📌 相关文章
- Apache Spark计数功能(1)
- Apache Spark计数功能
- Apache Spark过滤器功能
- Apache Spark过滤器功能(1)
- Apache Spark接受功能(1)
- Apache Spark接受功能
- Apache Spark独特功能(1)
- Apache Spark独特功能
- Apache Spark安装
- Apache Spark安装(1)
- Apache Spark安装
- Apache Spark-安装(1)
- Apache Spark-安装
- Apache Spark协同功能
- Apache Spark协同功能(1)
- Apache Spark 的组件
- Apache Spark组件(1)
- Apache Spark组件
- Apache Spark组件
- Apache Spark 的组件(1)
- Apache Spark组件(1)
- Apache Spark教程(1)
- Apache Spark教程
- Apache Spark教程
- Apache Spark教程
- Apache Spark教程(1)
- Apache Spark简介
- Apache Spark简介(1)
- Apache Spark简介(1)
📜 Apache Spark第一个功能
📅 最后修改于: 2020-12-27 02:50:32 🧑 作者: Mango
火花优先功能
在Spark中,First函数始终返回数据集的第一个元素。它类似于take(1)。
第一个函数示例
在此示例中,我们检索数据集的第一个元素。
- 要在Scala模式下打开Spark,请遵循以下命令。
$ spark-shell

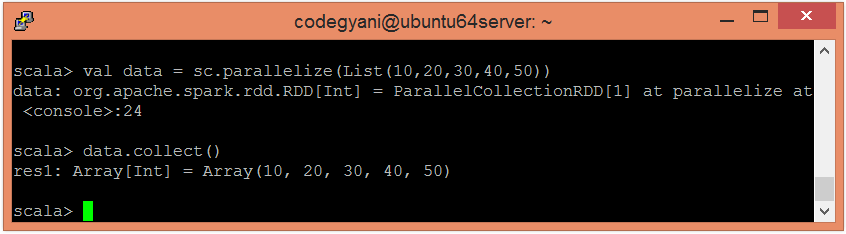
- 使用并行化的集合创建一个RDD。
scala> val data = sc.parallelize(List(10,20,30,40,50))
- 现在,我们可以使用以下命令读取生成的结果。
scala> data.collect
- 应用first()函数检索数据集的第一个元素。
scala> val firstfunc = data.first()

在这里,我们得到了期望的输出。