大数据只不过是庞大、复杂且难以使用可用数据管理工具或传统数据处理应用程序存储和处理的数据集的集合。 Hadoop 是一个框架(开源),用于以并行和分布式方式编写、运行、存储和处理大型数据集。它是一种用于克服大数据所面临挑战的解决方案。
Hadoop 有两个组件:
- HDFS(Hadoop分布式文件系统)
- YARN(又一个资源谈判者)
在本文中,我们将重点介绍 Hadoop 的一个组件,即 HDFS,以及对 HDFS 中文件读取和文件写入的剖析。 HDFS 是一种文件系统,旨在存储具有流数据访问的超大文件(大小为数百兆字节、千兆字节或 TB 的文件),运行在商品硬件集群(可从各种供应商处获得的通用硬件)上。简单来说,Hadoop的存储单元叫做HDFS。
HDFS 的一些特性是:
- 容错
- 可扩展性
- 分布式存储
- 可靠性
- 高可用性
- 性价比高
- 高吞吐量
Hadoop的构建块:
- 名称节点
- 数据节点
- 辅助名称节点 (SNN)
- 工作追踪器
- 任务追踪器
HDFS 文件读取剖析
让我们借助图表了解数据如何在与 HDFS 交互的客户端、名称节点和数据节点之间流动。考虑下图:
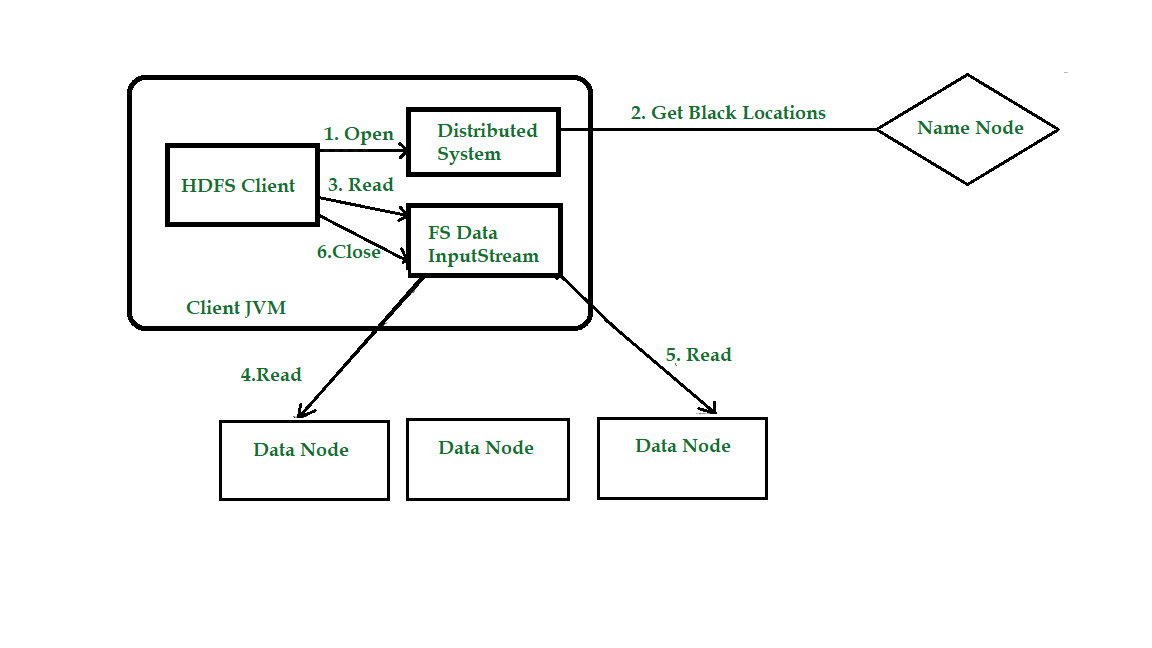
步骤 1:客户端通过调用文件系统对象(对于 HDFS 是分布式文件系统的一个实例)上的 open() 打开它希望读取的文件。
步骤 2:分布式文件系统 (DFS) 使用远程过程调用 (RPC) 调用名称节点,以确定文件中前几个块的位置。对于每个块,名称节点返回具有该块副本的数据节点的地址。 DFS 向客户端返回一个 FSDataInputStream 以供其读取数据。 FSDataInputStream 反过来包装一个 DFSInputStream,它管理数据节点和名称节点 I/O。
第 3 步:客户端然后在流上调用 read()。 DFSInputStream 已存储文件中主要几个块的信息节点地址,然后连接到文件中主要块的主要(最近)数据节点。
第 4 步:数据从数据节点流回客户端,客户端在流上重复调用 read()。
