- Merge_sort - Python (1)
- Merge_sort - Python 代码示例
- Python合并排序
- Python合并排序(1)
- Python的sort()(1)
- Python中的sort(1)
- Python中的sort
- Python的sort()
- 在 Julia 中合并字典集合——merge() 和 merge!() 方法
- 在 Julia 中合并字典集合——merge() 和 merge!() 方法(1)
- 就地合并排序 | 2套
- 合并排序(1)
- 3路合并排序(1)
- 就地合并排序(1)
- 合并排序
- 就地合并排序 | 2套(1)
- 3路合并排序
- 就地合并排序
- c++ sort - C++ (1)
- c++ sort - C++ (1)
- 在C++ STL中使用std :: merge()快速合并两个排序的数组
- 在C++ STL中使用std :: merge()快速合并两个排序的数组(1)
- 合并排序 java (1)
- 合并排序 - Java (1)
- 合并3个排序的数组(1)
- 合并3个排序的数组
- c 中字符串的合并排序(1)
- c++ sort - C++ 代码示例
- c++ sort - C++ 代码示例
📅 最后修改于: 2020-08-27 08:24:35 🧑 作者: Mango
介绍
合并排序是最著名的排序算法之一。如果您正在学习计算机科学,那么Merge Sort和Quick Sort可能是您听说过的第一种高效的通用排序算法。这也是算法的“ 分而治之”类别的经典示例。
合并排序
合并排序的工作方式是:
初始数组分为两个大致相等的部分。如果数组具有奇数个元素,则这些“一半”之一比另一个大一个元素。
子数组一遍又一遍地分成两半,直到最后得到每个只有一个元素的数组。
然后,您将一对一元素数组组合为两个元素数组,并在此过程中对它们进行排序。然后将这些已排序的对合并为四个元素的数组,依此类推,直到最终对初始数组进行排序为止。
这是合并排序的可视化:
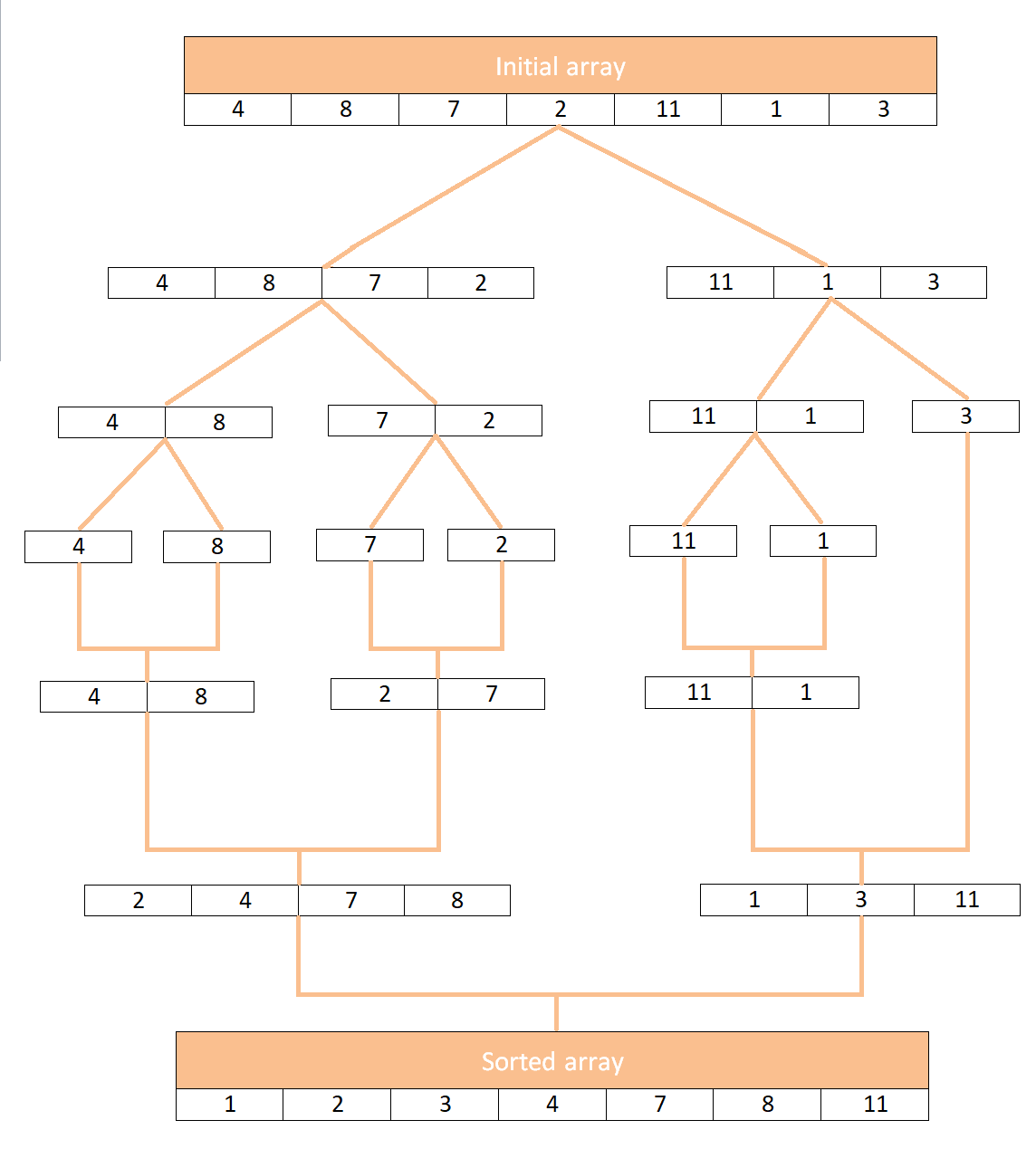
如您所见,无法将数组分成相等的一半并不是一个问题,三个数组只是“等待”直到排序开始。
我们可以采用两种主要方法来实现合并排序算法,一种是使用自上而下的方法(如上例所示),这是最常引入合并排序的方式。
另一种方法,即自下而上,沿相反的方向工作,而无需递归(迭代地工作)-如果我们的数组有N个元素,则将其划分为一个元素的N个子数组,并对相邻的一个元素数组进行排序,然后对相邻的两元素数组对,依此类推。
注:该自下而上的方法提供了一个有趣的优化,我们将讨论以后。我们将实现自上而下的方法,因为它更简单,更直观,并且在没有特定优化的情况下,它们之间的时间复杂度之间并没有真正的区别。
这两种方法的主要部分是我们如何将两个较小的数组合并(合并)为较大的数组。这是相当直观地完成的,假设我们检查了上一个示例中的最后一步。我们有数组:
- 答:2 4 7 8
- B:1 3 11
- 排序:空
我们要做的第一件事是查看两个数组的第一个元素。我们发现较小的那个(在我们的例子中是1),所以这是排序数组的第一个元素,然后在B数组中继续前进:
- 答:2 4 7 8
- B:1 3 11
- 排序:1
然后我们看下一对元素2和3;2较小,因此我们将其放在已排序的数组中,然后在数组A中继续前进。当然,我们不会在数组B中前进,我们将指针保持在3以便将来进行比较:
- 答:2 4 7 8
- B:1 3 11
- 排序:1 2
使用相同的逻辑,我们遍历其余部分,最后得到{1、2、3、4、7、8、11}的数组。
可能发生的两种特殊情况是:
- 两个子数组具有相同的元素。我们可以向前移动任何一个,然后将元素添加到已排序的数组中。从技术上讲,我们可以在两个数组中继续前进,并将两个元素都添加到已排序的数组中,但是当我们在两个数组中遇到相同的元素时,这将需要特殊的行为。
- 我们“用完”一个子数组中的元素。例如,我们有一个数组{1,2,3}和一个数组{9,10,11}。显然,我们将遍历第一个数组中的所有元素,甚至在第二个数组中都不会前进。每当我们用完子数组中的元素时,我们只需将第二个元素的元素添加到另一个元素中。
请记住,我们可以根据需要进行排序-此示例以升序对整数进行排序,但是我们可以轻松地以降序进行排序或对自定义对象进行排序。
实现代码
我们将在两种类型的集合上实现合并排序-在整数数组(通常用于引入排序)和自定义对象上(一种更加实际和现实的方案)。
