- 使用Python机器学习-方法
- 使用Python机器学习-方法(1)
- 机器学习 python (1)
- 机器学习 python 代码示例
- 机器学习中的 P 值(1)
- C++中的机器学习
- 机器学习中的 P 值
- C++中的机器学习(1)
- 机器学习 (1)
- 使用Python进行机器学习
- 使用Python进行机器学习(1)
- 使用Python机器学习的教程(1)
- 使用Python机器学习的教程
- 使用Python机器学习的简介
- 使用Python机器学习简介(1)
- 使用Python机器学习的简介(1)
- 使用Python机器学习简介
- 使用 R 进行机器学习
- 学习 python 机器学习 - 任何代码示例
- 讨论使用Python机器学习
- 使用Python机器学习-基础(1)
- 使用Python机器学习-基础
- 机器学习 - 任何代码示例
- 机器学习-什么是P值(1)
- 机器学习-什么是P值
- 什么是机器学习?
- 在机器学习中什么是“i” (1)
- 什么是机器学习?(1)
- 机器学习-什么是机器学习? -指导点(1)
📅 最后修改于: 2020-12-10 05:28:49 🧑 作者: Mango
Python简介
Python是一种流行的面向对象的编程语言,具有高级编程语言的功能。它易于学习的语法和可移植性功能使其近来很受欢迎。以下事实为我们提供了Python的介绍-
-
Python由荷兰Stichting Mathematisch Centrum的Guido van Rossum开发。
-
它被编写为名为“ ABC”的编程语言的后继者。
-
它的第一个版本于1991年发布。
-
Python是Guido van Rossum在名为Monty Python’s Flying Circus的电视节目中选择的。
-
它是一种开放源代码编程语言,这意味着我们可以免费下载并使用它来开发程序。可以从www下载。 Python.org 。
-
Python编程语言同时具有Java和C的功能。它具有优雅的“ C”代码,另一方面,具有诸如Java的类和对象用于面向对象的编程。
-
它是一种解释型语言,这意味着Python程序的源代码将首先转换为字节码,然后由Python虚拟机执行。
Python的优点和缺点
每种编程语言都有其优点和缺点, Python也是如此。
长处
根据研究和调查, Python是机器学习和数据科学中第五重要的语言,也是最受欢迎的语言。 Python具有以下优点:
易于学习和理解-的Python语法比较简单;因此,即使对于初学者来说,也相对容易学习和理解该语言。
多用途语言Python是一种多用途编程语言,因为它支持结构化编程,面向对象的编程以及函数式编程。
大量的模块Python具有大量的模块,可涵盖编程的各个方面。这些模块易于使用,因此使Python成为可扩展的语言。
支持开源社区-作为开源编程语言, Python得到了非常大的开发人员社区的支持。因此, Python社区可以轻松修复这些错误。这个特性使Python非常健壮和自适应。
可扩展性Python是一种可扩展的编程语言,因为它提供了比shell脚本更好的结构来支持大型程序。
弱点
尽管Python是一种流行且功能强大的编程语言,但它也具有执行速度慢的缺点。
与Python相比, Python的执行速度较慢,因为Python是一种解释型语言。这可能是Python社区需要改进的主要领域。
安装Python
为了使用Python工作,我们必须首先安装它。您可以通过以下两种方式之一执行Python的安装-
-
单独安装Python
-
使用预打包的Python发行版-Anaconda
让我们分别详细讨论这些。
单独安装Python
如果要在计算机上安装Python ,则只需下载适用于您的平台的二进制代码。 Python发行版适用于Windows,Linux和Mac平台。
以下是在上述平台上安装Python的快速概述-
