在 MongoDB 中创建关系
在 MongoDB 中,关系表示不同类型的文档如何在逻辑上相互关联。一对一、一对多等关系可以使用两种不同的模型来表示:
- 嵌入式文档模型
- 参考模型
嵌入式文档模型:在此模型中,文档嵌入在一个文档中。例如,我们有两个文档,一个是学生(包含学生的基本信息,如 id、姓名分支),另一个是地址文档(包含学生的地址)。因此,我们不是创建两个不同的文档,而是将地址文档嵌入到学生文档中。它将帮助用户使用单个查询而不是编写一堆查询来检索数据。
参考模型:在此模型中,我们单独维护文档,但一个文档包含其他文档的引用。例如,我们有两个文档,一个是学生(包含学生的基本信息,如 id、姓名分支),另一个是地址文档(包含学生的地址)。因此,这里的学生文档包含对地址文档的id字段的引用。现在使用这个引用id 我们可以查询地址并获取学生的地址。该模型通常用于设计规范化关系。
与嵌入文档的一对一关系
使用嵌入式文档,我们可以在数据之间创建一对一的关系,这样我们就可以使用很少的读取操作轻松检索数据。
现在我们将借助示例讨论与嵌入文档的一对一关系。让我们考虑一下我们有两个文件。第一个文档包含学生的 id 名称和分支,第二个文档包含学生的永久地址详细信息。
// Student document
{
StudentName: GeeksA,
StudentId: g_f_g_1209,
Branch:CSE
}
// Address document
{
StudentName: GeeksA,
PremanentAddress: XXXXXXX,
City: Delhi,
PinCode:202333
}现在,如果经常使用地址数据,用户通过使用学生姓名创建查询来检索地址文档的数据,但这里两个文档包含相同的字段(即学生姓名),因此用户需要编写更多的查询来检索所需的信息。这个检索数据的过程很麻烦。因此,我们将地址文档嵌入到学生文档中。
{
StudentName: GeeksA,
StudentId: g_f_g_1209,
Branch:CSE
PermanentAddress:{
PremanentAddress: XXXXXXX,
City: Delhi,
PinCode:202333
}
}现在,我们只需要编写一个查询来检索所需的数据。使用嵌入式文档的好处是我们可以将所需的信息分组并将其保存在单个文档中。因此,在一次通话中更容易获得详细信息。但是当文档开始增长时,例如将学术信息、体育信息添加到上述文档中时,它会变得更长,并且需要更多时间来检索详细信息。仅在需要时,我们可能需要有学术或体育信息,因此在这些场景中,我们可能需要分解文档并可以使用子集模式。在子集模式中,我们将大量信息分成小块,以便我们可以轻松地检索数据。因为大量的数据减慢了读取操作。但是子集模式也有一个缺点,就是把你的数据拆分成很多小的集合,数据库维护部分比较困难,对数据的跟踪也会变得很麻烦。
例子:
在这里,我们正在与:
Database: gfg
Collection: student
Documents: One document that contains the details of a student
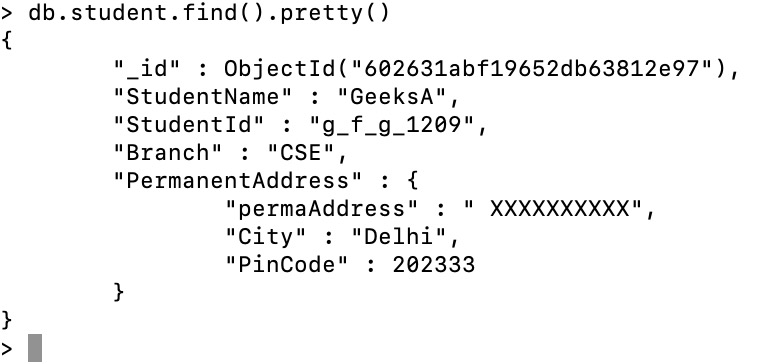
现在我们将显示学生的地址
db.student.find({StudentName:"GeeksA"},{"PermanentAddress.permaAddress":1}).pretty()
与嵌入文档的一对多关系
使用嵌入式文档,我们可以在数据之间创建一对多的关系,这样我们就可以使用很少的读取操作轻松检索数据。现在我们将借助示例讨论与嵌入文档的一对多关系。有时,一个人可能包含多个地址,例如拥有当前地址(他/她住的地方)和居住地址(他/她拥有自己的房子或永久地址的地方)。在此期间,会出现一对多关系的可能性。因此,我们可以使用嵌入式文档模型将永久地址和当前地址存储在单个文档中
// Student document
{
StudentName: GeeksA,