我们将使用自顶向下的方法实现合并排序算法。该算法看起来不太“漂亮”,可能会造成混淆,因此我们将详细介绍每个步骤。
排序数组
让我们从简单的部分开始。该算法的基本思想是将(子)数组分成两半,然后对它们进行递归排序。我们希望继续做尽可能多的事情,即直到我们得到只有一个元素的子数组:
def merge_sort(array, left_index, right_index):
if left_index >= right_index:
return
middle = (left_index + right_index)//2
merge_sort(array, left_index, middle)
merge_sort(array, middle + 1, right_index)
merge(array, left_index, right_index, middle)
通过merge最后调用该方法,我们确保在开始排序之前所有划分都会发生。我们使用//运算符来明确表示我们希望索引使用整数值这一事实。
下一步是通过一些步骤和方案进行的实际合并部分:
- 创建数组的副本。第一个数组是的子数组
[left_index,..,middle],第二个是的子数组[middle+1,...,right_index] - 我们遍历两个副本(跟踪两个数组中的指针),选择当前正在查看的两个元素中较小的一个,并将它们添加到已排序的数组中。无论从哪个数组中选择元素,我们都将向前移动,并在已排序的数组中继续向前。
- 如果我们用完一个副本中的元素用尽了,只需将另一个副本中的剩余元素添加到排序数组中即可。
根据我们的要求,让我们继续定义一个merge()函数:
def merge(array, left_index, right_index, middle):
# Make copies of both arrays we're trying to merge
# The second parameter is non-inclusive, so we have to increase by 1
left_copy = array[left_index:middle + 1]
right_copy = array[middle+1:right_index+1]
# Initial values for variables that we use to keep
# track of where we are in each array
left_copy_index = 0
right_copy_index = 0
sorted_index = left_index
# Go through both copies until we run out of elements in one
while left_copy_index < len(left_copy) and right_copy_index < len(right_copy):
# If our left_copy has the smaller element, put it in the sorted
# part and then move forward in left_copy (by increasing the pointer)
if left_copy[left_copy_index] <= right_copy[right_copy_index]:
array[sorted_index] = left_copy[left_copy_index]
left_copy_index = left_copy_index + 1
# Opposite from above
else:
array[sorted_index] = right_copy[right_copy_index]
right_copy_index = right_copy_index + 1
# Regardless of where we got our element from
# move forward in the sorted part
sorted_index = sorted_index + 1
# We ran out of elements either in left_copy or right_copy
# so we will go through the remaining elements and add them
while left_copy_index < len(left_copy):
array[sorted_index] = left_copy[left_copy_index]
