemon(True)
t.start()
最后加入线程并从 main 调用“download_file”函数
main_thread = threading.current_thread()
for t in threading.enumerate():
if t is main_thread:
continue
t.join()
print '%s downloaded' % file_name
if __name__ == '__main__':
download_file(obj={})
我们完成了编码部分,现在按照下面显示的命令运行 .py 文件。
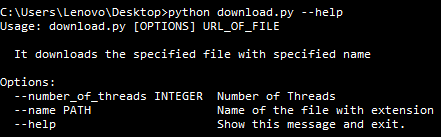
“python filename.py” –-help该命令显示了单击命令工具的“用法”以及该工具可以接受的选项。
下面是我们尝试从 URL 下载 jpg 图像文件并给出名称和 number_of_threads 的示例命令。

最后,我们成功地完成了它,这是在Python构建一个简单的多线程下载管理器的方法之一。