- PyBrain – 使用网络
- PyBrain-使用网络
- PyBrain – 使用网络(1)
- PyBrain-PyBrain网络简介(1)
- PyBrain-PyBrain网络简介
- PyBrain-示例(1)
- PyBrain-示例
- PyBrain-使用递归网络(1)
- PyBrain-使用递归网络
- PyBrain-网络上的训练数据集
- PyBrain-网络上的训练数据集(1)
- PyBrain-连接
- PyBrain-连接(1)
- PyBrain-使用数据集
- PyBrain-使用数据集(1)
- PyBrain教程
- PyBrain教程(1)
- 讨论PyBrain(1)
- 讨论PyBrain
- PyBrain – 概述(1)
- PyBrain-概述(1)
- PyBrain-概述
- PyBrain – 概述
- 如何使用 PyBrain 将网络保存在 XML 文件中(1)
- 如何使用 PyBrain 将网络保存在 XML 文件中
- PyBrain-使用前馈网络(1)
- PyBrain-使用前馈网络
- PyBrain-数据集类型(1)
- PyBrain – 数据集类型(1)
📅 最后修改于: 2020-12-10 05:16:08 🧑 作者: Mango
在本章中,我们将看到一些示例,其中我们将训练数据并测试已训练数据上的错误。
我们将利用培训师-
BackpropTrainer
BackpropTrainer是一种训练器,通过对错误(在整个时间范围内)进行反向传播,根据受监管的或CategoryDataSet数据集(可能是顺序的)来训练模块的参数。
TrainUntilConvergence
它用于在数据集中训练模块直至收敛。
当我们创建一个神经网络时,它将根据提供给它的训练数据进行训练,现在该网络是否被正确训练取决于在该网络上测试的测试数据的预测。
让我们一步一步地查看一个工作示例,该示例将在其中构建神经网络并预测训练错误,测试错误和验证错误。
测试我们的网络
以下是我们将测试网络的步骤-
- 导入所需的PyBrain和其他软件包
- 创建分类数据集
- 将数据集拆分为测试数据的25%和训练后的数据的75%
- 将Testdata和Trained数据转换回为分类数据集
- 创建一个神经网络
- 训练网络
- 可视化错误和验证数据
- 测试数据百分比错误
第1步
导入所需的PyBrain和其他软件包。
我们需要的软件包如下所示导入:
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
第2步
下一步是创建ClassificationDataSet。
对于数据集,我们将使用sklearn数据集中的数据集,如下所示-
在以下链接中引用sklearn的load_digits数据集-
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
# we are having inputs are 64 dim array and since the digits are from 0-9 the
classes considered is 10.
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i]) # adding sample to datasets
第三步
将数据集拆分为测试数据的25%和训练后的数据的75%-
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
因此,在这里,我们对数据集使用了一个名为splitWithProportion()的方法,该方法的值为0.25,它将数据集分为25%作为测试数据和75%作为训练数据。
第4步
将Testdata和Trained数据转换为ClassificationDataSet。
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
在数据集上使用splitWithProportion()方法会将数据集转换为superviseddataset,因此,如上一步所示,我们将数据集转换回categorydataset。
第5步
下一步是创建神经网络。
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
我们正在创建一个网络,其中从训练数据中使用输入和输出。
第6步
训练网络
现在重要的部分是在数据集上训练网络,如下所示:
trainer = BackpropTrainer(net, dataset=training_data,
momentum=0.1,learningrate=0.01,verbose=True,weightdecay=0.01)
我们正在使用BackpropTrainer()方法并在创建的网络上使用数据集。
步骤7
下一步是可视化错误和数据验证。
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
我们将在训练数据上使用一种名为trainUntilConvergence的方法,该方法将收敛10个历元。它将返回训练误差和验证误差,如下所示。蓝线显示训练错误,红线显示验证错误。
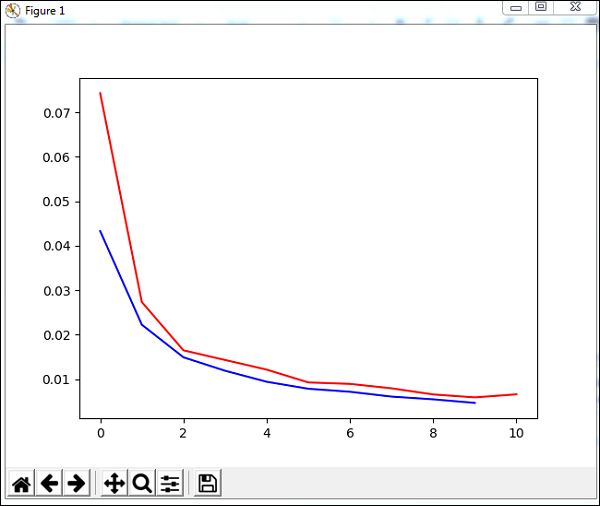
执行上述代码期间收到的总错误如下所示-
Total error: 0.0432857814358
Total error: 0.0222276374185
Total error: 0.0149012052174
Total error: 0.011876985318
Total error: 0.00939854792853
Total error: 0.00782202445183
Total error: 0.00714707652044
Total error: 0.00606068893793
Total error: 0.00544257958975
Total error: 0.00463929281336
Total error: 0.00441275665294
('train-errors:', '[0.043286 , 0.022228 , 0.014901 , 0.011877 , 0.009399 , 0.007
822 , 0.007147 , 0.006061 , 0.005443 , 0.004639 , 0.004413 ]')
('valid-errors:', '[0.074296 , 0.027332 , 0.016461 , 0.014298 , 0.012129 , 0.009
248 , 0.008922 , 0.007917 , 0.006547 , 0.005883 , 0.006572 , 0.005811 ]')
误差始于0.04,随后每个时期下降,这意味着网络正在接受训练,并且每个时期都在变得更好。
步骤8
测试数据错误百分比
我们可以使用percentError方法检查错误百分比,如下所示:
print('Percent Error on
testData:',percentError(trainer.testOnClassData(dataset=test_data),
test_data['class']))
testData的百分比误差-3.34075723830735
我们得到的误差百分比为3.34%,这意味着神经网络的准确性为97%。
以下是完整的代码-
from sklearn import datasets
import matplotlib.pyplot as plt
from pybrain.datasets import ClassificationDataSet
from pybrain.utilities import percentError
from pybrain.tools.shortcuts import buildNetwork
from pybrain.supervised.trainers import BackpropTrainer
from pybrain.structure.modules import SoftmaxLayer
from numpy import ravel
digits = datasets.load_digits()
X, y = digits.data, digits.target
ds = ClassificationDataSet(64, 1, nb_classes=10)
for i in range(len(X)):
ds.addSample(ravel(X[i]), y[i])
test_data_temp, training_data_temp = ds.splitWithProportion(0.25)
test_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, test_data_temp.getLength()):
test_data.addSample( test_data_temp.getSample(n)[0], test_data_temp.getSample(n)[1] )
training_data = ClassificationDataSet(64, 1, nb_classes=10)
for n in range(0, training_data_temp.getLength()):
training_data.addSample(
training_data_temp.getSample(n)[0], training_data_temp.getSample(n)[1]
)
test_data._convertToOneOfMany()
training_data._convertToOneOfMany()
net = buildNetwork(training_data.indim, 64, training_data.outdim, outclass=SoftmaxLayer)
trainer = BackpropTrainer(
net, dataset=training_data, momentum=0.1,
learningrate=0.01,verbose=True,weightdecay=0.01
)
trnerr,valerr = trainer.trainUntilConvergence(dataset=training_data,maxEpochs=10)
plt.plot(trnerr,'b',valerr,'r')
plt.show()
trainer.trainEpochs(10)
print('Percent Error on testData:',percentError(
trainer.testOnClassData(dataset=test_data), test_data['class']
))