我们将创建一个数据库并在我们的数据库中创建一个表。并将涵盖使用 CLOUDERA – VMWARE Work Station 的 HIVE 中的数据库操作。让我们一一讨论。
介绍:
- Hive是一个 ETL 工具,它在用户和集成了 Hadoop 的 Hadoop 分布式文件系统之间提供类似 SQL 的接口。
- 它建立在 Hadoop 之上。
- 它有助于读取、写入和处理存储在分布式存储中并通过结构查询语言 (SQL) 语法查询的广泛数据集。
要求:
- 需要安装Cloudera – vmware 工作站。
- Windows 下载链接 – https://www.cloudera.com/downloads/cdh.html
云时代:
Cloudera 使您能够部署和管理 Apache Hadoop,操作和分析您的数据,并确保数据安全和受到保护。
安装后打开 Cloudera 的步骤
第 1 步:在您的桌面上可以使用 VMware 工作站。打开那个。

第 2 步:现在您将获得一个界面。单击打开虚拟设备。

第 3 步:选择路径 – 在这一步中,您必须选择下载文件的路径和文件。
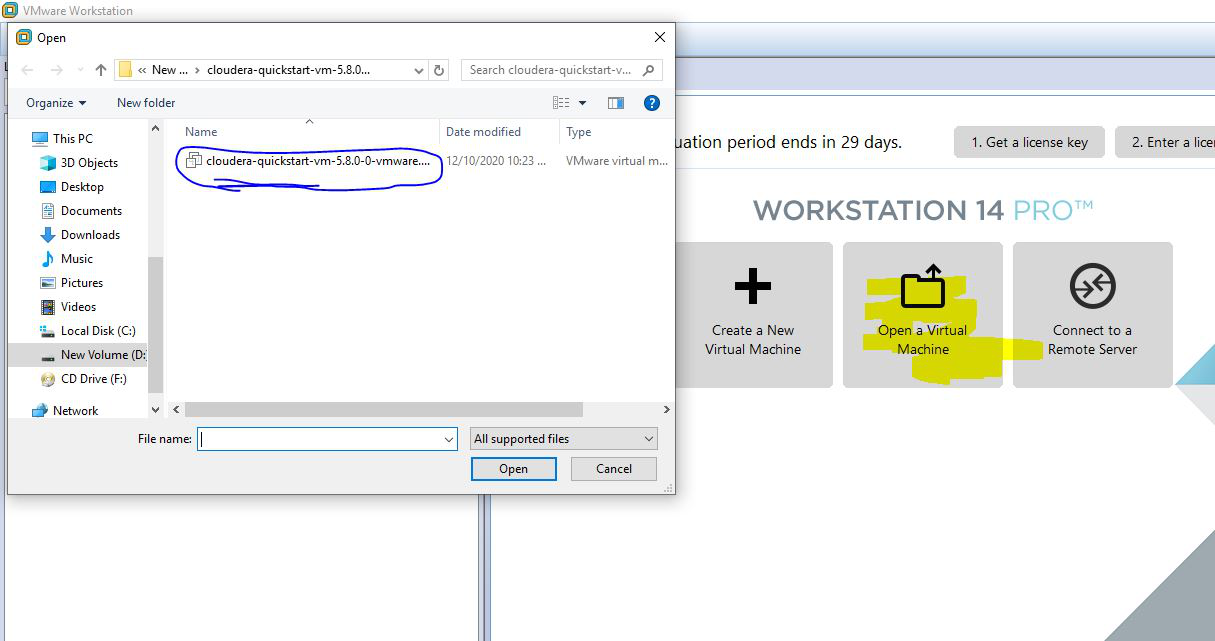
第 4 步:现在您的虚拟环境正在创建。

第 5 步:您可以在此路径中查看您的虚拟机详细信息。

第 6 步:现在打开终端以开始使用 hive 命令。

第 7 步:现在在终端中输入 hive。它将给出如下输出。
[cloudera@quickstart ~]$ hive
2020-12-09 20:59:24,314 WARN [main] mapreduce.TableMapReduceUtil:
The hbase-prefix-tree module jar containing PrefixTreeCodec is not present. Continuing without it.
Logging initialized using configuration in file:/etc/hive/conf.dist/hive-log4j.properties
WARNING: Hive CLI is deprecated and migration to Beeline is recommended.
hive> 第 8 步:现在,您已准备就绪,可以开始输入 hive 命令了。
HIVE中的数据库操作
1.创建数据库
句法:
create database database_name;例子:
create database geeksportal;输出:

2. 创建表
句法:
create database.tablename(columns);例子:
create table geeksportal.geekdata(id int,name string);这里 id 和字符串是两列。
输出 :

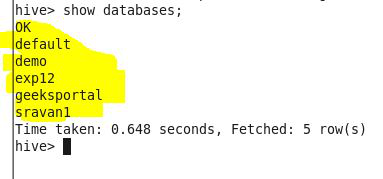
3. 显示数据库
句法:
show databases;输出:显示创建的数据库。
4. 描述数据库
句法:
describe database database_name;例子:
describe database geeksportal;输出:显示特定数据库的 HDFS 路径。