left_copy_index = left_copy_index + 1
sorted_index = sorted_index + 1
while right_copy_index < len(right_copy):
array[sorted_index] = right_copy[right_copy_index]
right_copy_index = right_copy_index + 1
sorted_index = sorted_index + 1
现在让我们测试一下程序:
array = [33, 42, 9, 37, 8, 47, 5, 29, 49, 31, 4, 48, 16, 22, 26]
merge_sort(array, 0, len(array) -1)
print(array)
输出为:
[4, 5, 8, 9, 16, 22, 26, 29, 31, 33, 37, 42, 47, 48, 49]排序自定义对象
现在我们已经掌握了基本算法,接下来我们来看看如何对自定义类进行排序。我们可以覆盖__eq__,__le__,__ge__并根据需要为这个其他运营商。
这使我们可以使用与上述相同的算法,但将我们限制为仅一种对自定义对象进行排序的方法,在大多数情况下,这不是我们想要的。一个更好的主意是使算法本身更具通用性,然后将比较函数传递给它。
首先,我们将实现一个自定义类,Car并向其中添加一些字段:
class Car:
def __init__(self, make, model, year):
self.make = make
self.model = model
self.year = year
def __str__(self):
return str.format("Make: {}, Model: {}, Year: {}", self.make, self.model, self.year)
然后,我们将对“合并排序”方法进行一些更改。实现我们想要的最简单的方法是使用lambda函数。您可以看到我们仅添加了一个额外的参数并相应地更改了方法调用,并且仅使用另一行代码使此算法更加通用:
def merge(array, left_index, right_index, middle, comparison_function):
left_copy = array[left_index:middle + 1]
right_copy = array[middle+1:right_index+1]
left_copy_index = 0
right_copy_index = 0
sorted_index = left_index
while left_copy_index < len(left_copy) and right_copy_index < len(right_copy):
# We use the comparison_function instead of a simple comparison operator
if comparison_function(left_copy[left_copy_index], right_copy[right_copy_index]):
array[sorted_index] = left_copy[left_copy_index]
left_copy_index = left_copy_index + 1
else:
array[sorted_index] = right_copy[right_copy_index]
right_copy_index = right_copy_index + 1
sorted_index = sorted_index + 1
while left_copy_index < len(left_copy):
array[sorted_index] = left_copy[left_copy_index]
left_copy_index = left_copy_index + 1
sorted_index = sorted_index + 1
while right_copy_index < len(right_copy):
array[sorted_index] = right_copy[right_copy_index]
right_copy_index = right_copy_index + 1
sorted_index = sorted_index + 1
def merge_sort(array, left_index, right_index, comparison_function):
