本文重点介绍如何在Java解析 XML 文件。
XML : XML 代表可扩展标记语言。它旨在存储和传输数据。它被设计为人类和机器可读。这就是为什么 XML 的设计目标强调 Internet 上的简单性、通用性和可用性。
为什么是 StAX 而不是 SAX ?
- SAX :SAX 是一个推送模型 API,这意味着它是调用您的处理程序的 API,而不是您的处理程序调用 API。因此,SAX 解析器将事件“推送”到您的处理程序中。使用这种 API 推送模型,您无法控制解析器迭代文件的方式和时间。一旦您启动解析器,它就会一直迭代直到结束,为输入 XML 文档中的每个 XML 事件调用您的处理程序。
SAX Parser --> Handler - StAX :StAX 拉模型意味着它是调用解析器 API 的“处理程序”类,而不是相反。因此,您的处理程序类控制解析器何时移至输入中的下一个事件。换句话说,您的处理程序从解析器中“拉出”XML 事件。此外,您可以随时停止解析。当输入或数据库以离线或在线 xml 文件的形式给出时,通常使用 StAX 解析器代替文件阅读器。 的拉模型总结如下:
Handler --> StAX ParserStAX 解析器可以读写 XML 文档,而 SAX 只能读取。 SAX 提供模式验证,即标签是否正确嵌套或 XML 是否正确编写,但 StAX 不提供这种模式验证方法。
执行
StAX解析器如何工作的想法: 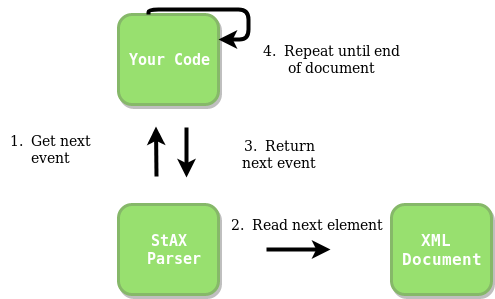
输入文件:这是作者制作的示例输入文件,用于展示如何使用 StAX 解析器。将其另存为 data.xml 并运行代码。 XML 数据库文件通常很大并且包含许多相互嵌套的标签。
Kunal Sharma
Student
kunal@example.com
(202) 456-1414
// Java Code to implement StAX parser
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.util.Iterator;
import javax.xml.namespace.QName;
import javax.xml.stream.XMLEventReader;
import javax.xml.stream.XMLInputFactory;
import javax.xml.stream.XMLStreamException;
import javax.xml.stream.events.*;
public class Main
{
private static boolean bcompany,btitle,bname,bemail,bphone;
public static void main(String[] args) throws FileNotFoundException,
XMLStreamException
{
// Create a File object with appropriate xml file name
File file = new File("data.xml");
// Function for accessing the data
parser(file);
}
public static void parser(File file) throws FileNotFoundException,
XMLStreamException
{
// Variables to make sure whether a element
// in the xml is being accessed or not
// if false that means elements is
// not been used currently , if true the element or the
// tag is being used currently
bcompany = btitle = bname = bemail = bphone = false;
// Instance of the class which helps on reading tags
XMLInputFactory factory = XMLInputFactory.newInstance();
// Initializing the handler to access the tags in the XML file
XMLEventReader eventReader =
factory.createXMLEventReader(new FileReader(file));
// Checking the availabilty of the next tag
while (eventReader.hasNext())
{
// Event is actually the tag . It is of 3 types
// = StartEvent
// = EndEvent
// data between the StartEvent and the EndEvent
// which is Characters Event
XMLEvent event = eventReader.nextEvent();
// This will trigger when the tag is of type <...>
if (event.isStartElement())
{
StartElement element = (StartElement)event;
// Iterator for accessing the metadeta related
// the tag started.
// Here, it would name of the company
Iterator iterator = element.getAttributes();
while (iterator.hasNext())
{
Attribute attribute = iterator.next();
QName name = attribute.getName();
String value = attribute.getValue();
System.out.println(name+" = " + value);
}
// Checking which tag needs to be opened for reading.
// If the tag matches then the boolean of that tag
// is set to be true.
if (element.getName().toString().equalsIgnoreCase("comapany"))
{
bcompany = true;
}
if (element.getName().toString().equalsIgnoreCase("title"))
{
btitle = true;
}
if (element.getName().toString().equalsIgnoreCase("name"))
{
bname = true;
}
if (element.getName().toString().equalsIgnoreCase("email"))
{
bemail = true;
}
if (element.getName().toString().equalsIgnoreCase("phone"))
{
bphone = true;
}
}
// This will be triggered when the tag is of type
if (event.isEndElement())
{
EndElement element = (EndElement) event;
// Checking which tag needs to be closed after reading.
// If the tag matches then the boolean of that tag is
// set to be false.
if (element.getName().toString().equalsIgnoreCase("comapany"))
{
bcompany = false;
}
if (element.getName().toString().equalsIgnoreCase("title"))
{
btitle = false;
}
if (element.getName().toString().equalsIgnoreCase("name"))
{
bname = false;
}
if (element.getName().toString().equalsIgnoreCase("email"))
{
bemail = false;
}
if (element.getName().toString().equalsIgnoreCase("phone"))
{
bphone = false;
}
}
// Triggered when there is data after the tag which is
// currently opened.
if (event.isCharacters())
{
// Depending upon the tag opened the data is retrieved .
Characters element = (Characters) event;
if (bcompany)
{
System.out.println(element.getData());
}
if (btitle)
{
System.out.println(element.getData());
}
if (bname)
{
System.out.println(element.getData());
}
if (bemail)
{
System.out.println(element.getData());
}
if (bphone)
{
System.out.println(element.getData());
}
}
}
}
}
输出 :
name = geeksforgeeks.org
Kunal Sharma
Student
kunal@example.com
(202) 456-1414
StAX 如何在上述代码中工作?
在上面的代码中创建了 eventReader 之后借助工厂模式创建了一个 XML 文件阅读器,它基本上是从读取 <…> 标签开始的。 <…> 标签一出现,一个布尔变量就被设置为 true,表明标签已经被打开。这种标签匹配是通过识别它是开始标签还是结束标签来完成的。由于 <…> 标签表示开始,因此它被 StartElement 匹配。接下来是数据读取部分。在下一步中,它通过 isCharacters 匹配元素来读取字符/data,这仅在我们需要的起始标签被打开或其布尔变量设置为 true 时完成。在此之后是由 标记指示的元素的关闭。一旦遇到 ,它就会检查哪些元素被打开或设置为 true ,并将该元素的布尔值设置为 false 或关闭它。
基本上每个事件首先打开标签,读取其数据,然后关闭它。
- 参考 :
- https://docs.oracle.com/javase/tutorial/jaxp/sax/parsing.html
- https://docs.oracle.com/cd/E17802_01/webservices/webservices/docs/1.6/tutorial/doc/SJSXP2.html