项目 | Scikit-learn – 威士忌聚类
简介 | Scikit-学习
Scikit-learn 是Python的机器学习库。它具有各种分类、回归和聚类算法,包括支持向量机、随机森林、梯度提升、k-means 和 DBSCAN,旨在与Python数值和科学库 NumPy 互操作和 SciPy。从这里了解更多关于 Scikit-learn 的信息。
案例研究 |集群威士忌
目标和描述:苏格兰威士忌因其复杂性和多种风味而备受推崇。据信生产苏格兰威士忌的地区具有不同的风味特征。在本案例研究中,我们将根据苏格兰威士忌的风味特征对其进行分类。我们将使用的数据集包含来自多家酿酒厂的精选苏格兰威士忌,我们将尝试将威士忌分成风味相似的组。本案例研究将加深您对 Pandas、NumPy 和 scikit-learn 的理解,以及也许是苏格兰威士忌。
来源:下载威士忌区域数据集和威士忌品种数据集。我们将把这些数据集放在工作路径目录中。我们将使用的数据集包括苏格兰几乎所有活跃的威士忌酒厂的一种现成的单一麦芽苏格兰威士忌的品尝评级. 生成的数据集包含 86 种麦芽威士忌,在 12 个不同的口味类别中得分在 0 到 4 之间。分数来自 10 个不同的品尝者。口味类别描述了威士忌是甜味、烟熏味、药用味、辛辣味等.
◊ 成对相关 ◊
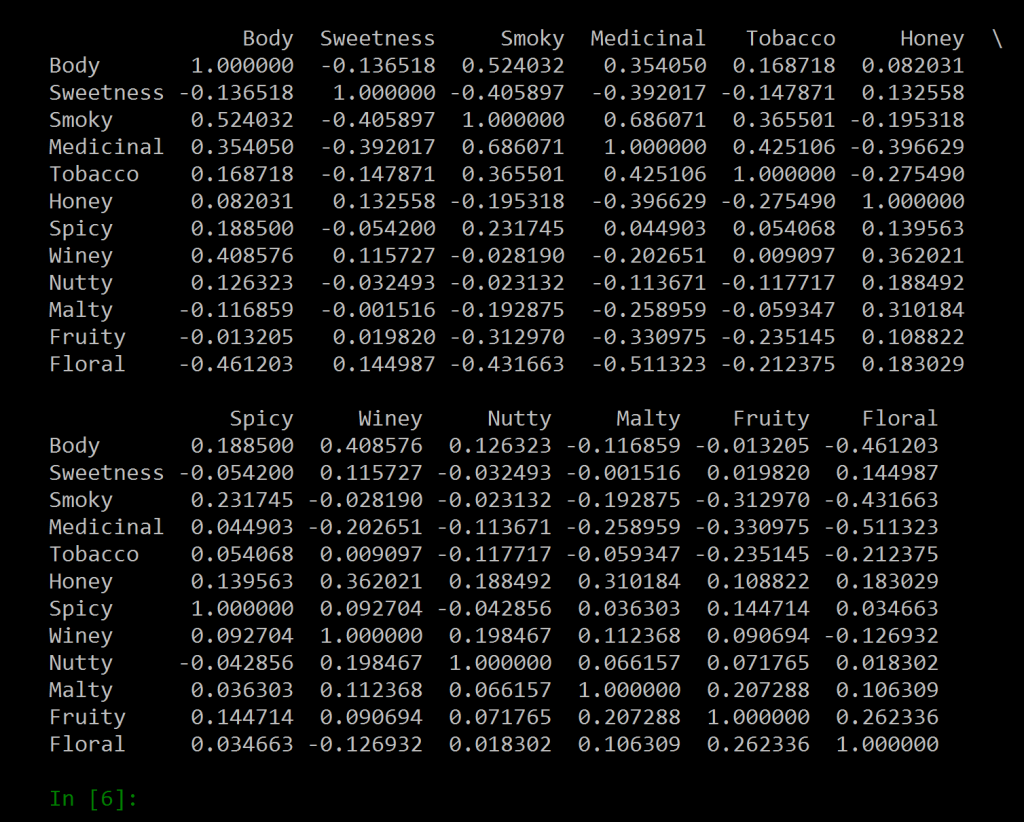
威士忌品种数据集包含 86 行麦芽威士忌测试分数和 17 列口味类别。我们使用代码whisky[“Region”] = pd.read_csv(“regions.txt”)在数据集中添加另一列,现在是 86行和 18 列(新列是区域信息)。所有 18 列名称都可以在命令>>>whisky.columns的帮助下找到。我们使用whisky.iloc [:将范围缩小到18 行和12 列: , 2:14]命令并将结果存储在名为 flavor 的变量中。使用 corr() 方法我们计算风味变量列的成对相关性。我们编码,
Python
import numpy as np
import pandas as pd
whisky = pd.read_csv("whiskies.txt")
whisky["Region"] = pd.read_csv("regions.txt")
# >>>whisky.head(), iloc method to index a data frame by location.
# >>>whisky.iloc[0:10], we specified the rows from 0 - 9
# >>>whisky.iloc[0:10, 0:5], we specified the rows from 0 - 9 & columns from 0-5
# >>>whisky.columns
flavors = whisky.iloc[:, 2:14]
corr_flavors = pd.DataFrame.corr(flavors)
print(corr_flavors)Python
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.pcolor(corr_flavors)
plt.colorbar()
#>>>plt.savefig("corlate-whisky1.pdf")
corr_whisky = pd.DataFrame.corr(flavors.transpose())
plt.figure(figsize=(10, 10))
plt.pcolor(corr_whisky)
plt.axis("tight")
plt.colorbar()
#>>>plt.savefig("corlate-whisky2.pdf")
plt.show()Python
from sklearn.cluster.bicluster import SpectralCoclustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
model = SpectralCoclustering(n_clusters=6, random_state=0)
model.fit(corr_whisky)
model.rows_
#>>>np.sum(model.rows_, axis=1)
#>>>np.sum(model.rows_, axis=0)
model.row_labels_Python
from sklearn.cluster.bicluster import SpectralCoclustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
whisky['Group'] = pd.Series(model.row_labels_, index = whisky.index)
whisky = whisky.ix[np.argsort(model.row_labels_)]
whisky = whisky.reset_index(drop=True)
correlations = pd.DataFrame.corr(whisky.iloc[:, 2:14].transpose())
correlations = np.array(correlations)
plt.figure(figsize = (14, 7))
plt.subplot(121)
plt.pcolor(corr_whisky)
plt.title("Original")
plt.axis("tight")
plt.subplot(122)
plt.pcolor(correlations)
plt.title("Rearranged")
plt.axis("tight")
plt.show()
plt.savefig("correlations.pdf")输出:相关DataFrame是:
◊ 绘制成对相关 ◊
我们将使用 matplotlib plot 绘制相关 DataFrame。为方便起见,我们将在 plot 中显示一个颜色条。我们编写代码,
Python
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.pcolor(corr_flavors)
plt.colorbar()
#>>>plt.savefig("corlate-whisky1.pdf")
corr_whisky = pd.DataFrame.corr(flavors.transpose())
plt.figure(figsize=(10, 10))
plt.pcolor(corr_whisky)
plt.axis("tight")
plt.colorbar()
#>>>plt.savefig("corlate-whisky2.pdf")
plt.show()
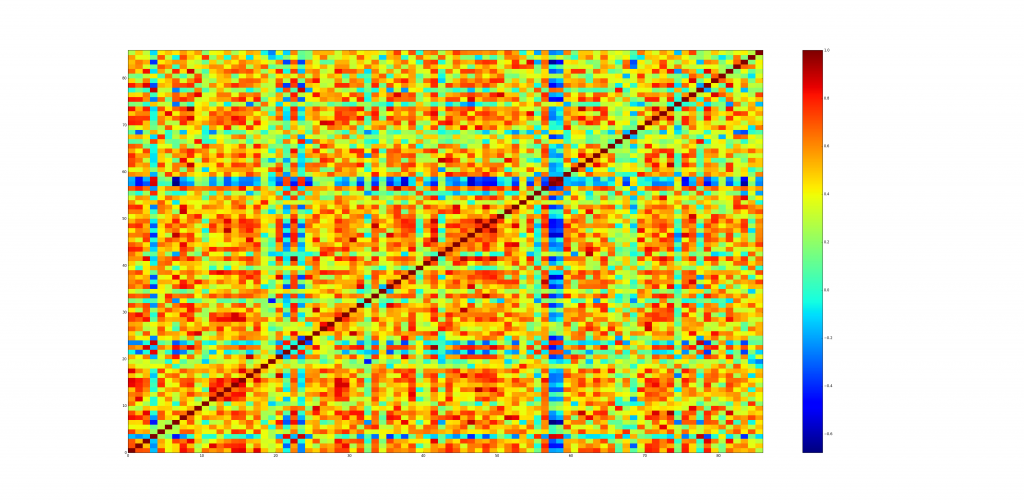
输出:在图 1 和 2 中,蓝色表示最小相关性,红色表示最大相关性。第一个图是所有口味类别的正态相关性,第二个图是麦芽威士忌测试分数之间的相关性。第二个图由于列数较多(86),绘图相对于第一个看起来更复杂。

