机器学习中的投影视角
在进入投影视角之前,让我们首先了解一种称为 PCA 的技术,它的需求是什么以及它在哪里使用。
主成分分析:
它是一种自适应数据分析技术,用于降低大型数据集的维数,提高可解释性,同时最大限度地减少信息和重建损失。在机器学习术语中,它用于根据参数(回归量)对预测输出的贡献程度来减少参数(回归量)的数量,以便它们可以在 2D/3D 图中以图形方式表示。让我们考虑以下具有 5 个输入参数的回归模型。

where,
y -> output (dependent variable).
x1, ..., x5 -> input parameters / regressors (independent variable).
w1, ..., w5 -> weights assigned to the input parameters. 由于有 5 个变量,因此无法以图形方式表示此模型,但我们最多只能绘制 3 维数据。因此,我们使用 PCA,它接收输入 n,其中 n 表示有助于找到输出 y 的 n 个最重要的回归量。假设 n = 2,那么我们将得到 2 个新参数,它们将最好地确定输出 y is 方程现在将是:

在二维中表示数据真的很容易。
投影透视
这是 PCA 中使用的一种技术,可进一步最小化数据重建成本。数据重建只是意味着将较高维度的数据点减少到易于解释的较低维度。在该方法中,我们将关注原始数据向量x i和重构数据向量x i '之间的差异。为此,我们找到了一个子空间(线),可以最小化原始数据点与其投影之间的差异向量,如图 1 所示。
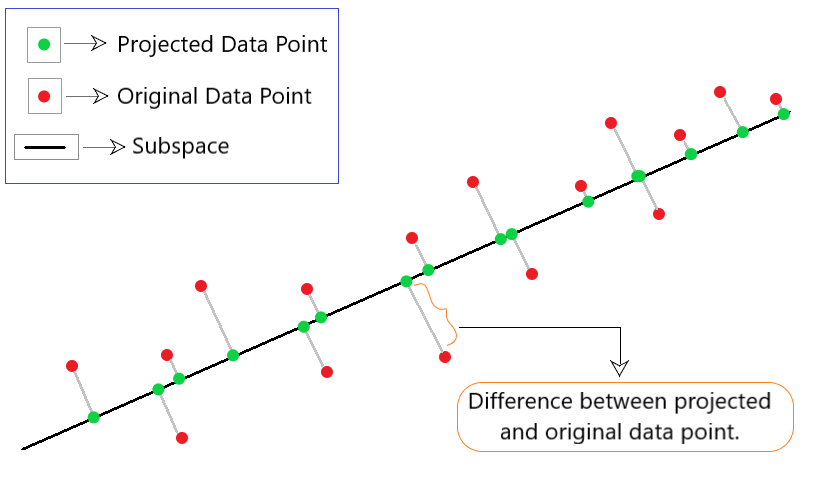
图 1:投影方法的图示
线性独立
它指出总会有一组向量,我们可以通过将它们加在一起并缩放它们来表示向量空间中的每个向量。这组向量称为基。通常,我们可以将向量相加,然后将它们与标量相乘,如下面给出的等式所示:

where,
V -> vector space
v -> formed vector
x1...i -> original vector
λ1...i -> scalar values直觉
考虑一个正交基,B = (b 1 , . . , b N )。
Orthogonal Basis implies biTbj = 1 iff (i = j) and 0 otherwise.
根据线性独立的概念,基 B 可以定义为基向量的线性组合。 (下面给出的方程)

where,
v -> linear combination of basis vector existing in the higher dimension.
x -> suitable coordinates for v.现在,我们有兴趣找出存在于较低维度U (称为主子空间)中的向量 v',其中, dim(U) = I。我们可以使用以下等式找到 v':

where,
v' -> new vector existing in the lower dimensions.
y -> suitable coordinates for v'.Assuming that coordinates yi and xi are not identical to each other.
基于以上 2 个等式,我们确保在较低维度中找到的向量 v'与较高维度中的向量 v 尽可能相似。
现在,目标是最小化高维和低维向量之间的差异(或最小化重构误差)。为了测量向量 v和v'之间的相似性,我们使用以下等式找到它们之间的平方欧几里德距离(也称为重构误差):

考虑下面给出的图像:
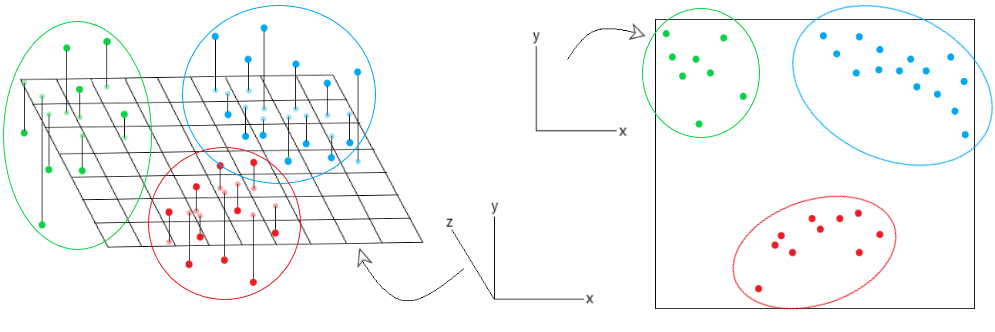
在观察左侧的图形时,我们已经绘制了数据点在 3D 平面上的投影。然而,我们不能轻易地将数据分成不同的集群,因为它们可能相互重叠。使用 PCA 中的投影透视图,我们可以将 3D 数据点投影到 2D 平面上。通过这种方式,可以更轻松地将数据解释为不同的集群。这是在 PCA 算法中使用不同透视方法(如投影透视)的一大优势。对于下面的任何疑问/查询评论。