使用Python进行左右手检测
在本文中,我们将了解如何使用Python检测手部。
我们将在Python中使用mediapipe和OpenCV库来检测右手和左手。我们将使用 mediapipe 解决方案中的 Hands 模型来检测手部,它是一种手掌检测模型,可对完整图像进行操作并返回一个定向的手部边界框。
所需的库
- Mediapipe是 Google 的开源框架,用于媒体处理。它是跨平台的,或者我们可以说它是平台友好的。它可以在 Android、iOS 和 Web 上运行,这就是跨平台的意思,可以在任何地方运行。
- 开放式CV 是一个Python库,旨在解决计算机视觉问题。 OpenCV 支持多种编程语言,如 C++、 Python、 Java等。支持多种平台,包括 Windows、Linux 和 MacOS。
安装所需的库
pip install mediapipe
pip install opencv-python逐步实施
第 1 步:导入所有必需的库
Python3
# Importing Libraries
import cv2
import mediapipe as mp
# Used to convert protobuf message
# to a dictionary.
from google.protobuf.json_format import MessageToDictPython3
# Initializing the Model
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False,
model_complexity=1
min_detection_confidence=0.75,
min_tracking_confidence=0.75,
max_num_hands=2)Python3
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return weather it is Right or Left Hand
label = MessageToDict(i)[
'classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (20, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q' is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
breakPython3
# Importing Libraries
import cv2
import mediapipe as mp
# Used to convert protobuf message to a dictionary.
from google.protobuf.json_format import MessageToDict
# Initializing the Model
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False,
model_complexity=1
min_detection_confidence=0.75,
min_tracking_confidence=0.75,
max_num_hands=2)
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return weather it is Right or Left Hand
label = MessageToDict(i)
['classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on
# left side of window
cv2.putText(img, label+' Hand',
(20, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand'
# on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q'
# is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
break第 2 步:初始化 Hands 模型
Python3
# Initializing the Model
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False,
model_complexity=1
min_detection_confidence=0.75,
min_tracking_confidence=0.75,
max_num_hands=2)
让我们看看手模型的参数:
Hands( static_image_mode=False, model_complexity=1 min_detection_confidence=0.75, min_tracking_confidence=0.75, max_num_hands=2 )
Where:
- static_image_mode: It is used to specify whether the input image must be static images or as a video stream. The default value is False.
- model_complexity: Complexity of the hand landmark model: 0 or 1. Landmark accuracy, as well as inference latency, generally go up with the model complexity. Default to 1.
- min_detection_confidence: It is used to specify the minimum confidence value with which the detection from the person-detection model needs to be considered as successful. Can specify a value in [0.0,1.0]. The default value is 0.5.
- min_tracking_confidence: It is used to specify the minimum confidence value with which the detection from the landmark-tracking model must be considered as successful. Can specify a value in [0.0,1.0]. The default value is 0.5.
- max_num_hands: Maximum number of hands to detect. Default it is 2.
步骤 3:手模型处理图像并检测手
使用 OpenCV 从相机连续捕获帧,然后围绕 y 轴翻转图像,即 cv2.flip(image, flip code) 并将 BGR 图像转换为 RGB 图像,并使用初始化的手模型进行预测。
模型所做的预测保存在 results 变量中,我们可以分别使用 results.multi_hand_landmarks 和 results.multi_handedness 访问地标,如果框架中存在手,请检查双手,如果是,则将文本“双手”放在单手图像,将 MessageToDict()函数存储在标签变量上。如果标签是“左”,则在图像上放置文本“左手”,如果标签是“右”,则在图像上放置文本“右手”。
Python3
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return weather it is Right or Left Hand
label = MessageToDict(i)[
'classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (20, 50),
cv2.FONT_HERSHEY_COMPLEX, 0.9,
(0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand' on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q' is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
break
下面是完整的实现:
