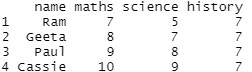识别和删除 R 中的重复数据
数据集可以具有重复值并保持其无冗余和准确,需要识别和删除重复的行。在本文中,我们将看到如何识别和删除 R 中的重复数据。首先,我们将检查数据中是否存在重复数据,如果是,则将其删除。
使用中的数据:
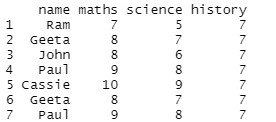
识别重复数据
为了识别,我们将使用duplicated()函数返回重复行的计数。
句法:
duplicated(dataframe)
方法:
- 创建数据框
- 将其传递给duplicated()函数
- 此函数返回以布尔值形式重复的行
- 应用 sum函数来获取数字
例子:
R
# Creating a sample data frame of students
# and their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
duplicated(student_result)
sum(duplicated(student_result))R
# Creating a sample data frame of students
# and their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
unique(student_result)R
# Creating a sample data frame of students and
# their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
distinct(student_result)R
# Creating a sample data frame of students and
# their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
distinct(student_result,maths,.keep_all = TRUE)输出:
> duplicated(student_result)
[1] FALSE FALSE FALSE FALSE FALSE TRUE TRUE
> sum(duplicated(student_result))
[1] 2
删除重复数据
方法
- 创建数据框
- 选择唯一的行
- 检索这些行
- 显示结果
方法 1:使用 unique()
我们使用 unique() 来获取数据中具有唯一值的行。
句法:
unique(dataframe)
例子:
电阻
# Creating a sample data frame of students
# and their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
unique(student_result)
输出:

方法 2:使用 distinct()
应安装包“tidyverse”并加载“dplyr”库以使用 distinct()。我们使用 distinct() 来获取数据中具有不同值的行。
Syntax:
distinct(dataframe,keepall)
Parameter:
- dataframe: data in use
- keepall: decides which variables to keep
例子:
电阻
# Creating a sample data frame of students and
# their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
distinct(student_result)
输出:

示例 2:根据数学列打印唯一行
电阻
# Creating a sample data frame of students and
# their marks in respective subjects.
student_result=data.frame(name=c("Ram","Geeta","John","Paul",
"Cassie","Geeta","Paul"),
maths=c(7,8,8,9,10,8,9),
science=c(5,7,6,8,9,7,8),
history=c(7,7,7,7,7,7,7))
# Printing data
student_result
distinct(student_result,maths,.keep_all = TRUE)
输出: