- IMS DB-DL / I功能
- IMS DB-DL I功能(1)
- IMS DB-DL I术语(1)
- IMS DB-DL / I术语
- IMS DB-编程(1)
- IMS DB-编程
- IMS DB教程(1)
- IMS DB教程
- 讨论IMS DB(1)
- 讨论IMS DB
- IMS DB-概述(1)
- IMS DB-概述
- IMS DB-结构(1)
- IMS DB-结构
- IMS DB-控制块(1)
- IMS DB-控制块
- IMS DB-恢复(1)
- IMS DB-恢复
- IMS DB-有用的资源
- IMS DB-有用的资源(1)
- IMS DB-逻辑数据库
- IMS DB-逻辑数据库(1)
- IMS DB-数据处理
- IMS DB-数据处理(1)
- IMS DB问题与解答(1)
- IMS DB问题与解答
- IMS DB-二级索引
- IMS DB-二级索引(1)
- IMS DB-SSA(1)
📅 最后修改于: 2020-11-27 05:15:32 🧑 作者: Mango
IMS DB在不同级别存储数据。通过从应用程序发出DL / I调用来检索和插入数据。在接下来的章节中,我们将详细讨论DL / I呼叫。数据可以通过以下两种方式处理-
- 顺序处理
- 随机处理
顺序处理
当从数据库中顺序检索分段时,DL / I遵循预定义的模式。让我们了解IMS DB的顺序处理。
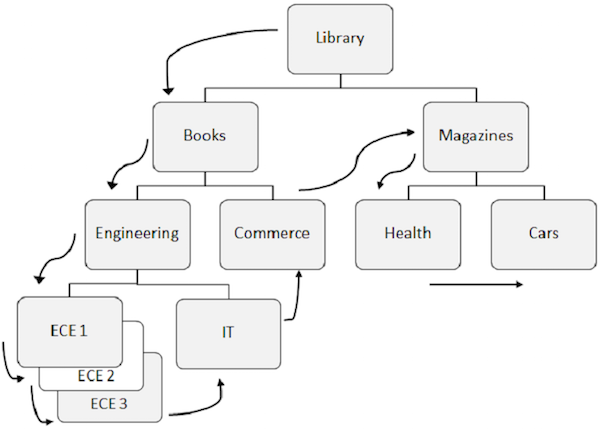
以下列出的是有关顺序处理的注意事项-
-
用于访问DL / I中数据的预定义模式首先是在层次结构中,然后是从左到右。
-
首先检索根段,然后DL / I移到第一个左孩子,然后下降到最低层。在最低级别上,它检索所有出现的双节段。然后转到正确的段。
-
为了更好地理解,请观察上图中的箭头,这些箭头显示了访问这些段的流程。库是根段,流程从那里开始,一直到汽车访问单个记录为止。对于所有事件重复相同的过程以获取所有数据记录。
-
在访问数据时,程序将使用数据库中的位置,这有助于检索和插入段。
随机处理
随机处理也称为IMS DB中的直接数据处理。让我们以一个例子来理解IMS DB中的随机处理-
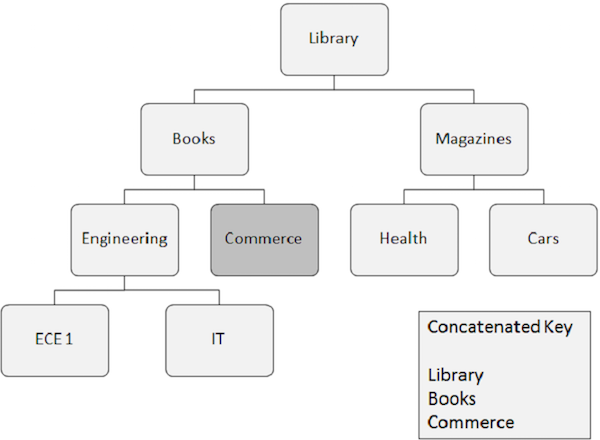
下面列出的是有关随机处理的注意事项-
-
需要随机检索的分段出现需要其依赖的所有分段的关键字段。这些关键字段由应用程序提供。
-
级联键可以完全标识从根段到要检索的段的路径。
-
假设您要检索Commerce细分的出现,那么您需要提供其依赖的细分的级联键字段值,例如Library,Books和Commerce。
-
随机处理比顺序处理要快。在实际情况中,应用程序将顺序和随机处理方法结合在一起以达到最佳效果。
关键领域
注意事项-
-
关键字段也称为序列字段。
-
段中存在一个关键字段,它用于检索段的出现。
-
关键字段按升序管理段出现。
-
在每个段中,只能将单个字段用作键字段或序列字段。
搜索领域
如前所述,只能将单个字段用作键字段。如果要搜索不是关键字段的其他段字段的内容,则用于检索数据的字段称为搜索字段。