📌 相关文章
- PDFBox-阅读文字
- PDFBox-阅读文字(1)
- PDFBox-添加文本
- PDFBox添加文本
- PDFBox添加文本(1)
- PDFBox-添加文本(1)
- 代码阅读与阅读
- 代码阅读与阅读(1)
- 阅读文本时跳过标题 - C++ (1)
- 阅读文本时跳过标题 - C++ 代码示例
- pdfbox 打印示例 (1)
- 阅读双java(1)
- PDFBox使用元数据(1)
- PDFBox使用元数据
- PDFBox验证
- PDFBox教程
- PDFBox教程(1)
- PDFBox教程(1)
- PDFBox教程
- 阅读pdf文本php代码示例
- PDFBox功能
- 讨论PDFBox
- 讨论PDFBox(1)
- PDFBox-环境(1)
- PDFBox-环境
- PDFBox-概述(1)
- PDFBox-概述
- 阅读双java代码示例
- PDFBox-删除页面(1)
📜 PDFBox阅读文本
📅 最后修改于: 2021-01-07 07:39:10 🧑 作者: Mango
PDFBox阅读文字
PDFBox库的主要功能之一是能够快速,准确地从现有PDF文档中提取文本。在本节中,我们将学习如何使用Java程序从PDFBox库中的现有文档中读取文本。 PDF文档可能包含文本,动画和图像等作为其文本内容。我们可以使用PDFTextStripper类的getText()方法从现有的PDF文档中提取文本。
请按照以下步骤从现有的PDF文档中读取文本-
载入PDF文件
我们可以使用static load()方法加载现有的PDF文档。此方法接受文件对象作为参数。我们也可以使用PDFBox的类名PDDocument调用它。
File file = new File("Path of Document");
PDDocument doc = PDDocument.load(file);
实例化PDFTextStripper类
PDFTextStripper类用于从PDF文档中检索文本。我们可以实例化该类,如下所示:
PDFTextStripper pdfStripper = new PDFTextStripper();
检索文字
getText()方法用于从PDF文档中读取文本内容。在这种方法中,我们需要将文档对象作为参数传递。此方法将文本作为字符串对象返回。
String text = pdfStripper.getText(doc);
关闭文件
完成任务后,我们需要使用close()方法关闭PDDocument类对象。
doc.close();
例-
这是一个PDF文档,我们将使用Java程序的PDFBox库提取其文本内容。
Java程序
import java.io.File;
import java.io.IOException;
import java.io.File;
import java.io.IOException;
import org.apache.pdfbox.pdmodel.PDDocument;
import org.apache.pdfbox.text.PDFTextStripper;
public class ExtractText {
public static void main(String[] args)throws IOException {
//Loading an existing document
File file = new File("/eclipse-workspace/blank.pdf");
PDDocument doc = PDDocument.load(file);
//Instantiate PDFTextStripper class
PDFTextStripper pdfStripper = new PDFTextStripper();
//Retrieving text from PDF document
String text = pdfStripper.getText(doc);
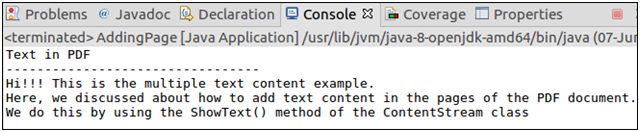
System.out.println("Text in PDF\n---------------------------------");
System.out.println(text);
//Closing the document
doc.close();
}
}
输出:
成功执行后,上述程序从PDF文档中检索文本,如以下输出所示。