if left_index >= right_index:
return
middle = (left_index + right_index)//2
merge_sort(array, left_index, middle, comparison_function)
merge_sort(array, middle + 1, right_index, comparison_function)
merge(array, left_index, right_index, middle, comparison_function)
让我们在一些Car实例上测试或修改算法:
car1 = Car("Alfa Romeo", "33 SportWagon", 1988)
car2 = Car("Chevrolet", "Cruze Hatchback", 2011)
car3 = Car("Corvette", "C6 Couple", 2004)
car4 = Car("Cadillac", "Seville Sedan", 1995)
array = [car1, car2, car3, car4]
merge_sort(array, 0, len(array) -1, lambda carA, carB: carA.year < carB.year)
print("Cars sorted by year:")
for car in array:
print(car)
print()
merge_sort(array, 0, len(array) -1, lambda carA, carB: carA.make < carB.make)
print("Cars sorted by make:")
for car in array:
print(car)
我们得到输出:
Cars sorted by year:
Make: Alfa Romeo, Model: 33 SportWagon, Year: 1988
Make: Cadillac, Model: Seville Sedan, Year: 1995
Make: Corvette, Model: C6 Couple, Year: 2004
Make: Chevrolet, Model: Cruze Hatchback, Year: 2011
Cars sorted by make:
Make: Alfa Romeo, Model: 33 SportWagon, Year: 1988
Make: Cadillac, Model: Seville Sedan, Year: 1995
Make: Chevrolet, Model: Cruze Hatchback, Year: 2011
Make: Corvette, Model: C6 Couple, Year: 2004
优化
现在,让我们详细说明自上而下和自下而上的合并排序之间的区别。自下而上的工作方式类似于自顶向下方法的后半部分,在该方法中,我们递归地对相邻的子数组进行排序,而不是递归地调用对分的子数组。
我们可以做的改进该算法的一件事是在分解数组之前考虑排序的块而不是单个元素。
这意味着在给定诸如{4,8,7,2,11,11,1,3}的数组的情况下,而不是将其分解为{4},{8},{7},{2},{ 11},{1},{3} -分为可能已经排序的子数组:{4,8},{7},{2,11},{1,3},然后对其进行排序。
对于现实生活中的数据,我们经常会有很多这些已经排序的子数组,这些子数组可以显着缩短合并排序的执行时间。
合并排序要考虑的另一件事,尤其是自上而下的版本是多线程。合并排序对此很方便,因为每个半都可以独立于其对进行排序。我们唯一需要确定的是,在合并它们之前,我们已经完成了对每一半的排序。
但是,对于较小的数组,合并排序相对效率较低(在时间和空间上),并且通常通过在到达约7个元素的数组时停止而不是下移到具有一个元素的数组并调用Insertion Sort来进行优化。在合并为更大的数组之前,对它们进行排序。
这是因为插入排序对于小型和/或几乎排序的数组非常有效。
结论
合并排序是一种高效的通用排序算法。它的主要优点是算法的可靠运行时间以及排序大型数组时的效率。与“快速排序”不同,它不依赖于任何导致不良运行时的不幸决定。
主要缺点之一是,合并排序之前,合并排序用于存储阵列的临时副本的额外内存。但是,“合并排序”是一个很好的直观示例,它向未来的软件工程师介绍了分而治之的算法创建方法。
我们已经通过用于比较的lambda函数在简单的整数数组和自定义对象上实现了合并排序。最后,简要讨论了两种方法的可能优化。