在Unix和Linux平台上
借助以下步骤,我们可以在Unix和Linux平台上安装Python
-
首先,请访问www。 Python.org / downloads / 。
-
接下来,单击链接以下载可用于Unix / Linux的压缩源代码。
-
现在,下载并解压缩文件。
-
接下来,如果要自定义一些选项,我们可以编辑“模块/设置”文件。
-
接下来,编写命令run ./configure脚本
-
使
-
进行安装
-
在Windows平台上
借助以下步骤,我们可以在Windows平台上安装Python
-
首先,请访问www。 Python.org / downloads / 。
-
接下来,单击Windows安装程序python-XYZ.msi文件的链接。 XYZ是我们希望安装的版本。
-
现在,我们必须运行下载的文件。它将带我们到易于使用的Python安装向导。现在,接受默认设置,并等待安装完成。
在Macintosh平台上
对于Mac OS X,建议使用Homebrew易于使用的软件包安装程序来安装Python 。如果没有Homebrew,则可以在以下命令的帮助下进行安装-
$ ruby -e "$(curl -fsSL
https://raw.githubusercontent.com/Homebrew/install/master/install)"
可以使用以下命令进行更新-
$ brew update
现在,要在您的系统上安装Python3,我们需要运行以下命令-
$ brew install python3
使用预打包的Python发行版:Anaconda
Anaconda是Python的打包版本,其中包含所有在数据科学中广泛使用的库。我们可以按照以下步骤使用Anaconda设置Python环境-
-
步骤1-首先,我们需要从Anaconda发行版下载所需的安装包。相同的链接是www.anaconda.com/distribution/ 。您可以根据需要从Windows,Mac和Linux操作系统中进行选择。
-
步骤2-接下来,选择要在计算机上安装的Python版本。最新的Python版本是3.7。在那里,您将同时获得64位和32位图形安装程序的选项。
-
步骤3-选择操作系统和Python版本后,它将在您的计算机上下载Anaconda安装程序。现在,双击该文件,安装程序将安装Anaconda软件包。
-
步骤4-要检查它是否已安装,请打开命令提示符并按如下所示键入Python
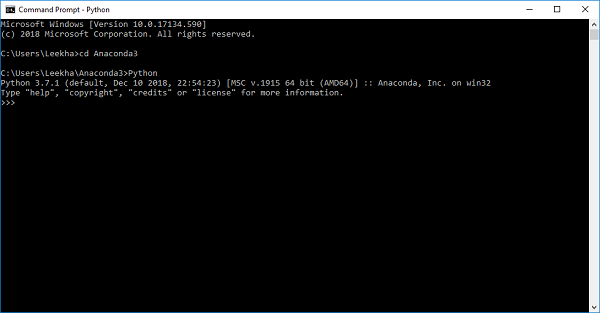
您也可以在www.tutorialspoint.com/python_essentials_online_training/getting_started_with_anaconda.asp上的详细视频讲座中查看此内容。
为什么选择Python进行数据科学?
Python是机器学习和数据科学中第五重要的语言,也是最受欢迎的语言。以下是Python的功能,使其成为数据科学语言的首选-
整套包装
Python有一套广泛而强大的软件包,可以在各个领域中使用。它还具有numpy,scipy,pandas,scikit-learn等软件包,它们是机器学习和数据科学所需的。
简单的原型制作
Python的另一个重要特性使它成为数据科学语言的选择,这是简单而快速的原型制作。此功能对于开发新算法很有用。
协作功能
数据科学领域基本上需要良好的协作,而Python提供了许多非常有用的工具。
一种语言适用于多种领域
一个典型的数据科学项目包括各个领域,例如数据提取,数据处理,数据分析,特征提取,建模,评估,部署和更新解决方案。由于Python是一种多用途语言,因此它允许数据科学家从一个通用平台访问所有这些领域。
Python ML生态系统的组成部分
在本节中,让我们讨论构成Python机器学习生态系统组件的一些核心数据科学库。这些有用的组件使Python成为数据科学的重要语言。尽管有很多这样的组件,但让我们在这里讨论Python生态系统的一些重要组件-
