Pandas – 多索引和 groupbys
在本文中,我们将讨论Pandas Dataframe 和 Groupby 操作的多索引。
多索引允许您在索引中选择多个行和列。它是 pandas 对象的多级或分层对象。现在有多种使用多索引的方法,例如MultiIndex.from_arrays, MultiIndex.from_tuples, MultiIndex.from_product, MultiIndex.from_frame , etc 帮助我们从数组、元组、数据帧等创建多个索引。
Syntax: pandas.MultiIndex(levels=None, codes=None, sortorder=None, names=None, dtype=None, copy=False, name=None, verify_integrity=True)
- levels: It is a sequence of arrays which shows the unique labels for each level.
- codes: It is also a sequence of arrays where integers at each level helps us to designate the labels in that location.
- sortorder: optional int. It helps us to sort the levels lexographically.
- dtype:data-type(size of the data which can be of 32 bits or 64 bits)
- copy: It is a boolean type parameter with default value as False. It helps us to copy the metadata.
- verify_integrity: It is a boolean type parameter with default value as True. It checks the integrity of the levels and codes i.t if they are valid.
让我们看一些例子来更好地理解这个概念。
示例 1:
在这个例子中,我们将从数组创建多索引。数组比元组更受欢迎,因为元组是不可变的,而如果我们想更改数组中元素的值,我们可以这样做。因此,让我们转到代码及其解释:
导入所有重要的库后,我们将分别创建一个名称数组以及标记和年龄数组。现在在 MultiIndex.from_arrays 的帮助下,我们将所有三个数组组合在一起,以便来自所有三个数组的元素一起形成多个索引。之后,我们展示了上面的结果。
Python3
# importing pandas library from
# python
import pandas as pd
# Creating an array of names
arrays = ['Sohom','Suresh','kumkum','subrata']
# Creating an array of ages
age= [10, 11, 12, 13]
# Creating an array of marks
marks=[90,92,23,64]
# Using MultiIndex.from_arrays, we are
# combining the arrays together along
# with their names and creating multi-index
# with each element from the 3 arrays into
# different rows
pd.MultiIndex.from_arrays([arrays,age,marks], names=('names', 'age','marks'))Python3
# importing pandas library from
# python
import pandas as pd
# Creating data
Information = {'name': ["Saikat", "Shrestha", "Sandi", "Abinash"],
'Jobs': ["Software Developer", "System Engineer",
"Footballer", "Singer"],
'Annual Salary(L.P.A)': [12.4, 5.6, 9.3, 10]}
# Dataframing the whole data
df = pd.DataFrame(dict)
# Showing the above data
print(df)Python3
# creating multiple indexes from
# the dataframe
pd.MultiIndex.from_frame(df)Python3
# importing the pandas library
import pandas as pd
# making data for dataframing
data = {
'series': ['Peaky blinders', 'Sherlock', 'The crown',
'Queens Gambit', 'Friends'],
'Ratings': [4.5, 5, 3.9, 4.2, 5],
'Date': [2013, 2010, 2016, 2020, 1994]
}
# Dataframing the whole data created
df = pd.DataFrame(data)
# setting first and the second name
# as index column
df.set_index(["series", "Ratings"], inplace=True,
append=True, drop=False)
# display the dataframe
print(df)Python3
print(df.index)Python3
# importing pandas library
import numpy as np
# Creating pandas dataframe
df = pd.DataFrame(
[
("Corona Positive", 65, 99),
("Corona Negative", 52, 98.7),
("Corona Positive", 43, 100.1),
("Corona Positive", 26, 99.6),
("Corona Negative", 30, 98.1),
],
index=["Patient 1", "Patient 2", "Patient 3",
"Patient 4", "Patient 5"],
columns=("Status", "Age(in Years)", "Temperature"),
)
# show dataframe
print(df)Python3
# Grouping with only status
grouped1 = df.groupby("Status")
# Grouping with temperature and status
grouped3 = df.groupby(["Temperature", "Status"])Python3
# Finding the mean of the
# patients reports according to
# the status
grouped1.mean()Python3
# Grouping temperature and status together
# results in giving us the index values of
# the particular patient
grouped3.groups输出:

示例 2:
在这个例子中,我们将使用 Pandas 从数据帧创建多索引。我们将创建手动数据,然后使用pd.dataframe , 我们将使用一组数据创建一个数据框。现在使用多索引语法,我们将创建一个带有数据帧的多索引。
在这个例子中,我们和前面的例子做同样的事情。不同之处在于,在前面的示例中,我们从数组列表中创建了多索引,而在这里我们使用pd.dataframe创建了一个数据帧,之后我们使用多索引从该数据帧创建了多索引。 from_frame()以及名称。
蟒蛇3
# importing pandas library from
# python
import pandas as pd
# Creating data
Information = {'name': ["Saikat", "Shrestha", "Sandi", "Abinash"],
'Jobs': ["Software Developer", "System Engineer",
"Footballer", "Singer"],
'Annual Salary(L.P.A)': [12.4, 5.6, 9.3, 10]}
# Dataframing the whole data
df = pd.DataFrame(dict)
# Showing the above data
print(df)
输出:
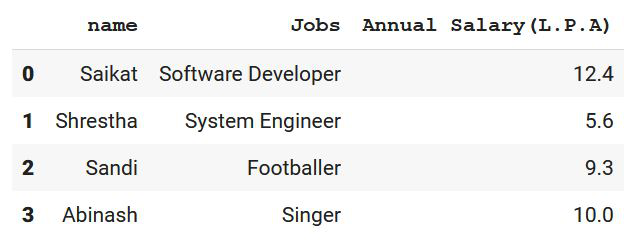
现在使用 MultiIndex.from_frame ,我们正在用这个数据帧创建多个索引。
蟒蛇3
# creating multiple indexes from
# the dataframe
pd.MultiIndex.from_frame(df)
输出:

