比较和查找 SQL 中两个表之间的差异
结构化查询语言或 SQL 是一种标准的数据库语言,用于从 MySQL、Oracle 等关系数据库中创建、维护和检索数据。在这里我们将看到如何在 SQL 中比较和查找两个表之间的差异
在这里,我们将首先创建一个名为“geeks”的数据库,然后在该数据库中创建两个表“department_old ”和“ department_new”。之后,我们将在该表上执行我们的查询。
创建数据库:.
使用以下 SQL 语句创建名为geeks的数据库:
CREATE geeks;使用数据库:
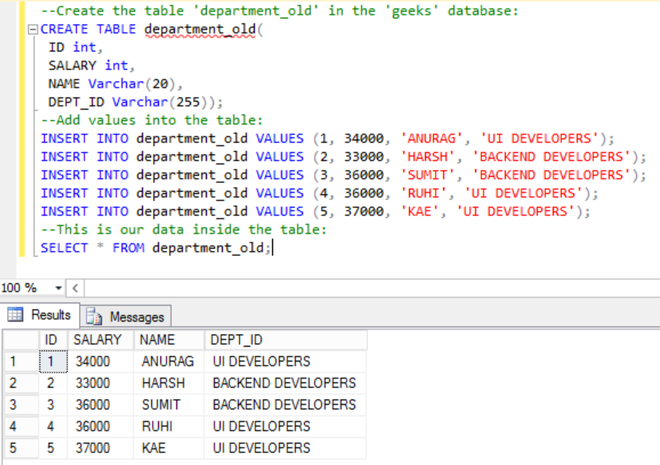
USE geeks;Department_old表的表定义:
CREATE TABLE department_old(
ID int,
SALARY int,
NAME Varchar(20),
DEPT_ID Varchar(255));将值添加到表中:
使用以下查询向表中添加数据:
INSERT INTO department_old VALUES (1, 34000, 'ANURAG', 'UI DEVELOPERS');
INSERT INTO department_old VALUES (2, 33000, 'HARSH', 'BACKEND DEVELOPERS');
INSERT INTO department_old VALUES (3, 36000, 'SUMIT', 'BACKEND DEVELOPERS');
INSERT INTO department_old VALUES (4, 36000, 'RUHI', 'UI DEVELOPERS');
INSERT INTO department_old VALUES (5, 37000, 'KAE', 'UI DEVELOPERS');要验证表的内容,请使用以下语句:
SELECT * FROM department_old;| ID | SALARY | NAME | DEPT_ID |
|---|---|---|---|
| 1 | 34000 | ANURAG | UI DEVELOPERS |
| 2 | 33000 | HARSH | BACKEND DEVELOPERS |
| 3 | 36000 | SUMIT | BACKEND DEVELOPERS |
| 4 | 36000 | RUHI | UI DEVELOPERS |
| 5 | 37000 | KAE | UI DEVELOPERS |
SQL Server Management Studio 的结果:
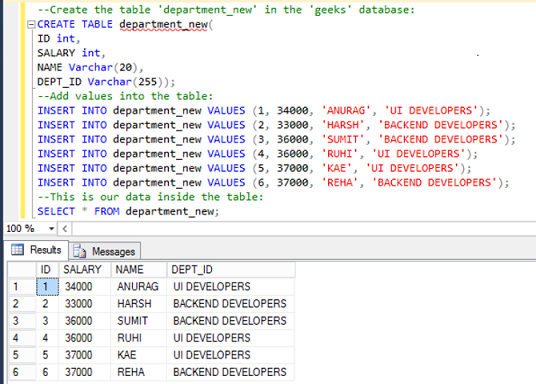
Department_new表的表定义:
CREATE TABLE department_new(
ID int,
SALARY int,
NAME Varchar(20),
DEPT_ID Varchar(255));将值添加到表中:
使用以下查询向表中添加数据:
INSERT INTO department_new VALUES (1, 34000, 'ANURAG', 'UI DEVELOPERS');
INSERT INTO department_new VALUES (2, 33000, 'HARSH', 'BACKEND DEVELOPERS');
INSERT INTO department_new VALUES (3, 36000, 'SUMIT', 'BACKEND DEVELOPERS');
INSERT INTO department_new VALUES (4, 36000, 'RUHI', 'UI DEVELOPERS');
INSERT INTO department_new VALUES (5, 37000, 'KAE', 'UI DEVELOPERS');
INSERT INTO department_new VALUES (6, 37000, 'REHA', 'BACKEND DEVELOPERS');要验证表的内容,请使用以下语句:
SELECT * FROM department_new;| ID | SALARY | NAME | DEPT_ID |
|---|---|---|---|
| 1 | 34000 | ANURAG | UI DEVELOPERS |
| 2 | 33000 | HARSH | BACKEND DEVELOPERS |
| 3 | 36000 | SUMIT | BACKEND DEVELOPERS |
| 4 | 36000 | RUHI | UI DEVELOPERS |
| 5 | 37000 | KAE | UI DEVELOPERS |
| 6 | 37000 | REHA | BACKEND DEVELOPERS |
输出:
比较两个查询的结果
让我们假设,我们有两个表: table1和table2 。在这里,我们将使用 UNION ALL 根据需要比较的列组合记录。如果需要比较的列中的值相同,则 COUNT(*) 返回 2,否则 COUNT(*) 返回 1。
句法:
SELECT column1, column2.... columnN
FROM
( SELECT table1.column1, table1.column2
FROM table1
UNION ALL
SELECT table2.column1, table2.column2
FROM table2
) table1
GROUP BY column1
HAVING COUNT(*) = 1例子:
Select ID from
( select * from department_old
UNION ALL
select * from department_new)
department_old
GROUP BY ID
HAVING COUNT(*) = 1输出:
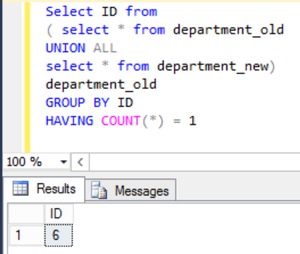
如果比较中涉及的列中的值相同,则不返回任何行。