Jupyter笔记本
Jupyter笔记本基本上为开发基于Python的Data Science应用程序提供了一个交互式计算环境。它们以前称为ipython笔记本。以下是Jupyter笔记本的一些功能,使其成为Python ML生态系统的最佳组件之一-
-
Jupyter笔记本可以通过逐步安排诸如代码,图像,文本,输出等内容来逐步说明分析过程。
-
它有助于数据科学家在开发分析过程时记录思想过程。
-
人们还可以将结果记录为笔记本的一部分。
-
借助jupyter笔记本,我们也可以与同行分享我们的工作。
安装与执行
如果您正在使用Anaconda发行版,则无需单独安装jupyter笔记本,因为它已经安装了。您只需要转到Anaconda Prompt并键入以下命令-
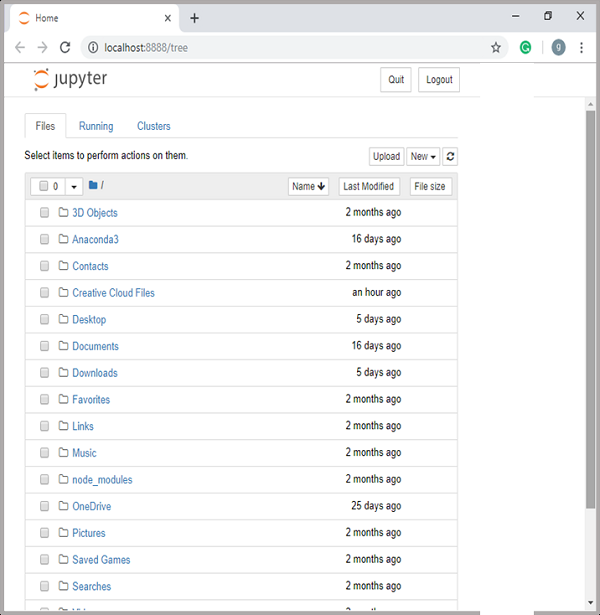
C:\>jupyter notebook
按Enter键后,它将在您计算机的localhost:8888处启动一个笔记本服务器。在以下屏幕截图中显示-
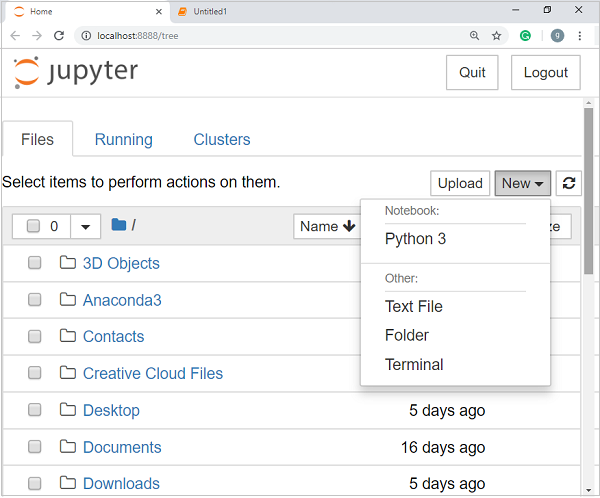
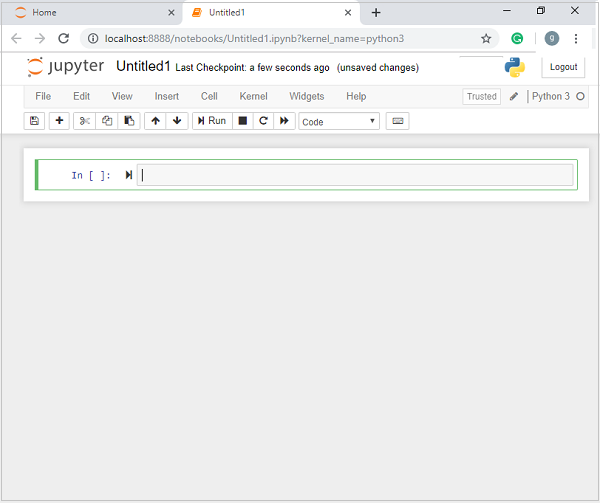
现在,单击“新建”选项卡后,您将获得一个选项列表。选择Python 3,它将带您进入新笔记本以开始使用它。您将在以下屏幕截图中瞥见它-
另一方面,如果您使用的是标准Python发行版,则可以使用流行的Python软件包安装程序pip安装jupyter notebook。
pip install jupyter
Jupyter Notebook中的单元格类型
以下是Jupyter笔记本中的三种单元格类型-
代码单元-顾名思义,我们可以使用这些单元来编写代码。编写代码/内容后,它将把它发送到与笔记本相关联的内核。
降价单元-我们可以使用这些单元来表示计算过程。它们可以包含文本,图像,Latex公式,HTML标签等内容。
原始单元格-写入其中的文本按原样显示。这些单元格基本上用于添加我们不希望通过jupyter notebook的自动转换机制转换的文本。
有关Jupyter Notebook的更详细研究,您可以转到链接www.tutorialspoint.com/jupyter/index.htm 。
NumPy
它是另一个有用的组件,使Python成为数据科学最喜欢的语言之一。它基本上代表数值Python ,由多维数组对象组成。通过使用NumPy,我们可以执行以下重要操作-
-
数组上的数学和逻辑运算。
-
傅立叶变换
-
与线性代数相关的运算。
我们还可以看到NumPy替代了MatLab,因为NumPy通常与Scipy(科学Python)和Mat-plotlib(绘图库)一起使用。
安装与执行
如果使用的是Anaconda发行版,则无需单独安装NumPy,因为它已经安装了。您只需要在以下帮助下将包导入到您的Python脚本中-
import numpy as np
另一方面,如果您使用的是标准Python发行版,则可以使用流行的Python软件包安装程序pip安装NumPy。
pip install NumPy
有关NumPy的更详细研究,您可以转到链接www.tutorialspoint.com/numpy/index.htm 。
大熊猫
它是另一个有用的Python库,使Python成为数据科学最喜欢的语言之一。熊猫基本上用于数据处理,整理和分析。它是由Wes McKinney在2008年开发的。在Pandas的帮助下,在数据处理中,我们可以完成以下五个步骤-
- 加载
- 准备
- 操作
- 模型
- 分析
熊猫中的数据表示
在以下三种数据结构的帮助下完成了Pandas中数据的完整表示-
系列-它基本上是带有轴标签的一维ndarray,这意味着它就像带有均质数据的简单数组。例如,以下系列是整数1,5,10,15,24,25的集合。
