- 并行计算机体系结构教程
- 并行计算机体系结构教程(1)
- 并行计算机体系结构-资源(1)
- 并行计算机体系结构-资源
- 并行计算机体系结构-简介
- 并行计算机体系结构-简介(1)
- 讨论并行计算机体系结构
- 讨论并行计算机体系结构(1)
- 计算机体系结构与计算机组织(1)
- 计算机体系结构与计算机组织
- 计算机体系结构和计算机组织之间的差异
- 计算机体系结构和计算机组织之间的差异(1)
- 计算机体系结构和计算机组织之间的差异
- 计算机体系结构和计算机组织之间的差异
- 计算机体系结构和计算机组织之间的差异(1)
- 并行代码 (1)
- 计算机体系结构中的内存组织(1)
- 计算机体系结构中的内存组织
- 计算机体系结构中的内存组织(1)
- 计算机体系结构中的内存组织
- 计算机体系结构中的流水线 (1)
- 计算机体系结构中的流水线 - 任何代码示例
- 什么是计算机体系结构中的流水线 (1)
- 并行化循环 c++ (1)
- 计算机图形学并行投影(1)
- 计算机图形学并行投影
- 什么是计算机体系结构中的流水线 - 无论代码示例
- 并行测试(1)
- 并行测试
📅 最后修改于: 2020-12-13 15:19:53 🧑 作者: Mango
并行处理已发展成为现代计算机中的一种有效技术,可以满足现实应用中对更高性能,更低成本和准确结果的需求。由于多程序,多处理或多计算的实践,并发事件在当今的计算机中很常见。
现代计算机具有功能强大且功能强大的软件包。要分析计算机性能的发展,首先我们必须了解硬件和软件的基本发展。
-
计算机开发的里程碑–计算机的开发有两个主要阶段-机械或机电零件。在引入电子组件之后,现代计算机得到了发展。电子计算机中的高迁移率电子取代了机械计算机中的操作部件。对于信息传输,几乎以光速传播的电信号取代了机械齿轮或杠杆。
-
现代计算机的要素-现代计算机系统由计算机硬件,指令集,应用程序,系统软件和用户界面组成。
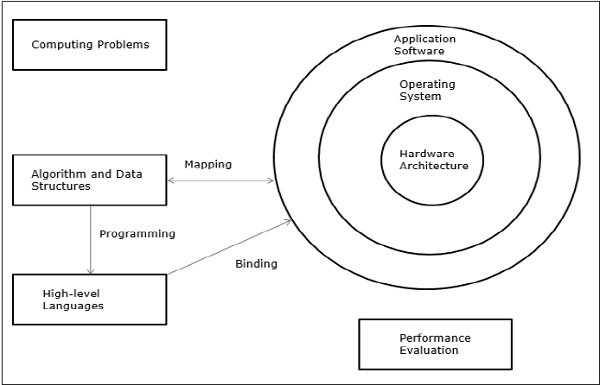
计算问题可分为数值计算,逻辑推理和事务处理。一些复杂的问题可能需要将所有三种处理模式结合起来。
-
计算机体系结构的演进-在过去的四十年中,计算机体系结构经历了革命性的变化。我们从Von Neumann架构开始,现在有了多计算机和多处理器。
-
计算机系统的性能-计算机系统的性能取决于机器功能和程序行为。可以通过更好的硬件技术,先进的体系结构功能和有效的资源管理来提高机器功能。程序行为是不可预测的,因为它取决于应用程序和运行时条件
