基于情感的音乐播放器Python项目
在本文中,我们将使用Python、OpenCV、Android Studios 和 FisherFace 算法构建一个基于情感的音乐播放器。正如雷·查尔斯 (Ray Charles) 所引述的那样,音乐具有治愈个人的力量。音乐在识别一个人的情绪和精神状态方面起着非常重要的作用;它是人们表达自我的绝佳方式,也是音乐爱好者和听众的重要娱乐媒介。听音乐可以帮助我们放松和平静。音乐也被认为是最有效的媒介,因为它可以通过某种信息来引起深刻的感受。随着科技的进步,艺术家、他们的音乐、音乐听众的数量都在增加,随之而来的是根据他们的心情或选择手动浏览和选择音乐的问题。这就是我们的项目发挥作用的地方,因为我们都知道要面对人体的一个器官,该器官在提取人类行为及其心理状态方面起着至关重要的作用。我们的项目检测用户的心情并根据他的心情播放歌曲或播放列表。该项目使用网络摄像头捕捉用户的图像,然后将面部表情分类为高兴、悲伤、中性或愤怒,然后根据输入图像播放歌曲。这个项目的主要优点是用户不需要手动实现和选择歌曲。
工具和技术
我们需要在我们的系统中安装 Android 工作室。我们还遇到了 OpenCV、Jupiter notebooks 和卷积神经网络 (CNN) 来检测用户情绪。我们使用了 FisherFace 算法以及主成分分析 (PCA) 和线性判别分析 (LDA)。
所需技能
Python基础知识和OpenCV、Android studio、FisherFace算法的中高级知识。
执行:
检测情绪的过程非常具有挑战性。我们已经在两个数据集上训练了我们的模型: JAFEE和 Conh-Kanade 数据库。这两个数据集在网上很容易获得,并被我们用来评估我们的模型。 FisherFace 算法捕获分类图像,对数据进行降维,然后分类计算统计值。它还为输入图像计算相同的值,并将该值与训练数据集进行比较并给出所需的输出。
LDA属于监督学习类别,其中机器必须使用先验数据进行学习。 LDA 应用了降维技术,可减少执行和分类数据的时间。 PCA以数学值的形式转换不相关和相关的变量。它使用降维来通过将大型数据集转换为更小的部分来减少它们。 PCA观察数据并计算概率生成模型。
我们使用 Cohn-Kanade 数据集进行训练,并进行了一些分类来训练和测试我们的模型。由于输入与用户有关,因此具有数据集较少和内存存储较少的优点,因此将提供良好的准确率。还可以通过快速响应时间获得更快的输出。
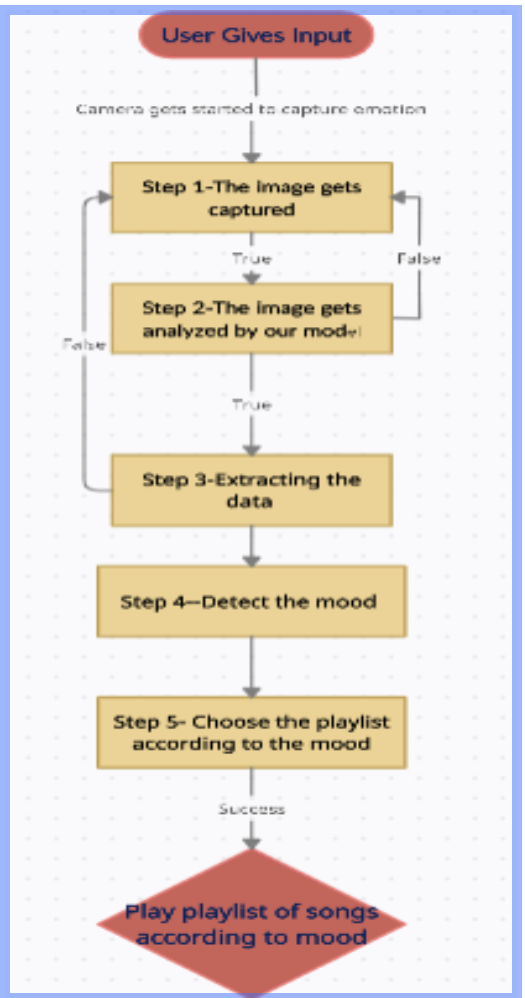
涉及处理数据并检测该情绪的步骤讨论如下:
- 步骤1:用户给出输入,以用户的网络摄像头捕捉到的图像的形式。
- 第 2 步:我们的模型对图像进行分析,并将其归类为快乐、悲伤、中性或愤怒的情绪。
- 第 3 步:使用训练数据集(JAFEE 和 Cohn-Kanade 数据集)提取和检测数据。
- 第四步:根据用户的面部情绪识别选择播放列表或歌曲。
- 第 5 步:在成功检测到情绪后,播放音乐以提升用户的情绪。
代表相同的流程图如下所示:
代码片段:
要显示源输入,请使用此代码。使用命令提示符安装必要的库,包括Tkinter :
pip -V
pip install tkinterPython3
import tkinter as tk
import cv2
from PIL import Image, ImageTk
width, height = 800, 600
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, width)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, height)
root = Music_player.Tk()
root.bind('', lambda e: root.quit())
lmain = Music_player.Label(root)
lmain.pack()
def show_frame():
_, frame = cap.read()
frame = cv2.flip(frame, 1)
cv2image = cv2.cvtColor(frame, cv2.COLOR_BGR2RGBA)
img = Image.fromarray(cv2image)
imgtk = ImageTk.PhotoImage(image=img)
lmain.imgtk = imgtk
lmain.configure(image=imgtk)
lmain.after(10, show_frame)
show_frame()
root.mainloop() Python3
import numpy as np
import glob
import random
import cv2
fishface=cv2.face.FisherFaceRecognizer_create()
data={}
def update(emotions):
run_recognizer(emotions)
print("Saving model...")
fishface.save("model.xml")
print("Model saved!!")
def make_sets(emotions):
training_data=[]
training_label=[]
for emotion in emotions:
training=training=sorted(glob.glob("dataset/%s/*" %emotion))
for item in training:
image=cv2.imread(item)
gray=cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
training_data.append(gray)
training_label.append(emotions.index(emotion))
return training_data, training_label
def run_recognizer(emotions):
training_data, training_label=make_sets(emotions)
print("Training model...")
print("The size of the dataset is "+str(len(training_data))+" images")
fishface.train(training_data, np.asarray(training_label))导入该组库并使用以下代码进行情绪检测:
蟒蛇3
import numpy as np
import glob
import random
import cv2
fishface=cv2.face.FisherFaceRecognizer_create()
data={}
def update(emotions):
run_recognizer(emotions)
print("Saving model...")
fishface.save("model.xml")
print("Model saved!!")
def make_sets(emotions):
training_data=[]
training_label=[]
for emotion in emotions:
training=training=sorted(glob.glob("dataset/%s/*" %emotion))
for item in training:
image=cv2.imread(item)
gray=cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
training_data.append(gray)
training_label.append(emotions.index(emotion))
return training_data, training_label
def run_recognizer(emotions):
training_data, training_label=make_sets(emotions)
print("Training model...")
print("The size of the dataset is "+str(len(training_data))+" images")
fishface.train(training_data, np.asarray(training_label))
结果和成果:
静态图像用于面部反应或反应知觉。拍摄的照片是从为测试而存储的照片中拍摄的。 Cohn-Kanade 数据库共有 890 张照片,而JAFEE 数据库共有 213 张照片,其中数据库有两部分不同:第一个是训练集,另一个是评估集。
对于训练和评估,我们以80/20关系的方式安排数据库。这两个集合都带有七个表达式断言。
- Cohn-Kanade 数据库:对于评估模型,我们向系统提供了一张单独拍摄的照片。然后系统首先识别排他标记的位置,然后找到那些标记。
- 对于训练和评估,模式,数据库被赋予了模型。评估后,生成混淆矩阵和分组报告或按特定顺序排列。
系统研究的个体的一些心理状态如下所示:
1) 愤怒的脸

