- TIKA-元数据提取(1)
- TIKA-元数据提取
- TIKA-提取PDF(1)
- TIKA-提取PDF
- TIKA-提取HTML文档(1)
- TIKA-提取HTML文档
- TIKA-提取.class文件
- TIKA-提取.class文件(1)
- TIKA-提取XML文档
- TIKA-提取XML文档(1)
- TIKA-提取mp4文件(1)
- TIKA-提取mp4文件
- TIKA-提取图像文件
- TIKA-提取图像文件(1)
- TIKA-提取JAR文件
- TIKA-提取JAR文件(1)
- TIKA-提取mp3文件(1)
- TIKA-提取mp3文件
- TIKA-提取文本文档
- TIKA-提取文本文档(1)
- TIKA-提取ODF
- TIKA-提取ODF(1)
- Tika-编程示例(1)
- Tika-编程示例
- TIKA教程
- TIKA教程(1)
- TIKA-提取MS-Office文件
- TIKA-提取MS-Office文件(1)
- 讨论TIKA
📅 最后修改于: 2020-11-10 04:27:54 🧑 作者: Mango
Tika使用各种解析器库从给定的解析器中提取内容。它选择正确的解析器以提取给定的文档类型。
为了分析文档,通常使用Tika Facade类的parseToString()方法。下面显示的是解析过程中涉及的步骤,这些步骤由Tika ParsertoString()方法抽象化。
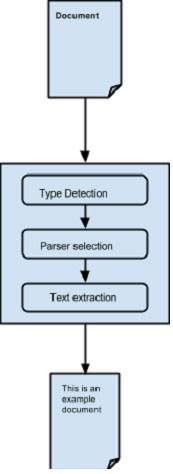
抽象解析过程-
-
最初,当我们将文档传递给Tika时,它会使用合适的类型检测机制来检测文档类型。
-
一旦知道了文档类型,它将从其解析器存储库中选择一个合适的解析器。解析器存储库包含使用外部库的类。
-
然后,将文档传递给选择解析器,该解析器将解析内容,提取文本并抛出不可读格式的异常。
使用Tika提取内容
下面给出的是使用Tika Facade类从文件中提取文本的程序-
import java.io.File;
import java.io.IOException;
import org.apache.tika.Tika;
import org.apache.tika.exception.TikaException;
import org.xml.sax.SAXException;
public class TikaExtraction {
public static void main(final String[] args) throws IOException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//Instantiating Tika facade class
Tika tika = new Tika();
String filecontent = tika.parseToString(file);
System.out.println("Extracted Content: " + filecontent);
}
}
将以上代码另存为TikaExtraction.java并在命令提示符下运行-
javac TikaExtraction.java
java TikaExtraction
下面给出的是sample.txt的内容。
Hi students welcome to tutorialspoint
它为您提供以下输出-
Extracted Content: Hi students welcome to tutorialspoint
使用解析器界面提取内容
Tika的解析器包提供了几个接口和类,我们可以使用它们来解析文本文档。下面给出的是org.apache.tika.parser软件包的框图。
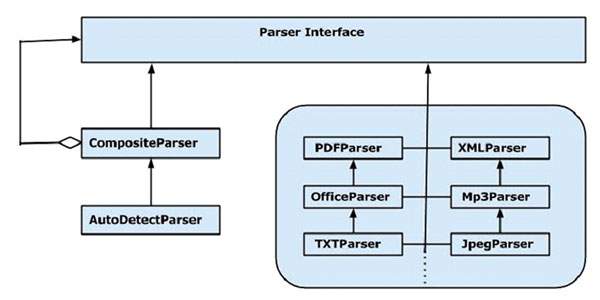
有几种可用的解析器类,例如pdf解析器,Mp3Passer,OfficeParser等,用于分别解析各个文档。所有这些类都实现了解析器接口。
CompositeParser
给定的图显示了Tika的通用解析器类: CompositeParser和AutoDetectParser 。由于CompositeParser类遵循复合设计模式,因此可以将一组解析器实例用作单个解析器。 CompositeParser类还允许访问实现解析器接口的所有类。
AutoDetectParser
这是CompositeParser的子类,它提供自动类型检测。使用此功能,AutoDetectParser会使用复合方法自动将传入文档发送到适当的解析器类。
parse()方法
与parseToString()一起,您还可以使用解析器接口的parse()方法。该方法的原型如下所示。
parse(InputStream stream, ContentHandler handler, Metadata metadata, ParseContext context)
下表列出了它接受作为参数的四个对象。
| Sr.No. | Object & Description |
|---|---|
| 1 |
InputStream stream Any Inputstream object that contains the content of the file |
| 2 |
ContentHandler handler Tika passes the document as XHTML content to this handler, thereafter the document is processed using SAX API. It provides efficient postprocessing of the contents in a document. |
| 3 |
Metadata metadata The metadata object is used both as a source and a target of document metadata. |
| 4 |
ParseContext context This object is used in cases where the client application wants to customize the parsing process. |
