- Apache MXNet教程
- Apache MXNet教程(1)
- Apache MXNet-简介
- Apache MXNet-简介(1)
- 讨论Apache MXNet(1)
- 讨论Apache MXNet
- Apache MXNet- Python API模块(1)
- Apache MXNet- Python API模块
- Apache MXNet- Python API符号(1)
- Apache MXNet- Python API符号
- Apache MXNet-NDArray
- Apache MXNet-NDArray(1)
- Apache MXNet-系统组件
- Apache MXNet-系统组件(1)
- Apache MXNet- Python API ndarray(1)
- Apache MXNet- Python API ndarray
- Apache MXNet-有用的资源
- Apache MXNet-有用的资源(1)
- Apache MXNet-系统架构
- Apache MXNet-系统架构(1)
- R软件包(1)
- R软件包
- Apache MXNet-Gluon(1)
- Apache MXNet-Gluon
- Apache MXNet- Python API胶合剂(1)
- Apache MXNet- Python API胶合剂
- Apache MXNet-统一操作员API(1)
- Apache MXNet-统一操作员API
- Apache MXNet-分布式培训(1)
📅 最后修改于: 2020-12-10 04:48:22 🧑 作者: Mango
在本章中,我们将学习Apache MXNet中可用的Python软件包。
重要的MXNet Python软件包
MXNet具有以下重要的Python软件包,我们将逐一讨论-
-
Autograd(自动分化)
-
NDArray
-
KVStore
-
胶子
-
可视化
首先,让我们从适用于Apache MXNet的Autograd Python软件包开始。
自动毕业
Autograd代表自动微分,用于将梯度从损耗度量反向传播回每个参数。与反向传播一起,它使用动态编程方法来有效地计算梯度。也称为反向模式自动微分。在许多参数影响单个损耗指标的“扇入”情况下,该技术非常有效。
什么是渐变?
梯度是神经网络训练过程的基础。他们基本上告诉我们如何更改网络参数以提高其性能。
正如我们所知道的是,神经网络(NN)由运算符,如资金,产品,卷积,等等。这些运算符,为他们的计算,使用参数,如卷积核的权重。我们必须找到这些参数的最佳值,并且梯度为我们提供了方法,并也为我们提供了解决方案。
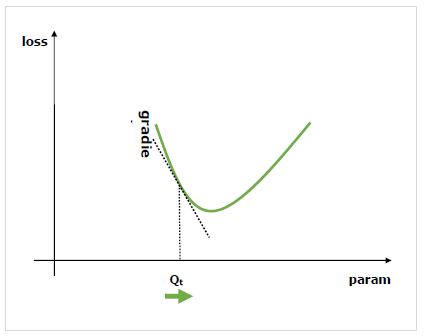
我们对更改参数对网络性能的影响感兴趣,并且梯度告诉我们,当更改变量所依赖的变量时,给定变量会增加或减少多少。性能通常是通过使用我们试图将其最小化的损耗指标来定义的。例如,对于回归,我们可以尝试使预测值和精确值之间的L2损失最小化,而对于分类,我们可以使交叉熵损失最小化。
一旦我们参考损耗计算了每个参数的梯度,就可以使用优化器,例如随机梯度下降。
如何计算梯度?
我们有以下选项来计算梯度-
-
符号微分-第一个选项是符号微分,它计算每个梯度的公式。这种方法的缺点是,随着网络的不断深入和运算符的日益复杂,它会很快导致难以置信的冗长公式。
-
有限差分法-另一个选择是使用有限差分法,在每个参数上尝试略微不同,然后查看损耗度量如何响应。该方法的缺点是,它将在计算上昂贵并且可能具有差的数值精度。
-
自动微分-解决上述方法缺点的方法是,使用自动微分将梯度从损耗度量反向传播回每个参数。传播使我们能够采用动态编程方法来有效地计算梯度。此方法也称为反向模式自动微分。
自动分化(autograd)
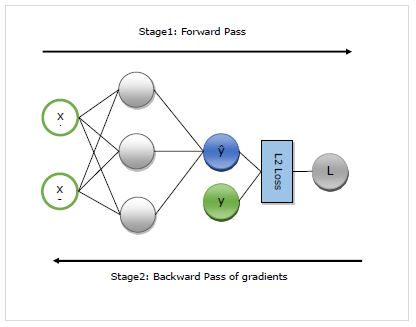
在这里,我们将详细了解autograd的工作。它基本上在以下两个阶段工作-
阶段1-此阶段称为培训的“前进通行证” 。顾名思义,在此阶段,它创建网络使用的运算符记录,以进行预测并计算损耗度量。
阶段2-此阶段称为培训的“后退阶段” 。顾名思义,在此阶段,它将在此记录中向后工作。向后,它将评估每个运算符的偏导数,一直返回到网络参数。
autograd的优点
以下是使用自动分化(autograd)的优点-
-
灵活-定义网络时为我们提供的灵活性是使用autograd的巨大好处之一。我们可以在每次迭代中更改操作。这些称为动态图,在需要静态图的框架中实现起来要复杂得多。即使在这种情况下,Autograd仍然可以正确地反向传播渐变。
-
自动-Autograd是自动的,即,它可以为您解决反向传播过程的复杂性。我们只需要指定对计算感兴趣的梯度即可。
-
高效-Autogard非常有效地计算梯度。
-
可以使用本机Python控制流运算符-我们可以使用本机Python控制流运算符,例如if条件和while循环。 autograd仍将能够有效且正确地反向传播梯度。
在MXNet Gluon中使用autograd
在这里,借助示例,我们将看到如何在MXNet Gluon中使用autograd 。
实施实例
在以下示例中,我们将实现具有两层的回归模型。实施后,我们将使用autograd参照每个权重参数自动计算损失的梯度-
首先导入autogrard和其他必需的软件包,如下所示:
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
现在,我们需要定义网络,如下所示:
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
现在我们需要定义损失如下:
loss_function = L2Loss()
接下来,我们需要创建虚拟数据,如下所示:
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
现在,我们已准备好通过网络进行第一个正向传递。我们希望autograd记录计算图,以便我们可以计算梯度。为此,我们需要在autograd.record上下文范围内运行网络代码,如下所示:
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
现在,我们准备好进行反向传递了,我们首先对感兴趣的数量调用反向方法。在我们的示例中,关注的四位数是损失,因为我们正在尝试参考参数来计算损失的梯度-
loss.backward()
现在,我们为网络的每个参数有了渐变,优化器将使用它们来更新参数值以提高性能。让我们检查一下第一层的渐变,如下所示:
N_net[0].weight.grad()
输出
输出如下-
[[-0.00470527 -0.00846948]
[-0.03640365 -0.06552657]
[ 0.00800354 0.01440637]]
完整的实施示例
下面给出了完整的实现示例。
from mxnet import autograd
import mxnet as mx
from mxnet.gluon.nn import HybridSequential, Dense
from mxnet.gluon.loss import L2Loss
N_net = HybridSequential()
N_net.add(Dense(units=3))
N_net.add(Dense(units=1))
N_net.initialize()
loss_function = L2Loss()
x = mx.nd.array([[0.5, 0.9]])
y = mx.nd.array([[1.5]])
with autograd.record():
y_hat = N_net(x)
loss = loss_function(y_hat, y)
loss.backward()
N_net[0].weight.grad()