| 1 | 5 | 10 | 15 | 24 | 25 | 28 | 36 | 40 | 89 |
数据框-这是最有用的数据结构,用于熊猫中几乎所有类型的数据表示和处理。它基本上是一个二维数据结构,可以包含异构数据。通常,表格数据是通过使用数据帧表示的。例如,下表显示了具有姓名和卷号,年龄和性别的学生的数据-
| Name | Roll number | Age | Gender |
|---|---|---|---|
| Aarav | 1 | 15 | Male |
| Harshit | 2 | 14 | Male |
| Kanika | 3 | 16 | Female |
| Mayank | 4 | 15 | Male |
面板-这是一个包含异构数据的3维数据结构。用图形表示面板是非常困难的,但是可以将其说明为DataFrame的容器。
下表为我们提供了有关熊猫中使用的上述数据结构的维度和说明-
| Data Structure | Dimension | Description |
|---|---|---|
| Series | 1-D | Size immutable, 1-D homogeneous data |
| DataFrames | 2-D | Size Mutable, Heterogeneous data in tabular form |
| Panel | 3-D | Size-mutable array, container of DataFrame. |
我们可以理解这些数据结构,因为高维数据结构是低维数据结构的容器。
安装与执行
如果您使用的是Anaconda发行版,则无需单独安装熊猫,因为它已经安装了它。您只需要在以下帮助下将包导入到您的Python脚本中-
import pandas as pd
另一方面,如果您使用的是标准Python发行版,则可以使用流行的Python软件包安装程序pip安装Pandas。
pip install Pandas
安装Pandas之后,您可以像上面一样将其导入到Python脚本中。
例
以下是使用Pandas从ndarray创建系列的示例-
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: data = np.array(['g','a','u','r','a','v'])
In [4]: s = pd.Series(data)
In [5]: print (s)
0 g
1 a
2 u
3 r
4 a
5 v
dtype: object
有关Pandas的详细研究,请访问链接www.tutorialspoint.com/python_pandas/index.htm 。
Scikit学习
Scikit-learn是用于Python的数据科学和机器学习的另一个有用且最重要的Python库。以下是Scikit学习的一些功能,使其变得非常有用-
-
它基于NumPy,SciPy和Matplotlib构建。
-
它是开源的,可以在BSD许可下重复使用。
-
每个人都可以使用它,并且可以在各种环境中重复使用它。
-
借助它,可以实现涵盖机器学习主要领域的广泛机器学习算法,例如分类,聚类,回归,降维,模型选择等。
安装与执行
如果您使用的是Anaconda发行版,则无需单独安装Scikit-learn,因为它已经安装了它。您只需要在Python脚本中使用该包即可。例如,使用以下脚本行,我们从Scikit-learn导入乳腺癌患者的数据集-
from sklearn.datasets import load_breast_cancer
另一方面,如果您使用标准的Python发行版并具有NumPy和SciPy,则可以使用流行的Python软件包安装程序pip安装Scikit-learn。
pip install -U scikit-learn
安装Scikit-learn之后,您可以像上面一样将其用于Python脚本中。