Twitter ……你可能很擅长一直查看这个社交媒体,但如果有人要求你在短短 45 分钟内设计这个巨大的系统怎么办? (这是一个笑话…….lolz? )。
是的,这就是您在系统设计轮面试中应该做的事情。我们不是在开玩笑,你需要告诉你如何设计一个像 Twitter 这样的系统(在 45 分钟或更短的时间内),有数百名软件工程师在它上面工作了十年?设计 Twitter(或 Facebook 提要或 Facebook 搜索……)是面试官问候选人的一个非常常见的问题。许多候选人更害怕这一轮而不是编码轮,因为他们不知道在有限的时间内应该涵盖哪些主题和权衡。首先,请记住,系统设计回合是非常开放的,没有标准答案之类的东西。即使是同样的问题,你也会与不同的面试官进行不同的讨论。

在这个博客中,我们将讨论如何设计一个像 Twitter 这样的网站,但在我们进一步讨论之前,我们希望您阅读文章“如何在面试中破解系统设计?”。它会让你知道这一轮是什么样子,你在这一轮中应该做什么,以及在面试官面前应该避免哪些错误。
现在让我们直接跳到这个问题“你会如何设计 Twitter? ”
你会如何设计推特?
当你在面试中被问到这个问题时,不要立即进入技术细节。不要朝一个方向跑,它只会在你和面试官之间制造混乱。大多数应聘者在这里犯了错误,然后他们立即开始列出一些工具或框架,如 MongoDB、Bootstrap、MapReduce 等。请记住,您的面试官想要关于您将如何解决问题的高级想法。您将使用什么工具并不重要,重要的是您如何定义问题、如何设计解决方案以及如何逐步分析问题。
您可以将自己置于从事实际项目的情况中。首先,定义问题并澄清问题陈述。在这个问题中,我们将把 Twitter 压缩为它的 MVP(最小可行产品)。没有人希望您设计整个服务。所以,我们只会设计 Twitter 的核心功能,而不是一切。
1. 讨论核心特性
所以先把整个系统分成几个核心组件,说说一些核心功能。如果你的面试官想包括其他一些功能,他/她会在那里提到。现在,我们将考虑 Twitter 上的以下功能……
- 用户应该能够在短短几秒钟内发推文。
- 用户应该能够看到推文时间线
- 时间轴:这可以分为三个部分……
- 用户时间线:用户查看他/她自己的推文和用户转发的推文。用户在其个人资料上访问时看到的推文。
- 主页时间线:这将显示用户关注的人的推文。 (当你登陆 twitter.com 时的推文)
- 搜索时间线:当用户搜索某些关键字或#tags 时,他们会看到与该特定关键字相关的推文。
- 用户应该能够关注另一个用户。
