自动化用于信用卡欺诈检测的机器学习管道
在进入代码之前,需要在 Jupyter notebook 或 ipython notebook 上工作。如果您的机器上没有安装,您可以使用 Google Collab。这是使用Python脚本解决机器学习问题的最佳方式之一,也是我个人最喜欢的方式之一
数据集链接:
您可以从此链接下载数据集
如果链接无效,请转到此链接并登录 Kaggle 下载数据集。
上一篇文章:使用Python进行信用卡欺诈检测
现在,我认为您已经阅读了上一篇文章而没有作弊,所以让我们继续进行。在本文中,我将使用一个名为 Pycaret 的库,它为我完成所有繁重的工作,让我用几行代码并排比较最好的模型,如果你还记得第一篇文章的话,这让我们大吃一惊很多代码和所有永恒的比较。除了保持 75% 的出勤率、超参数调优之外,我们还能够完成这个星系中最繁琐的工作,这需要几天时间和几行代码在几分钟内完成大量代码。如果您说这篇文章将是您将在一段时间内阅读的简短且最有效的文章,那将没有错。所以坐下来放松一下,让乐趣开始吧。
首先安装本文中需要的最重要的东西,Pycaret 库。这个图书馆将为您节省大量金钱,因为您知道时间就是金钱,对吧。
要在您的 Ipython 笔记本中安装该库,请使用 –
pip install pycaret
# importing all necessary libraries
# linear algebra
import numpy as np
# data processing, CSV file I / O (e.g. pd.read_csv)
import pandas as pd
代码:加载数据集
# Load the dataset from the csv file using pandas
# best way is to mount the drive on colab and
# copy the path for the csv file
path ="credit.csv"
data = pd.read_csv(path)
data.head()
代码:了解数据集
# checking for the imbalance
len(df[df['Class']== 0])
len(df[df['Class']== 1])
代码:设置 pycaret 分类
# Importing module and initializing setup
from pycaret.classification import * clf1 = setup(data = df, target = 'Class')
在此之后,将需要确认才能继续。按Enter继续使用代码。
检查库是否正确识别所有参数类型。
告诉分类器训练和验证拆分的百分比。我采用了 80% 的训练数据,这在机器学习中很常见。
来到下一个单元格,这是该库最重要的功能。它允许训练数据适合并与库中的所有算法进行比较以选择最佳算法。它显示哪个模型最好以及在哪个评估矩阵中。当数据不平衡时,准确性并不总是能告诉你真实的故事。我检查了精度,但 AUC、F1 和 Kappa 分数也对分析模型有很大帮助。但这将涉及到一篇文章。
代码:比较模型
# command used for comparing all the models available in the library
compare_models()
输出:

黄色部分是对应模型的最高分。
采用在比较中表现良好的单个算法并为其创建模型。该算法的名称可以在创建模型下的 pycaret 库的文档中找到
代码:创建最佳模型
# creating logistic regression model
ET = create_model('et')
代码:显示模型参数
# displaying the model parameters
ET
输出: 
代码:超参数调优
# hyperparameter tuning for a particular model
model = tune_model('ET')
输出: 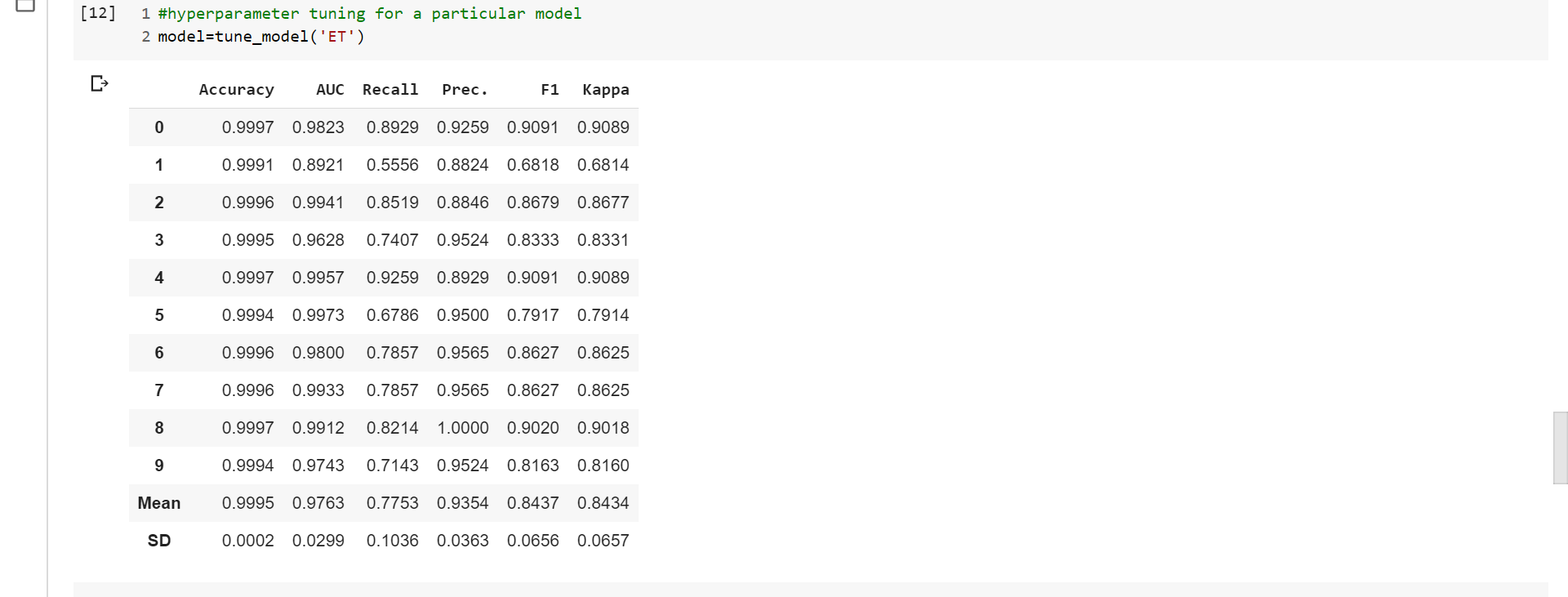
代码:保存模型
经过数小时的模型训练和超调优后,可能发生在您身上的最糟糕的事情是模型随着会话超时的发生而消失。为了把你从这个噩梦中拯救出来,让我给你一个你永远不会忘记的技巧。
# saving the model
save_model(ET, 'ET_saved')
代码:加载模型
# Loading the saved model
ET_saved = load_model('ET_saved')
输出: 
代码:完成模型
当您合并训练和验证数据并在所有可用数据上训练模型时,部署前的一个步骤。
# finalize a model
final_rf = finalize_model(rf)
部署模型部署在 AWS 上。对于相同所需的设置,请访问文档
# Deploy a model
deploy_model(final_lr, model_name = 'lr_aws', platform = 'aws', authentication = { 'bucket' : 'pycaret-test' })
在评论中写代码?请使用 ide.geeksforgeeks.org,生成链接并在此处分享链接。