第五步:当到达块的末尾时,DFSInputStream 将关闭与数据节点的连接,然后为下一个块寻找最佳数据节点。这对客户端来说是透明的,从它的角度来看,这只是读取一个无休止的数据流。块被读取为,DFSInputStream 打开到数据节点的新连接,因为客户端读取流。它还将根据需要调用名称节点来检索下一批块的数据节点位置。
步骤6:当客户端已完成读取文件,一个函数被调用,靠近()就FSDataInputStream。
HDFS 文件写入剖析
接下来,我们将查看文件是如何写入 HDFS 的。考虑图 1.2 以更好地理解该概念。
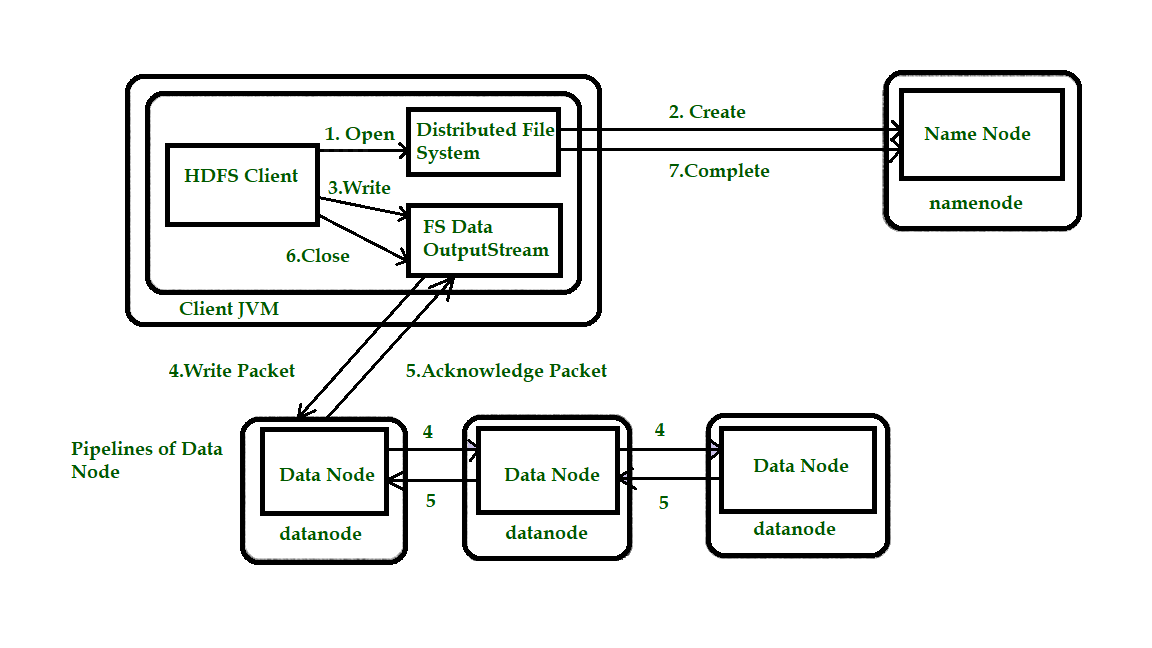
步骤 1:客户端通过在 DistributedFileSystem(DFS) 上调用 create() 来创建文件。
第 2 步: DFS 对名称节点进行 RPC 调用,以在文件系统的命名空间中创建一个新文件,没有与之关联的块。名称节点执行各种检查以确保文件不存在并且客户端具有创建文件的正确权限。如果这些检查通过,名称节点准备新文件的记录;否则,无法创建文件,因此客户端会抛出错误,即 IOException。 DFS 返回一个 FSDataOutputStream 供客户端开始写入数据。
第 3 步:由于客户端写入数据,DFSOutputStream 将其拆分为数据包,然后将其写入一个称为信息队列的室内队列。数据队列由 DataStreamer 使用,DataStreamer 负责通过选择合适的数据节点清单来存储副本,从而要求名称节点分配新块。数据节点列表形成了一个管道,这里我们假设复制级别为 3,因此管道中有 3 个节点。 DataStreamer 将数据包流式传输到管道内的主要数据节点,该节点存储每个数据包并将其转发到管道内的第二个数据节点。
第 4 步:同样,第二个数据节点存储数据包并将其转发到管道中的第三个(也是最后一个)数据节点。
第 5 步: DFSOutputStream 维持一个内部数据包队列,这些数据包等待数据节点确认,称为“确认队列”。
第 6 步:此操作将所有剩余的数据包发送到数据节点管道并等待确认,然后再连接到名称节点以指示文件是否完整。
HDFS 遵循一次写入多次读取模型。因此,我们无法编辑已经存储在 HDFS 中的文件,但我们可以通过再次重新打开文件来包含它。这种设计允许 HDFS 扩展到大量并发客户端,因为数据流量分布在集群中的所有数据节点上。因此,它提高了系统的可用性、可扩展性和吞吐量。