StudentId: g_f_g_1209,
Branch:CSE
}
// Permanent Address document
{
StudentName: GeeksA,
PermanentAddress: XXXXXXX,
City: Delhi,
PinCode:202333
}
// Current Address document
{
StudentName: GeeksA,
CurrentAddress: XXXXXXX,
City: Mumbai,
PinCode:334509
}现在,我们可以将它们嵌入到单个文档中,而不是编写三个文档。
// Student document
{
StudentName: GeeksA,
StudentId: g_f_g_1209,
Branch:CSE
Address: [
{
StudentName: GeeksA,
PermanentAddress: XXXXXXX,
City: Delhi,
PinCode:202333
},
{
StudentName: GeeksA,
CurrentAddress: XXXXXXX,
City: Mumbai,
PinCode:334509
}
]
}由于我们将所有数据(即使有超过 2 种地址类型的信息,我们可以将它们保存在一个 JSON 数组中)在一个集合中,我们可以在一次调用中查询并获得一整套数据,这导致获取完整信息并且不会发生任何损失。
例子:
在这里,我们正在与:
Database: gfg
Collection: student
Documents: One document that contains the details of a student

现在我们将显示学生的所有地址
db.student.find({StudentName:"GeeksA"},
{"Address.permaAddress":1,
"Address.currAddress":1}).pretty()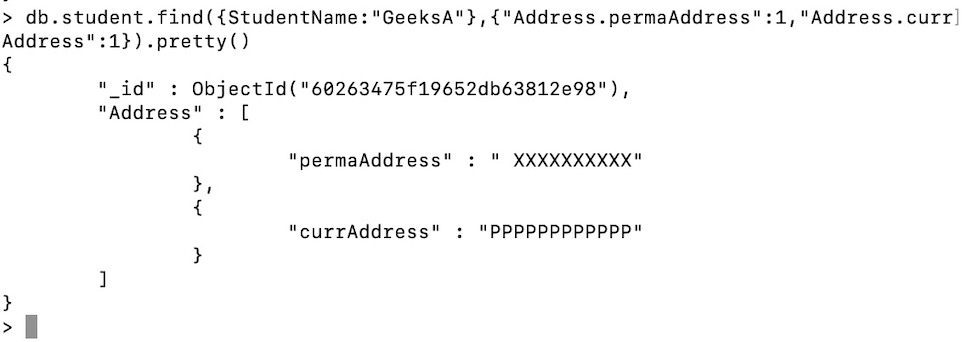
与文档引用的一对多关系
我们还可以使用文档参考模型执行一对多关系。在此模型中,我们单独维护文档,但一个文档包含其他文档的引用。
现在我们将借助示例讨论与嵌入文档的一对多关系。让我们考虑一下我们有一位老师在 2 个不同的班级任教。所以,她有三个文件:
// Teacher document
{
teacherName: Sunita,
TeacherId: g_f_g_1209,
}
// Class 1 document
{
TeacherId: g_f_g_1209,
ClassName: GeeksA,
ClassId: C_123
Studentcount: 23,
Subject: "Science",
}
// Class 2 document
{
TeacherId: g_f_g_1209,
ClassId: C_234
ClassName: GeeksB,
Studentcount: 33,
Subject: "Maths",
}现在从这些不同的文档中检索数据很麻烦。因此,在这里我们使用参考模型,这将帮助教师使用单个查询检索数据。
// Teacher document
{
teacherName: Sunita,
TeacherId: g_f_g_1209,
classIds: [
C_123,
C_234
]
}现在使用这些 classIds 现场教师可以轻松检索类 1 和类 2 的数据。
例子:
在这里,我们正在与:
Database: gfg
Collection: teacher
Documents: three document that contains the details of the classes
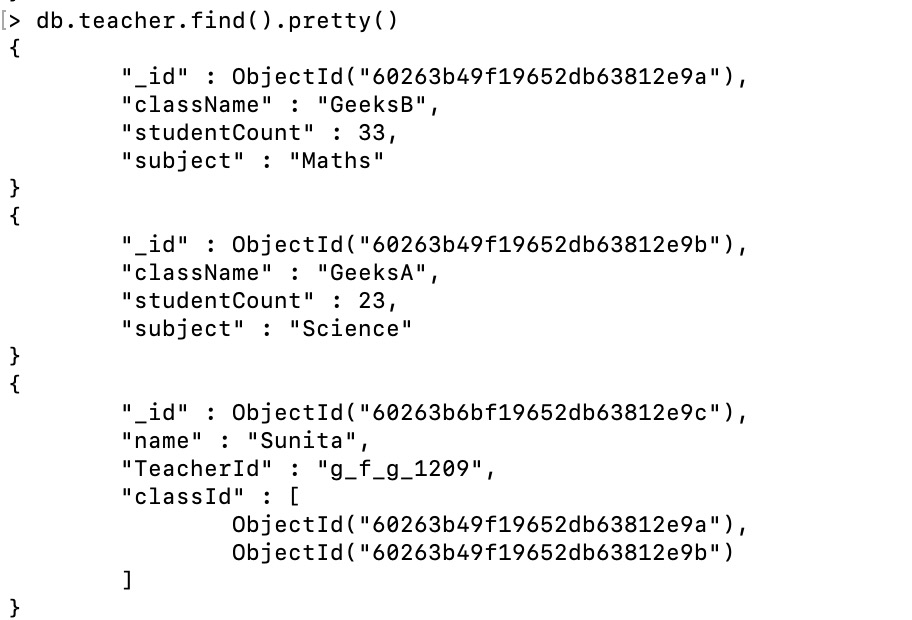
现在我们将显示 classId 字段的值
db.teacher.findOne({name:"Sunita"}, {classId:1})