- 解析 xml ruby (1)
- 解析 xml ruby 代码示例
- XML - C# (1)
- c# xml - C# (1)
- xml (1)
- XML示例(1)
- XML示例
- !在 ruby 中(1)
- 类 ruby (1)
- Ruby-块
- Ruby-块(1)
- Ruby块(1)
- Ruby块
- ruby |= - Ruby (1)
- c# xml - C# 代码示例
- XML - C# 代码示例
- ruby |= - Ruby 代码示例
- ruby 方法 - Ruby (1)
- PHP和XML(1)
- PHP和XML
- ruby 方法 - Ruby 代码示例
- 字符串到xml c#(1)
- xml 与 html (1)
- HTML 与 XML
- HTML与XML
- HTML与XML(1)
- HTML 与 XML(1)
- HTML 与 XML
- XML |元素(1)
📅 最后修改于: 2021-01-08 13:24:09 🧑 作者: Mango
Ruby XML(REXML)
XML是HTML等可扩展标记语言。它允许程序员开发可以被其他应用程序读取的应用程序,而与所使用的操作系统和开发语言无关。
无需在后端使用任何基于SQL的技术,即可跟踪中小型数据。
REXML是纯Ruby XML处理器。它表示一个完整的XML文档,包括PI,doctype等。XML文档具有单个子级,可以通过root()访问。如果要为已创建的文档提供XML声明,则必须添加一个。 REXML文档不会为您编写默认声明。
REXML受Java的Electric XML库的启发。它的API易于使用,体积小并且遵循Ruby方法进行方法命名和代码流。
它支持树和流文档解析。 Steam解析比树解析快1.5倍。但是,在流解析中,您无法访问某些功能,例如XPath。
REXML功能:
- 它是用Ruby 100%编写的。
- 它包含少于2000行代码,因此重量更轻。
- 它的方法和类很容易理解。
- 它随Ruby安装一起提供。无需单独安装。
- 它用于DOM和SAX解析。
解析XML和访问元素
让我们从解析XML文档开始:
require "rexml/document"
file = File.new( "trial.xml" )
doc = REXML::Document.new file
在上面的代码中,第3行分析提供的文件。
例:
require 'rexml/document'
include REXML
file = File.new("trial.xml")
doc = Document.new(file)
puts docs
在上面的代码中, require语句加载REXML库。然后包含REXML表示我们不必使用REXML :: Document之类的名称。我们已经创建了trial.xml文件。文档显示在屏幕上。
输出:

Document.new方法将IO,String对象或Document作为其参数。此参数指定必须从中读取XML文档的源。
如果Document构造函数将Document作为参数,则其所有元素节点都将克隆到新的Document对象。如果构造函数采用String参数,则预期字符串将包含XML文档。
具有“此处文档”的XML
此处文档是一种指定文本块,保留换行符,空格或文本标识的方法。
这里的文档是使用命令,后跟“ <<”和后跟标记字符串的命令构造的。
在Ruby中,“ <<”和令牌字符串之间不应有空格。
例:
#!/usr/bin/env ruby
require 'rexml/document'
include REXML
info = <
Caroline
9820 St.
Seattle
9854126575
USA
XML
document = Document.new( info )
puts document
在这里,我们在此处使用文档信息。所有包括<< EOF和EOF之间换行符的字符信息的一部分。
对于XML解析示例,我们将使用以下XML文件代码作为输入:
文件trial.xml
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("trial.xml")
xmldoc = Document.new(xmlfile)
# Now get the root element
root = xmldoc.root
puts "Root element : " + root.attributes["shelf"]
# This will output all the cloth titles.
xmldoc.elements.each("collection/clothing"){
|e| puts "cloth Title : " + e.attributes["title"]
}
# This will output all the cloth types.
xmldoc.elements.each("collection/clothing/type") {
|e| puts "cloth Type : " + e.text
}
# This will output all the cloth description.
xmldoc.elements.each("collection/clothing/description") {
|e| puts "cloth Description : " + e.text
}
Ruby XML DOM类解析
我们将以树的形式解析XML数据。上面的文件trial.xml代码被用作输入。
#!/usr/bin/ruby -w
require 'rexml/document'
include REXML
xmlfile = File.new("trial.xml")
xmldoc = Document.new(xmlfile)
# Now get the root element
root = xmldoc.root
puts "Root element : " + root.attributes["shelf"]
# This will output all the cloth titles.
xmldoc.elements.each("collection/clothing"){
|e| puts "cloth Title : " + e.attributes["title"]
}
# This will output all the cloth types.
xmldoc.elements.each("collection/clothing/type") {
|e| puts "cloth Type : " + e.text
}
# This will output all the cloth description.
xmldoc.elements.each("collection/clothing/description") {
|e| puts "cloth Description : " + e.text
}
输出:
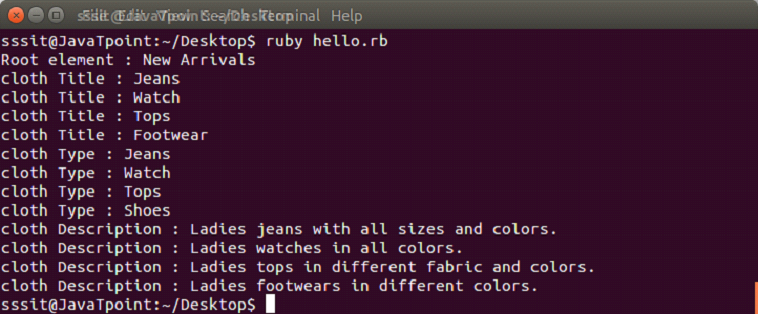
像Ruby XML SAX一样的解析
我们将以流方式解析XML数据。上面的文件trial.xml代码被用作输入。在这里,我们将定义一个侦听器类,该类的方法将用于解析器的回调。
建议不要对小型文件使用类似于SAX的解析。
#!/usr/bin/ruby -w
require 'rexml/document'
require 'rexml/streamlistener'
include REXML
class MyListener
include REXML::StreamListener
def tag_start(*args)
puts "tag_start: #{args.map {|x| x.inspect}.join(', ')}"
end
def text(data)
return if data =~ /^\w*$/ # whitespace only
abbrev = data[0..40] + (data.length > 40 ? "..." : "")
puts " text : #{abbrev.inspect}"
end
end
list = MyListener.new
xmlfile = File.new("trial.xml")
Document.parse_stream(xmlfile, list)
输出:
