- MySQL DISTINCT - SQL 代码示例
- sql server 中的 distinct - SQL (1)
- 查询 DISTINCT - SQL 代码示例
- sql server 中的 distinct - SQL 代码示例
- sql select distinct - SQL (1)
- SQL SELECT DISTINCT
- SQL SELECT DISTINCT(1)
- sql select distinct - SQL 代码示例
- T-SQL-DISTINCT子句(1)
- T-SQL-DISTINCT子句
- 如何在 c# 中的 linq 查询中使用 distinct(1)
- 如何在 c# 代码示例中的 linq 查询中使用 distinct
- pandas distinct - Python (1)
- mongodb distinct (1)
- 在 sql 代码示例中同时使用 distinct 和 count
- sql distinct vs unique - SQL (1)
- pandas distinct - Python 代码示例
- sql distinct vs unique - SQL 代码示例
- rails distinct (1)
- postgres count distinct - SQL (1)
- MongoDB - Distinct() 方法(1)
- MongoDB - Distinct() 方法
- javascript 数组 distinct - Javascript (1)
- linq distinct (1)
- postgres count distinct - SQL 代码示例
- unique 和 distinct 之间的区别 - SQL (1)
- mongodb distinct - 任何代码示例
- javascript 数组 distinct - Javascript 代码示例
- sql count distinct group by - SQL (1)
📅 最后修改于: 2020-11-12 00:44:59 🧑 作者: Mango
如何在SQL中使用distinct?
SQL DISTINCT子句用于从结果集中删除重复项列。
独特关键字与选择关键字结合使用。当我们避免特定列/表中存在重复值时,这将很有帮助。当我们使用distinct关键字时,将获取唯一值。
- SELECT DISTINCT仅返回不同(不同)的值。
- DISTINCT从表中消除重复的记录。
- DISTINCT可以与聚合一起使用: COUNT,AVG,MAX等。
- DISTINCT在单列上运行。
- DISTINCT不支持多列。
句法:
SELECT DISTINCT expressions
FROM tables
[WHERE conditions];
参数:
表达式:我们要检索的列或计算称为表达式。
表格:我们要检索记录的表格。 FROM子句中只有一个表。
条件:选择的记录可能符合条件,并且是可选的。
注意:
- 在DISTINCT子句中提供一个表达式时,查询将返回表达式的唯一值。
- 如果此处的DISTINCT子句中提供了多个表达式,则查询将检索列出表达式的唯一组合。
- 在SQL中, DISTINCT子句不能忽略NULL值。因此,当我们在SQL语句中使用DISTINCT子句时,结果集将包含NULL作为不同的值。
例:
考虑下面的EMPLOYEES表。
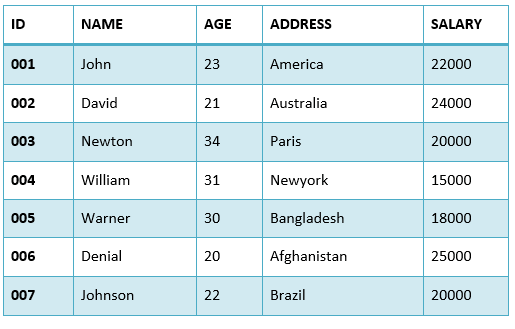
首先,让我们看下面的SELECT查询返回重复的薪水记录。
SQL> SELECT SALARY FROM EMPLOYEES
ORDER BY SALARY;
当我们执行上述SQL查询时,它将获取所有记录,包括重复记录。在上表中,牛顿和约翰逊的薪水是20000。

现在,让我们在上面的SELECT查询中使用DISTINCT关键字。
SQL> SELECT DISTINCT SALARY FROM EMPLOYEES
ORDER BY SALARY;
上面的SQL查询将删除重复的记录并显示以下结果。

示例:在列中查找唯一值
查看DISTINCT子句以在表的一列中找到唯一值。
我们有一个称为供应商的表,其中包含以下数据:
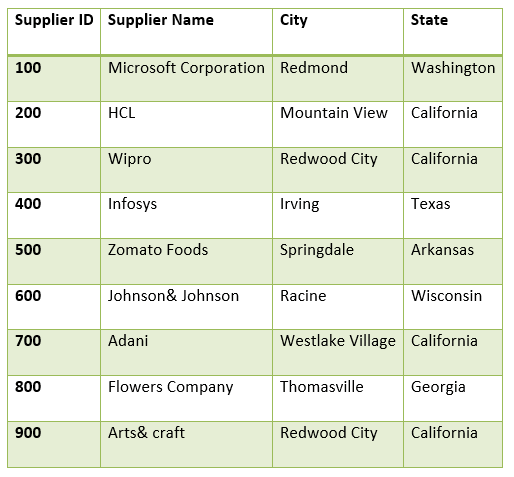
从上表中,我们将找到唯一的状态。
SELECT DISTINCT state
FROM suppliers
ORDER BY state;
这是六个记录。
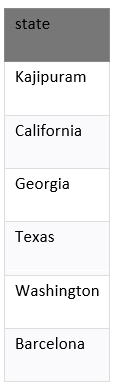
该示例从供应商表返回唯一状态,并从结果集中删除重复的记录。
示例:在多列中查找唯一值
SQL DISTINCT子句用于从SELECT语句的许多字段中删除重复的记录。
输入SQL语句:
SELECT DISTINCT city, state
FROM suppliers
ORDER BY city, state;
输出:
这些是8条记录:

该示例返回每个唯一的城市和州的组合。我们看到Redwood City和California出现在结果集中。
示例:DISTINCT子句处理NULL值
DISTINCT子句将NULL视为SQL中的唯一值。我们有一个称为产品的表,其中包含以下数据。
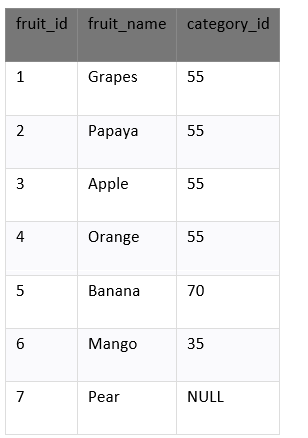
从fruit_id字段中选择唯一值,其中包含空值。输入以下SQL语法:
SELECT DISTINCT fruit_id
FROM fruits
ORDER BY category_id;
选择了四个记录。这些是我们在下面看到的结果:

在上面的示例中,查询返回category_id列中的唯一值。我们在结果集中的第一行看到NULL是由DISTINCT子句返回的异常值。