多处理器和多计算机
在本节中,我们将讨论两种类型的并行计算机-
- 多处理器
- 多机
共享内存多计算机
三种最常见的共享内存多处理器模型是:
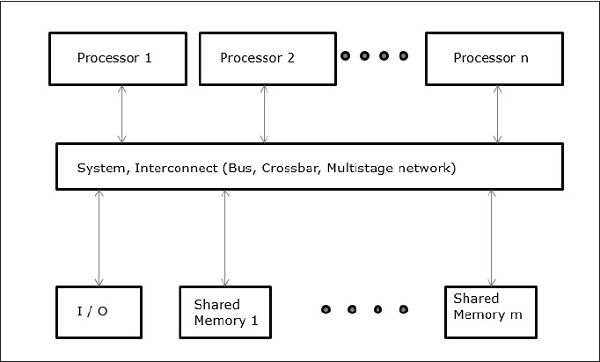
统一内存访问(UMA)
在此模型中,所有处理器都统一共享物理内存。所有处理器对所有存储字的访问时间均相等。每个处理器可以具有专用高速缓存存储器。外围设备遵循相同的规则。
当所有处理器对所有外围设备都有平等的访问权时,该系统称为对称多处理器。当只有一个或几个处理器可以访问外围设备时,该系统称为非对称多处理器。
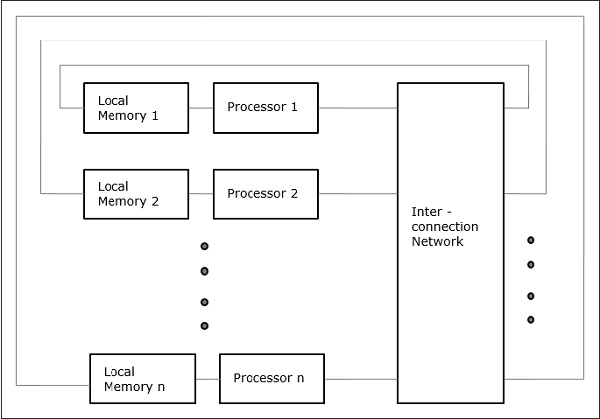
非统一内存访问(NUMA)
在NUMA多处理器模型中,访问时间随存储字的位置而变化。在这里,共享内存在物理上分布在所有处理器之间,称为本地内存。所有本地存储器的集合形成了一个全局地址空间,所有处理器都可以访问该地址空间。
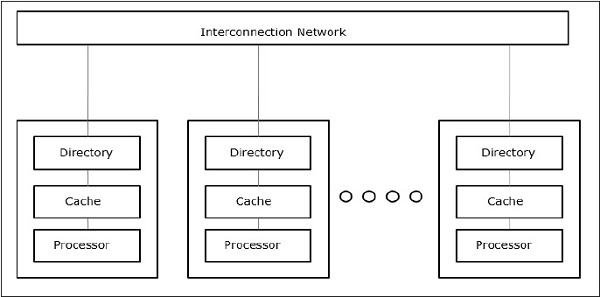
仅缓存内存架构(COMA)
COMA模型是NUMA模型的特例。在此,所有分布式主存储器都转换为高速缓存。
-
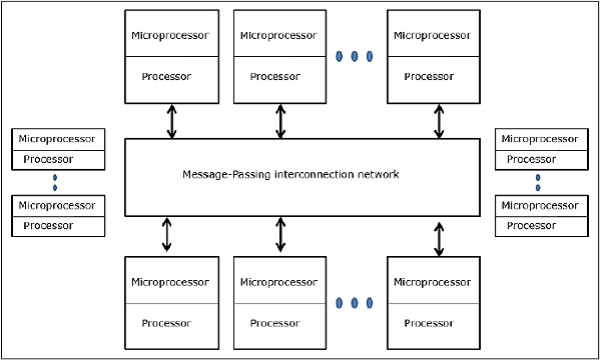
分布式-内存多计算机-分布式内存多计算机系统由多台计算机组成,称为节点,通过消息传递网络相互连接。每个节点充当具有处理器,本地存储器以及有时是I / O设备的自治计算机。在这种情况下,所有本地存储器都是私有的,并且只能由本地处理器访问。这就是为什么传统的机器被称为无远程内存访问(NORMA)机器。
Multivector和SIMD计算机
在本节中,我们将讨论用于矢量处理和数据并行性的超级计算机和并行处理器。
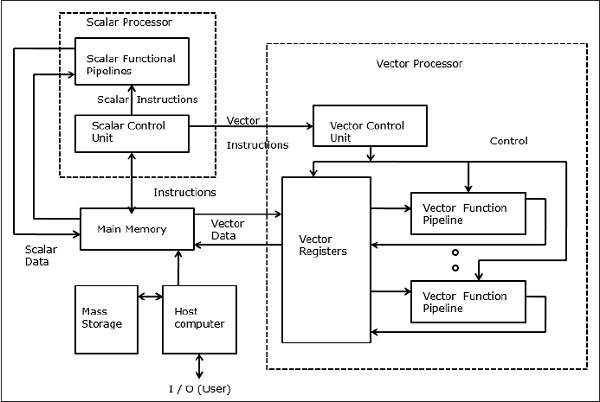
矢量超级计算机
在矢量计算机中,矢量处理器作为可选功能附加到标量处理器。主机首先将程序和数据加载到主存储器。然后,标量控制单元对所有指令进行解码。如果解码的指令是标量运算或程序运算,则标量处理器使用标量功能流水线执行那些运算。
另一方面,如果解码的指令是矢量操作,则指令将被发送到矢量控制单元。
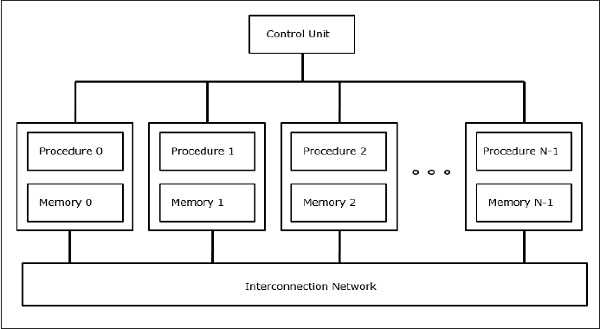
SIMD超级计算机
在SIMD计算机中,“ N”个处理器连接到控制单元,并且所有处理器都有各自的存储单元。所有处理器均通过互连网络连接。
PRAM和VLSI型号