在这张图片中,用户的心态是愤怒的。
2) 悲伤的脸

在这张图片中,用户的心理状态是悲伤或沮丧的。
3)快乐的脸:

在这张图片中,用户的心态是快乐的或快乐的。
4)中性脸:

在捕获的这张图像中,用户的心态是中性的。
表1:CK+数据库分类报告
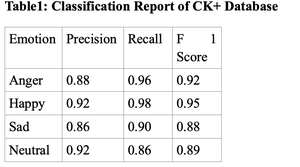
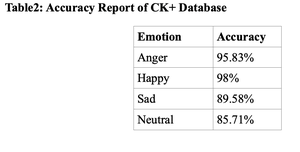
表2:CK+数据库准确率报告
现实生活应用和未来范围
在我们目前的工作状态下,我们已经处理了在线数据库中的音乐。在不久的将来,我们可以继续在线播放音乐,但还有更多选项,例如选择特定语言、最新歌曲、不太新的歌曲和 80 年代或 90 年代等老歌等等。未来的工作范围旨在举办音乐治疗课程,这肯定会帮助许多患有精神疾病、悲伤但想要快乐的人等。 基于移动应用程序的基于情感检测的音乐播放器必须是用户-友好的越来越多的选择。我们还可以创建具有此功能的应用程序和网站,包括语音识别和面部情绪检测。