📌 相关文章
- T-SQL-联接表
- SQL左联接(1)
- SQL左联接
- T-SQL-联接表(1)
- SQL-使用联接
- SQL-使用联接(1)
- SQL |联接(内联接、左联接、右联接和完全联接)
- SQL |联接(内联接、左联接、右联接和完全联接)(1)
- SQL删除联接
- SQL删除联接(1)
- SQL |联接(笛卡尔联接和自联接)(1)
- SQL |联接(笛卡尔联接和自联接)(1)
- SQL |联接(笛卡尔联接和自联接)
- SQL |联接(笛卡尔联接和自联接)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)
- SQL |联接(内部联接,左侧联接,右侧联接和完全联接)(1)
- MS SQL Server中的左联接和右联接(1)
- MS SQL Server中的左联接和右联接
- DocumentDB SQL-参数化
- DocumentDB SQL-参数化(1)
- 左联接和右联接之间的区别
- DocumentDB SQL-数组创建
- DocumentDB SQL-数组创建(1)
- DocumentDB SQL-运算符
- DocumentDB SQL-运算符(1)
- DocumentDB SQL教程(1)
- DocumentDB SQL教程
- 讨论DocumentDB SQL
- 讨论DocumentDB SQL(1)
📜 DocumentDB SQL-联接
📅 最后修改于: 2020-11-28 13:36:37 🧑 作者: Mango
在关系数据库中,Joins子句用于合并数据库中两个或多个表的记录,在设计规范化模式时,跨表连接的需求非常重要。由于DocumentDB处理的是无模式文档的非规范化数据模型,因此DocumentDB SQL中的JOIN在逻辑上等同于“自连接”。
让我们像前面的示例一样考虑这三个文档。
以下是AndersenFamily文档。
{
"id": "AndersenFamily",
"lastName": "Andersen",
"parents": [
{ "firstName": "Thomas", "relationship": "father" },
{ "firstName": "Mary Kay", "relationship": "mother" }
],
"children": [
{
"firstName": "Henriette Thaulow",
"gender": "female",
"grade": 5,
"pets": [ { "givenName": "Fluffy", "type": "Rabbit" } ]
}
],
"location": { "state": "WA", "county": "King", "city": "Seattle" },
"isRegistered": true
}
以下是SmithFamily文档。
{
"id": "SmithFamily",
"parents": [
{ "familyName": "Smith", "givenName": "James" },
{ "familyName": "Curtis", "givenName": "Helen" }
],
"children": [
{
"givenName": "Michelle",
"gender": "female",
"grade": 1
},
{
"givenName": "John",
"gender": "male",
"grade": 7,
"pets": [
{ "givenName": "Tweetie", "type": "Bird" }
]
}
],
"location": {
"state": "NY",
"county": "Queens",
"city": "Forest Hills"
},
"isRegistered": true
}
以下是WakefieldFamily文档。
{
"id": "WakefieldFamily",
"parents": [
{ "familyName": "Wakefield", "givenName": "Robin" },
{ "familyName": "Miller", "givenName": "Ben" }
],
"children": [
{
"familyName": "Merriam",
"givenName": "Jesse",
"gender": "female",
"grade": 6,
"pets": [
{ "givenName": "Charlie Brown", "type": "Dog" },
{ "givenName": "Tiger", "type": "Cat" },
{ "givenName": "Princess", "type": "Cat" }
]
},
{
"familyName": "Miller",
"givenName": "Lisa",
"gender": "female",
"grade": 3,
"pets": [
{ "givenName": "Jake", "type": "Snake" }
]
}
],
"location": { "state": "NY", "county": "Manhattan", "city": "NY" },
"isRegistered": false
}
让我们看一个示例,以了解JOIN子句如何工作。
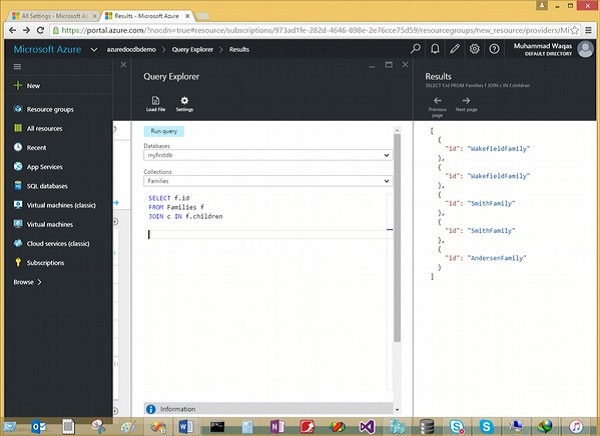
以下是将根连接到子级子文档的查询。
SELECT f.id
FROM Families f
JOIN c IN f.children
执行上述查询后,将产生以下输出。
[
{
"id": "WakefieldFamily"
},
{
"id": "WakefieldFamily"
},
{
"id": "SmithFamily"
},
{
"id": "SmithFamily"
},
{
"id": "AndersenFamily"
}
]
在上面的示例中,联接位于文档根目录和子级子根目录之间,这在两个JSON对象之间形成了叉积。以下是要注意的某些要点-
-
在FROM子句中,JOIN子句是迭代器。
-
前两个文档WakefieldFamily和SmithFamily包含两个孩子,因此结果集还包含叉积,该叉积为每个孩子产生一个单独的对象。
-
第三个文档AndersenFamily仅包含一个孩子,因此该文档仅对应一个对象。
让我们看一下相同的示例,但是这次我们也检索子名称以更好地理解JOIN子句。
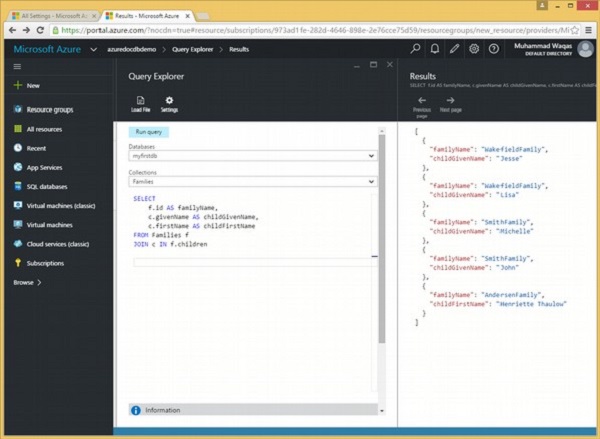
以下是将根连接到子级子文档的查询。
SELECT
f.id AS familyName,
c.givenName AS childGivenName,
c.firstName AS childFirstName
FROM Families f
JOIN c IN f.children
执行上述查询后,将产生以下输出。
[
{
"familyName": "WakefieldFamily",
"childGivenName": "Jesse"
},
{
"familyName": "WakefieldFamily",
"childGivenName": "Lisa"
},
{
"familyName": "SmithFamily",
"childGivenName": "Michelle"
},
{
"familyName": "SmithFamily",
"childGivenName": "John"
},
{
"familyName": "AndersenFamily",
"childFirstName": "Henriette Thaulow"
}
]