使用排列重要性的机器学习可解释性
机器学习模型通常充当黑匣子,这意味着它们可以做出很好的预测,但很难完全理解驱动这些预测的决策。从模型中获得洞察力并不是一件容易的事,尽管它们可以帮助调试、特征工程、指导未来的数据收集、为人类决策提供信息,并最终建立对模型预测的信任。
关于模型的最简单的查询之一可能是确定哪些特征对预测的影响最大,称为特征重要性。评估此指标的一种方法是排列重要性。
一旦在训练集上训练了模型,就会计算排列重要性。它询问:如果单个属性的数据点被随机打乱(在验证集中),保留所有剩余数据,使用这些新数据对准确率有什么影响?
理想情况下,一列的随机重新排序应该会导致准确性降低,因为新数据与现实世界的统计数据几乎没有相关性或没有相关性。当模型非常依赖的一个重要特征被改组时,模型准确性受到的影响最大。有了这个见解,过程如下:
- 获取经过训练的模型。
- 混洗单个属性的值并使用此数据来获得新的预测。接下来,使用这些新值和预测评估损失函数的变化,以确定改组的效果。性能的下降量化了被洗牌的特征的重要性。
- 反转上一步中完成的混洗以取回原始数据。使用下一个属性重做步骤 2,直到确定每个特征的重要性。
Python 的 ELI5 库提供了一种计算排列重要性的便捷方法。它适用于Python 2.7 和Python 3.4+。目前它需要 scikit-learn 0.18+。您可以使用 pip 安装 ELI5:
pip install eli5或使用:
conda install -c conda-forge eli5我们将使用 scikitlearn 的波士顿房价数据集训练随机森林回归器,并使用该训练模型来计算排列重要性。
加载数据集
Python3
from sklearn.datasets import load_boston
boston = load_boston()
print(boston.DESCR[20:1420])Python3
from sklearn.model_selection import train_test_split
# separate data into target & independent variables
x = boston.data
y = boston.target
# split data into train and test set
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)
print('Size of: ')
print('Training Set x: ', x_train.shape)
print('Training Set y: ', y_train.shape)
print('Test Set x: ', x_test.shape)
print('Test Set y: ', y_test.shape)Python3
from sklearn.ensemble import RandomForestRegressor
# train model on training set
rf = RandomForestRegressor()
# fit model on training set
rf.fit(x_train, y_train)
# calculate score on test set
print('R2 score for test set: ')
print(rf.score(x_test, y_test))Python3
import eli5
from eli5.sklearn import PermutationImportance
# create permutation importance object using model
# and fit on test set
perm = PermutationImportance(rf, random_state=1).fit(x_test, y_test)
# display weights using PermutationImportance object
eli5.show_weights(perm, feature_names = boston.feature_names)输出:

分成训练集和测试集
蟒蛇3
from sklearn.model_selection import train_test_split
# separate data into target & independent variables
x = boston.data
y = boston.target
# split data into train and test set
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8)
print('Size of: ')
print('Training Set x: ', x_train.shape)
print('Training Set y: ', y_train.shape)
print('Test Set x: ', x_test.shape)
print('Test Set y: ', y_test.shape)
输出:
Size of:
Training Set x: (404, 13)
Training Set y: (404,)
Test Set x: (102, 13)
Test Set y: (102,)
火车模型
蟒蛇3
from sklearn.ensemble import RandomForestRegressor
# train model on training set
rf = RandomForestRegressor()
# fit model on training set
rf.fit(x_train, y_train)
# calculate score on test set
print('R2 score for test set: ')
print(rf.score(x_test, y_test))
输出:
R2 score for test set: 0.857883705095584
评估排列重要性
蟒蛇3
import eli5
from eli5.sklearn import PermutationImportance
# create permutation importance object using model
# and fit on test set
perm = PermutationImportance(rf, random_state=1).fit(x_test, y_test)
# display weights using PermutationImportance object
eli5.show_weights(perm, feature_names = boston.feature_names)
输出:
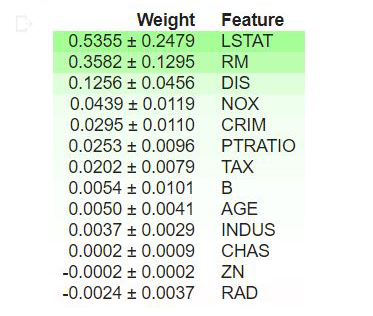
解释
- 表格顶部的值是我们模型中最重要的特征,而底部的值最不重要。
- 每行中的第一个数字表示使用与模型相同的性能指标(在本例中为 R2 分数)随机改组后模型性能下降的程度。
- ± 之后的数字衡量性能如何从一次改组到下一次改组,即多次改组的随机程度。
- 置换重要性的负值表示对混洗(或噪声)数据的预测比真实数据更准确。这意味着该特征对预测的贡献不大(重要性接近于 0),但随机机会导致对混洗数据的预测更加准确。这对于小数据集更常见。
在我们的示例中,前 3 个特征是 LSTAT、RM 和 DIS,而最不重要的 3 个特征是 RAD、CHAS 和 ZN。
概括
本文简要介绍了在Python使用 Permutation Importance 的机器学习可解释性。直观了解特征对模型性能的影响有助于调试并深入了解数据集,使其成为数据科学家的有用工具。
参考
- ELI5 文档
- Kaggle 的机器学习可解释性课程
- sklearn 的 RandomForestRegressor
- 波士顿房价数据集