例
下面给出的示例说明如何使用parse()方法。
步骤1-
要使用解析器接口的parse()方法,请实例化提供该接口实现的任何类。
有单独的解析器类,例如PDFParser,OfficeParser,XMLParser等。您可以使用任何这些单独的文档解析器。或者,您可以使用CompositeParser或AutoDetectParser,它们在内部使用所有解析器类,并使用合适的解析器提取文档的内容。
Parser parser = new AutoDetectParser();
(or)
Parser parser = new CompositeParser();
(or)
object of any individual parsers given in Tika Library
步骤2-
创建一个处理程序类对象。下面给出的是三个内容处理程序-
| Sr.No. | Class & Description |
|---|---|
| 1 |
BodyContentHandler This class picks the body part of the XHTML output and writes that content to the output writer or output stream. Then it redirects the XHTML content to another content handler instance. |
| 2 |
LinkContentHandler This class detects and picks all the H-Ref tags of the XHTML document and forwards those for the use of tools like web crawlers. |
| 3 |
TeeContentHandler This class helps in using multiple tools simultaneously. |
由于我们的目标是从文档中提取文本内容,因此实例化BodyContentHandler,如下所示-
BodyContentHandler handler = new BodyContentHandler( );
步骤3-
创建元数据对象,如下所示-
Metadata metadata = new Metadata();
步骤4-
创建任何输入流对象,然后将应提取的文件传递给它。
FileInputstream
通过将文件路径作为参数来实例化文件对象,然后将此对象传递给FileInputStream类构造函数。
注–传递到文件对象的路径不应包含空格。
这些输入流类的问题在于它们不支持随机访问读取,这是有效处理某些文件格式所必需的。为了解决此问题,Tika提供了TikaInputStream。
File file = new File(filepath)
FileInputStream inputstream = new FileInputStream(file);
(or)
InputStream stream = TikaInputStream.get(new File(filename));
步骤5-
创建一个解析上下文对象,如下所示:
ParseContext context =new ParseContext();
步骤6-
实例化解析器对象,调用parse方法,并传递所需的所有对象,如下面的原型所示-
parser.parse(inputstream, handler, metadata, context);
下面给出的是使用解析器接口进行内容提取的程序-
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import org.apache.tika.exception.TikaException;
import org.apache.tika.metadata.Metadata;
import org.apache.tika.parser.AutoDetectParser;
import org.apache.tika.parser.ParseContext;
import org.apache.tika.parser.Parser;
import org.apache.tika.sax.BodyContentHandler;
import org.xml.sax.SAXException;
public class ParserExtraction {
public static void main(final String[] args) throws IOException,SAXException, TikaException {
//Assume sample.txt is in your current directory
File file = new File("sample.txt");
//parse method parameters
Parser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
FileInputStream inputstream = new FileInputStream(file);
ParseContext context = new ParseContext();
//parsing the file
parser.parse(inputstream, handler, metadata, context);
System.out.println("File content : " + Handler.toString());
}
}
将上面的代码另存为ParserExtraction.java并从命令提示符运行-
javac ParserExtraction.java
java ParserExtraction
下面给出的是sample.txt的内容
Hi students welcome to tutorialspoint
如果执行上述程序,它将为您提供以下输出-
File content : Hi students welcome to tutorialspoint