- 用户应该能够在几秒钟(5 秒)内发布数百万关注者的推文
2. Naive 解决方案(同步数据库查询)
为了设计像 Twitter 这样的大系统,我们将首先讨论 Naive 解决方案。这将有助于我们向高级架构迈进。您可以为以下两件事设计一个解决方案:
- 数据建模:您可以使用像 MySQL 这样的关系数据库,您可以考虑两个表user table (id, username)和一个tweet table[id, content, user(user table 的主键)] 。用户信息将存储在用户表中,每当用户发布一条消息时,它都会存储在推文表中。这里也需要两个关系。一个是用户可以互相关注,另一个是每个提要都有一个用户所有者。因此用户和推文表之间将存在一对多关系。
- 提供提要:您需要从用户关注的所有人那里获取所有提要,并按时间顺序呈现它们。
3. 架构的局限性(指出瓶颈)
您必须在推文表中执行一个大的选择语句,以获取特定用户的所有推文,无论他/她关注谁,这也是按时间顺序排列的。每次都这样做会产生问题,因为推文表将包含大量推文的大量内容。我们需要优化这个解决方案来解决这个问题,为此,我们将转向这个问题的高级解决方案。在此之前我们先了解一下Twitter的特点。
4. Twitter的特点(流量)
Twitter 每天有3 亿活跃用户。平均而言,每秒大约有 6,000条推文在 Twitter 上发布。每秒6, 00, 000 次查询以获取时间线。每个用户平均有 200 个关注者,一些用户(如某些名人)拥有数百万关注者。推特的这一特点明确了以下几点……
- 与写入相比,Twitter 具有大量读取,因此我们应该更加关注 Twitter 上大量读取的应用程序的可用性和规模。
- 我们可以考虑这种系统的最终一致性。如果用户看到他的追随者的推文有点延迟,这是完全可以的
- 空间不是问题,因为推文限制为 140 个字符。
高级解决方案
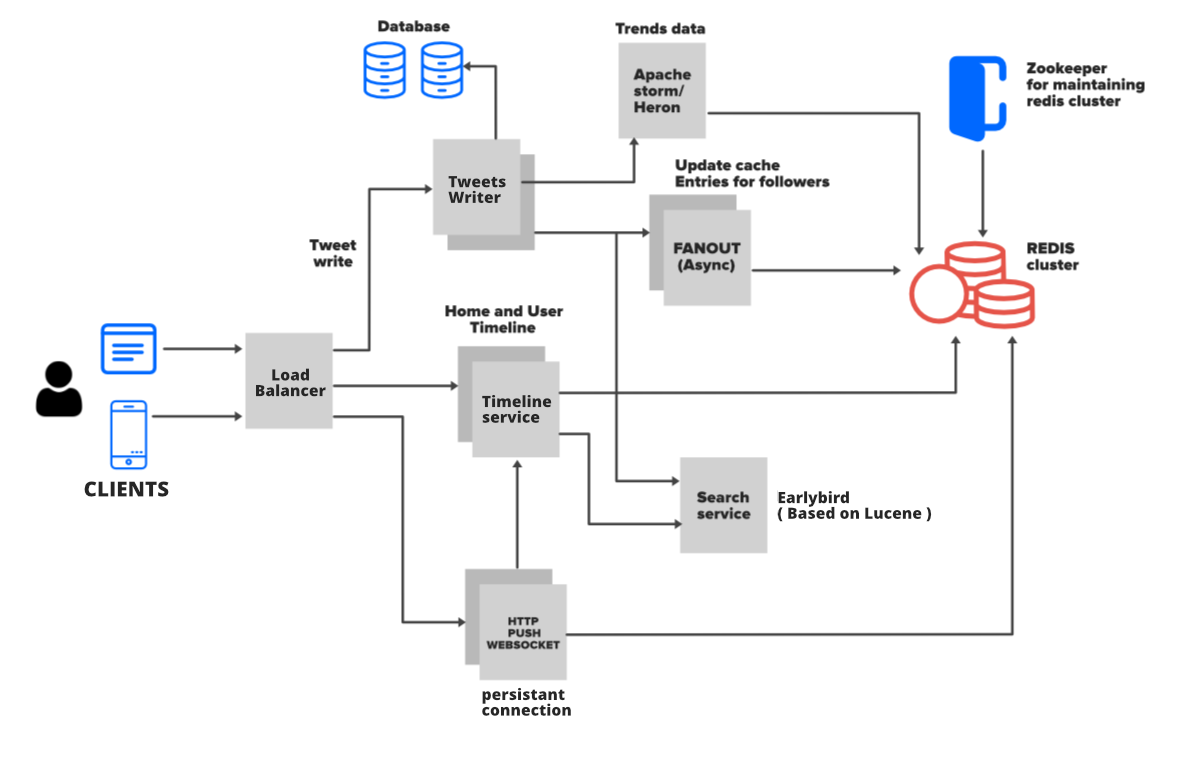
就像我们已经讨论过的那样,Twitter 是重读的,所以我们需要一个系统来让我们更快地阅读信息,并且它可以水平扩展。 Redis非常适合这种需求,但我们不能仅仅依赖于 Redis,因为我们还需要在数据库中存储推文和其他用户相关信息的副本。所以在这里我们将拥有 Twitter 的基本架构,它由三个表组成:用户表、推文表和关注者表。
- 每当用户在 Twitter 上创建个人资料时,该条目将存储在 User 表中。