示例 3:
在这个例子中,我们将学习dataframe.set_index([col1,col2,..]),我们将学习多个索引。这是多索引的另一个概念。
导入所需的库即pandas 后,我们正在创建数据,然后在pandas.DataFrame的帮助下,我们将其转换为表格格式。之后使用Dataframe.set_index我们将一些列设置为索引列(多索引)。 Drop 参数保持为 false,它不会删除作为索引列提到的列,此后 append 参数用于将传递的列附加到已经存在的索引列。
蟒蛇3
# importing the pandas library
import pandas as pd
# making data for dataframing
data = {
'series': ['Peaky blinders', 'Sherlock', 'The crown',
'Queens Gambit', 'Friends'],
'Ratings': [4.5, 5, 3.9, 4.2, 5],
'Date': [2013, 2010, 2016, 2020, 1994]
}
# Dataframing the whole data created
df = pd.DataFrame(data)
# setting first and the second name
# as index column
df.set_index(["series", "Ratings"], inplace=True,
append=True, drop=False)
# display the dataframe
print(df)
输出:
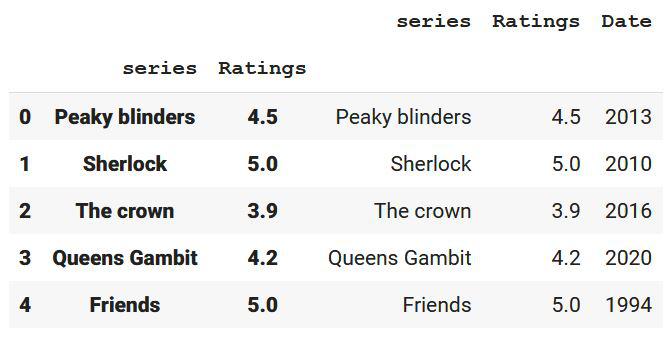
现在,我们以多索引的形式打印数据帧的索引。
蟒蛇3
print(df.index)
输出:

通过...分组
Pandas 中的groupby操作帮助我们通过应用函数来拆分对象,然后合并结果。根据我们的选择对列进行分组后,我们可以执行各种操作,最终可以帮助我们分析数据。
Syntax: DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=
- by: It helps us to group by a specific or multiple columns in the dataframe.
- axis: It has a default value of 0 where 0 stands for index and 1 stands for columns.
- level: Let us consider that the dataframe we are working with has hierarchical indexing. In that case level helps us to determine the level of the index we are working with.
- as_index: It is a boolean data-type with default value as true.It returns object with group labels as index.
- sort: It helps us to sort the key values. It is preferable to keep it as false for better performance.
- group_keys: It is also a boolean value with default value as true. It adds group keys to indexes to identify pieces
- dropna: It helps to drop the ‘NA‘ values in a dataset
示例 1:
在下面的示例中,我们将使用我们创建的数据探索 groupby 的概念。让我们进入代码实现。
蟒蛇3
# importing pandas library
import numpy as np
# Creating pandas dataframe
df = pd.DataFrame(
[
("Corona Positive", 65, 99),
("Corona Negative", 52, 98.7),
("Corona Positive", 43, 100.1),
("Corona Positive", 26, 99.6),
("Corona Negative", 30, 98.1),
],
index=["Patient 1", "Patient 2", "Patient 3",
"Patient 4", "Patient 5"],
columns=("Status", "Age(in Years)", "Temperature"),
)
# show dataframe
print(df)
输出:
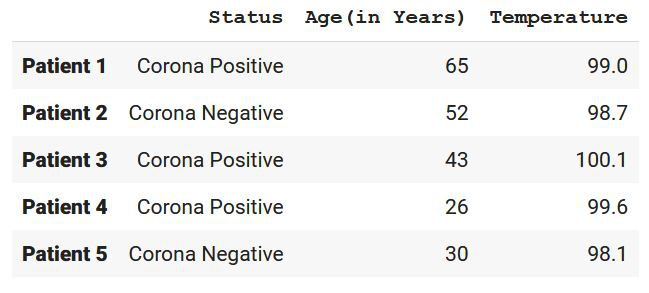
现在让我们根据一些特征对它们进行分组:
蟒蛇3
# Grouping with only status
grouped1 = df.groupby("Status")
# Grouping with temperature and status
grouped3 = df.groupby(["Temperature", "Status"])
正如我们所看到的,我们根据“状态”和“温度和状态”对它们进行了分组。现在让我们执行一些功能:
蟒蛇3
# Finding the mean of the
# patients reports according to
# the status
grouped1.mean()
这将根据“状态”创建数值的平均值。
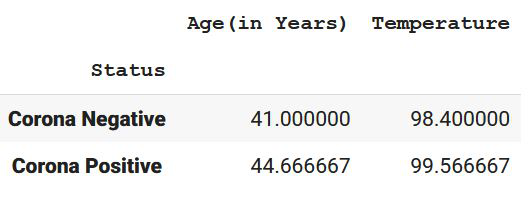
蟒蛇3
# Grouping temperature and status together
# results in giving us the index values of
# the particular patient
grouped3.groups
输出:
{(98.1, ‘Corona Negative’): [‘Patient 5’], (98.7, ‘Corona Negative’): [‘Patient 2’],
(99.0, ‘Corona Positive’): [‘Patient 1’], (99.6, ‘Corona Positive’): [‘Patient 4’],
(100.1, ‘Corona Positive’): [‘Patient 3’]}