Python3
# Importing Libraries
import cv2
import mediapipe as mp
# Used to convert protobuf message to a dictionary.
from google.protobuf.json_format import MessageToDict
# Initializing the Model
mpHands = mp.solutions.hands
hands = mpHands.Hands(
static_image_mode=False,
model_complexity=1
min_detection_confidence=0.75,
min_tracking_confidence=0.75,
max_num_hands=2)
# Start capturing video from webcam
cap = cv2.VideoCapture(0)
while True:
# Read video frame by frame
success, img = cap.read()
# Flip the image(frame)
img = cv2.flip(img, 1)
# Convert BGR image to RGB image
imgRGB = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# Process the RGB image
results = hands.process(imgRGB)
# If hands are present in image(frame)
if results.multi_hand_landmarks:
# Both Hands are present in image(frame)
if len(results.multi_handedness) == 2:
# Display 'Both Hands' on the image
cv2.putText(img, 'Both Hands', (250, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# If any hand present
else:
for i in results.multi_handedness:
# Return weather it is Right or Left Hand
label = MessageToDict(i)
['classification'][0]['label']
if label == 'Left':
# Display 'Left Hand' on
# left side of window
cv2.putText(img, label+' Hand',
(20, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
if label == 'Right':
# Display 'Left Hand'
# on left side of window
cv2.putText(img, label+' Hand', (460, 50),
cv2.FONT_HERSHEY_COMPLEX,
0.9, (0, 255, 0), 2)
# Display Video and when 'q'
# is entered, destroy the window
cv2.imshow('Image', img)
if cv2.waitKey(1) & 0xff == ord('q'):
break
输出:
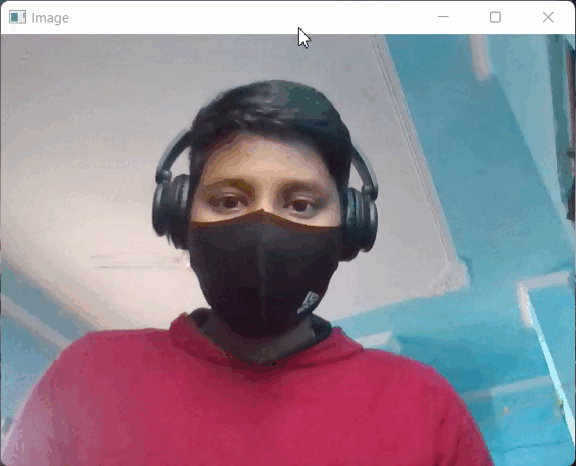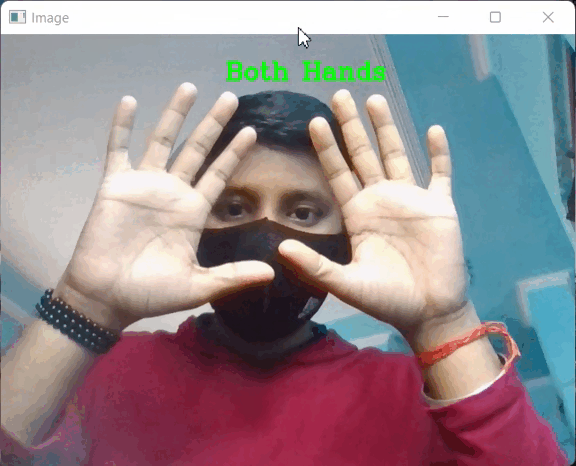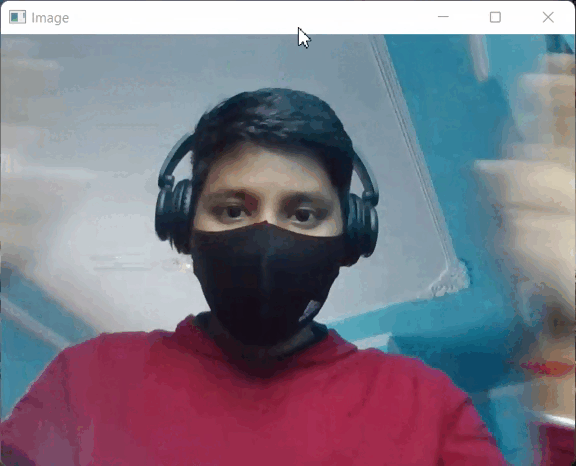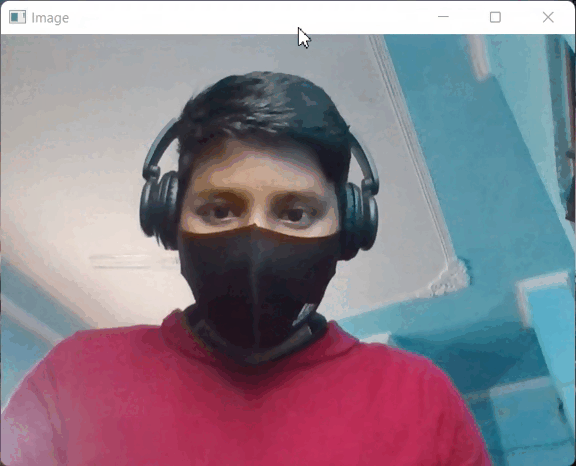
输出