- 用户发布的推文将与 User_id 一起存储在 Tweet 表中。此外,用户表将与推文表有一对多的关系。
- 当一个用户关注另一个用户时,它会存储在 Followers 表中,并将其缓存在 Redis 中。 User 表将与 Follower 表有一对多的关系。
1. 用户时间线架构
- 要获取用户时间线,只需转到用户表获取 user_id,在推文表中匹配此 user_id,然后获取所有推文。这也将包括转推,将转推保存为带有原始推文引用的推文。完成此操作后,按日期和时间对推文进行排序,然后在用户时间轴上显示信息。
- 正如我们已经讨论过的,Twitter 是重读的,所以上述方法并不总是有效。这里我们需要用到另一个层,即缓存层,我们会将用户时间线查询的数据保存在Redis中。此外,继续将推文保存在 Redis 中,这样当有人访问用户时间线时,他/她可以获得该用户发布的所有推文。从 Redis 获取数据要快得多,因此总是从 DB 获取数据没有多大用处。
2. 家庭时间线架构
- 用户主页时间线包含此人的所有最新推文以及用户关注的页面。好吧,在这里您可以简单地获取用户关注的用户,为每个关注者获取所有最新推文,然后合并所有推文,按日期和时间对所有这些推文进行排序,并将其显示在主页时间轴上。这种解决方案有一些缺点。 Twitter 主页的加载速度要快得多,而且这些查询对数据库的处理量更大,因此一旦推文表增长到数百万,这个庞大的搜索操作将花费更多的时间。现在让我们谈谈这个缺点的解决方案……
扇出方法:扇出只是意味着从一个点传播数据。让我们看看如何使用它。每当用户(Followee)发布推文时,都会进行大量预处理并将数据分发到不同用户(关注者)的主页时间线中。在此过程中,您不必进行任何数据库查询。你只需要通过user_id进入缓存,访问Redis中的home时间线数据即可。所以这个过程会更快更容易,因为它是我们在内存中获取推文列表的。这是这种方法的完整流程……- 用户 X 后面跟着三个人,这个用户有一个叫做用户时间线的缓存。 X 在推特上发了一些东西。
- 通过负载均衡器推文将流入后端服务器。
- 服务器节点将推文保存在数据库/缓存中
- 服务器节点将从缓存中获取所有关注用户 X 的用户。
- 服务器节点将这条推文注入到他的追随者的内存时间线中(扇出)
- 用户 X 的所有关注者都会在他们的时间线中看到用户 X 的推文。每次用户访问他/她的时间线时,它都会刷新和更新。
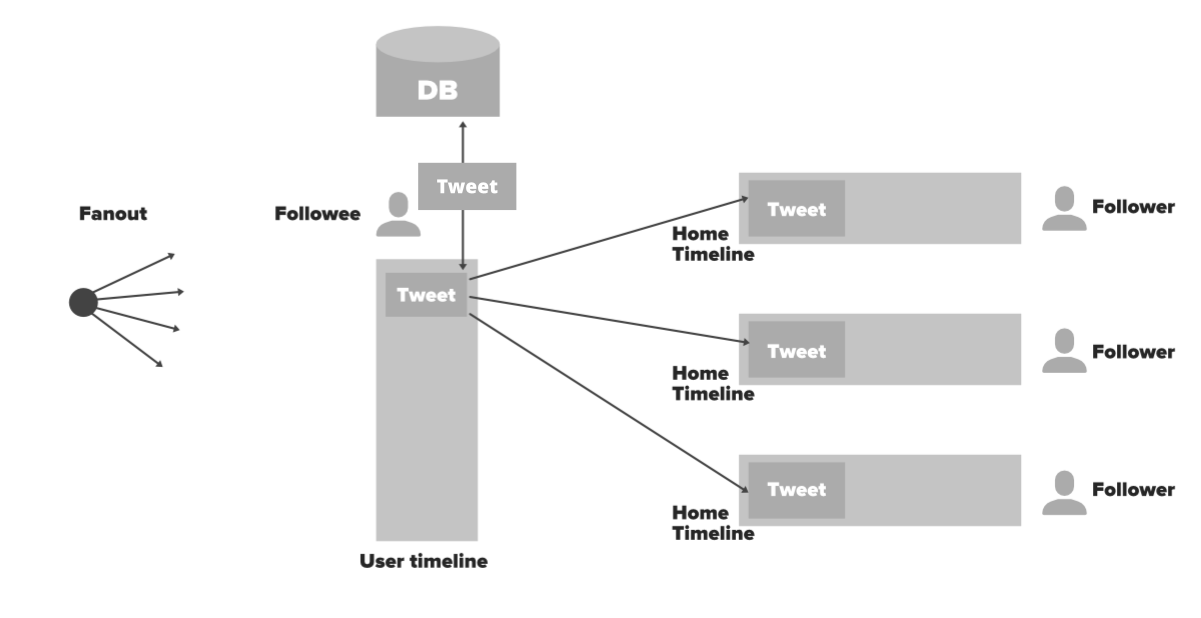
如果名人拥有数百万粉丝会怎样?上述方法在这种情况下有效吗?
弱点(Edge Case):面试官可能会问上面的问题。如果有一位拥有数百万粉丝的名人,那么 Twitter 可能需要 3-44 分钟才能将一条推文从 Eminem(名人)传到他的百万粉丝。您将不得不更新不可扩展的数百万个关注者的主页时间线。这是解决方案……
解决方案[混合方法(内存+同步调用)]:
- 预先计算用户 A(Eminem 的追随者)与除 Eminem 的推文之外的所有人的主页时间线
- 对于每个用户,在缓存中维护名人列表以及该用户关注的人。当请求到达时(来自名人的推文),您可以从列表中获取名人,从名人的用户时间线获取推文,然后在运行时将名人的推文与用户 A 的其他推文混合。
- 因此,当用户 A 访问他的主页时间线时,他的推文提要在加载时与 Eminem 的推文合并。所以名人推文将在运行时插入。
其他优化:对于非活跃用户,不计算时间线。很长一段时间(比如超过20天)没有登录系统的人。
3. 搜索
Twitter 使用Earlybird处理其推文和#tags 的搜索,这是一个基于 Lucene 的实时反向索引。 Early Bird 进行反向全文索引操作。这意味着无论何时发布推文,它都会被视为文档。推文将被拆分为标签、单词和#tags,然后将这些单词编入索引。这种索引是在大表或分布式表上完成的。在这个表中,每个词都有对包含该特定词的所有推文的引用。由于索引是一个精确的字符串匹配,无序,它可以非常快。假设如果用户搜索“选举”,那么您将遍历表格,您会找到“选举”这个词,然后您将找出系统中所有推文的所有引用,然后它给出所有结果包含“选举”这个词。
Twitter 每秒处理数千条推文,因此您不能只用一个大系统或表来处理所有数据,因此应该通过分布式方法进行处理。 Twitter 使用分散和收集策略,它设置了允许索引的多个服务器或数据中心。当 Twitter 收到查询(假设是 #geeksforgeeks)时,它会将查询发送到所有服务器或数据中心,并查询每个Early Bird 分片。所有与查询匹配的早起鸟返回结果。结果被返回、排序、合并和重新排序。排名是根据转发次数、回复次数和推文的受欢迎程度进行的。
到目前为止,我们已经讨论了 Twitter 的所有核心功能和组件。您可以讨论其他一些深入的组件。例如,您可以谈论趋势/趋势主题(使用 Apache Storm 和 Heron 框架),您可以谈论通知以及如何合并广告。
GeeksforGeeks 系统设计课程
想在领先的科技公司获得软件开发人员/工程师的工作吗?或 想要从 SDE I 平稳过渡到 SDE II 或高级开发人员配置文件?如果是,那么您需要深入了解系统设计世界!对系统设计概念的正确掌握非常重要,尤其是对于工作专业人士而言,要在技术面试中获得比其他人急需的优势。

这就是为什么 GeeksforGeeks 为您提供以深度面试为中心的系统设计直播课程,帮助您准备与 Google、亚马逊、Adobe、优步和其他基于产品的公司的系统设计相关的问题。