◊ 光谱共聚 ◊
联合聚类的目标是同时聚类输入数据矩阵的行和列。矩阵被传递给光谱联合聚类算法。
Python
from sklearn.cluster.bicluster import SpectralCoclustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
model = SpectralCoclustering(n_clusters=6, random_state=0)
model.fit(corr_whisky)
model.rows_
#>>>np.sum(model.rows_, axis=1)
#>>>np.sum(model.rows_, axis=0)
model.row_labels_
输出:我们使用 SpectralCoclustering() 对数组的行和列进行聚类。上述代码的输出为:

◊ 比较相关数据 ◊
我们将导入必要的模块并按组对数据进行排序。我们尝试并排比较重新排列的相关性与原始相关性之间的图。我们编码,
Python
from sklearn.cluster.bicluster import SpectralCoclustering
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
whisky['Group'] = pd.Series(model.row_labels_, index = whisky.index)
whisky = whisky.ix[np.argsort(model.row_labels_)]
whisky = whisky.reset_index(drop=True)
correlations = pd.DataFrame.corr(whisky.iloc[:, 2:14].transpose())
correlations = np.array(correlations)
plt.figure(figsize = (14, 7))
plt.subplot(121)
plt.pcolor(corr_whisky)
plt.title("Original")
plt.axis("tight")
plt.subplot(122)
plt.pcolor(correlations)
plt.title("Rearranged")
plt.axis("tight")
plt.show()
plt.savefig("correlations.pdf")
输出:在输出图中,第一个图是原始的相关图,第二个是排序和重新排列的图。两个图中的赤红色对角线表示相关比为 1。

参考 :
- edX –HarvardX – 使用Python进行研究
- Scikit-learn 聚类