理想模型为开发并行算法提供了合适的框架,而无需考虑物理约束或实现细节。
可以强制使用这些模型来获得并行计算机上的理论性能界限,或者在制造芯片之前评估芯片面积和工作时间上的VLSI复杂性。
并行随机存取机
Sheperdson和Sturgis(1963)将传统的单处理器计算机建模为随机存取机(RAM)。 Fortune和Wyllie(1978)开发了一个并行随机存取机(PRAM)模型,用于对理想的并行计算机进行建模,其零内存访问开销和同步。
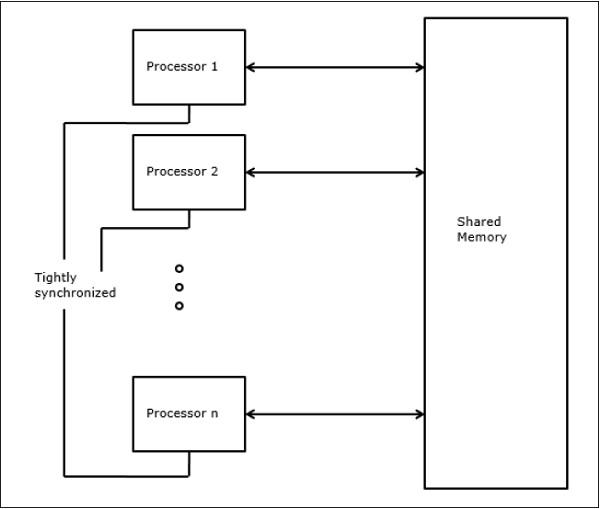
N处理器PRAM具有共享的存储单元。该共享内存可以在处理器之间集中或分布。这些处理器在同步的读取存储器,写入存储器和计算周期上运行。因此,这些模型指定如何处理并发读取和写入操作。
以下是可能的内存更新操作-
-
独占读取(ER) -在此方法中,在每个周期中,只允许一个处理器从任何内存位置读取。
-
独占写入(EW) -在这种方法中,一次至少允许一个处理器写入一个内存位置。
-
并发读取(CR) -它允许多个处理器在同一周期内从同一内存位置读取同一信息。
-
并发写入(CW) -它允许对同一内存位置同时进行写操作。为了避免写冲突,设置了一些策略。
VLSI复杂度模型
并行计算机使用VLSI芯片制造处理器阵列,存储器阵列和大规模交换网络。
如今,VLSI技术是二维的。 VLSI芯片的大小与该芯片中可用的存储(内存)空间量成正比。
我们可以通过算法的VLSI芯片实现的芯片面积(A)来计算该算法的空间复杂度。如果T是执行算法所需的时间(等待时间),则AT给出通过芯片(或I / O)处理的总比特数的上限。对于某些计算,存在一个下限f(s),使得
AT 2 > = O(f(s))
其中A =芯片面积,T =时间
建筑发展轨迹
我沿着以下方向传播了并行计算机的发展-
- 多个处理器轨道
- 多处理器轨道
- 多机跟踪
- 多数据轨道
- 矢量轨道
- SIMD轨道
- 多线程跟踪
- 多线程轨道
- 数据流跟踪
在多处理器轨道中,假定不同的线程在不同的处理器上同时执行,并通过共享内存(多处理器轨道)或消息传递(多计算机轨道)系统进行通信。
在多数据轨道中,假定对大量数据执行相同的代码。通过在一系列数据元素(矢量轨道)上执行相同的指令,或通过在一组相似的数据(SIMD轨道)上执行相同的指令序列,可以完成此操作。
在多线程轨道中,假定在同一处理器上交错执行各种线程以隐藏在不同处理器上执行的线程之间的同步延迟。线程交织可以是粗糙的(多线程轨道)或精细的(数据流轨道)。