XPath 简介
XPath(XML Path)是一个表达式,用于在 XML 文档中查找元素或节点。在Selenium中,它通常用于查找 Web 元素。
例子:
//input[@id = 'fakebox-input']在这个例子中,我们正在定位'id'等于'fakebox-input'的'input'元素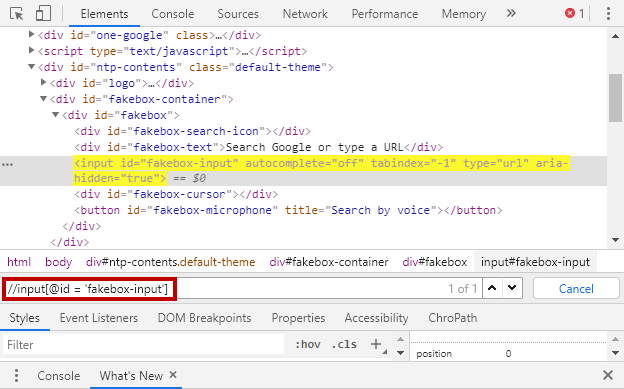
XML 代码:
IIT Mathematics
A Das Gupta
Inorganic chemistry for JEE
V K Jaiswal
正如我们在上面的 XML 中看到的,XML 代码是一个树状结构,代码以具有子节点book的bookstore 节点开始,后面是一个值为'Math'的属性类别。 book节点有 2 个子节点,即title和author 。
要选择化学书的作者元素,将使用以下 XPath:
/bookstore/book[@category='Chemistry']/authorXPath 的语法:
//tagname[@attribute = ‘value’]XPath 表达式:
| Symbol | Description |
|---|---|
| // | Selects nodes in the document from the current node that match the selection no matter where they are |
| / | Selects the root node |
| tagname | Tag name of the current node |
| @ | Select the attribute |
| attribute | Attribute name of the node |
| value | Value of the attribute |
XPath 的类型:
- 绝对 XPath
- 相对 Xpath
绝对 XPath:
绝对 XPath 使用 HTML/XML 代码的根元素,然后是到达所需元素所需的所有元素。它以正斜杠'/'开头。通常,不推荐使用绝对 XPath,因为将来添加或删除任何 Web 元素时,绝对 XPath 都会发生变化。
- 例子:
/html[1]/body[1]/div[6]/div[1]/div[3]/div[1]/div[1]/div[1]/div[3]/ul[1]/li[2]/a[1]
相对 XPath;
在此,XPath 以双斜杠“//”开头,这意味着它可以搜索网页中任何位置的元素。通常相对 Xpath 是首选,因为它们不是来自根节点的完整路径。
- 例子:
//input[@id = 'fakebox-input']
如果您想学习如何使 XPath 识别 webelements,然后在 chrome 浏览器中打开网页并通过右键单击网页检查元素,然后按“ctrl+f”以使用 XPath 查找 webelements。您还可以使用像'chropath'这样的 chrome 扩展来查找webelement的xpath 。
常用的 XPath 函数:
- 包含()
- 从...开始()
- 文本()
contains():该函数用于选择其指定属性值包含函数参数中提供的指定字符串的节点。
例子:
//input[contains(@id, 'fakebox')]
starts-with():该函数用于选择其指定属性值以函数参数中提供的指定字符串值开头的节点。
例子:
//input[starts-with(@id, 'fakebox')]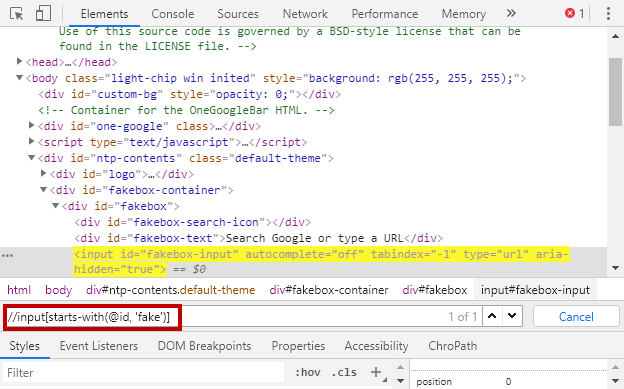
text():该函数用于查找与函数中指定的字符串值完全匹配的节点。
例子:
//div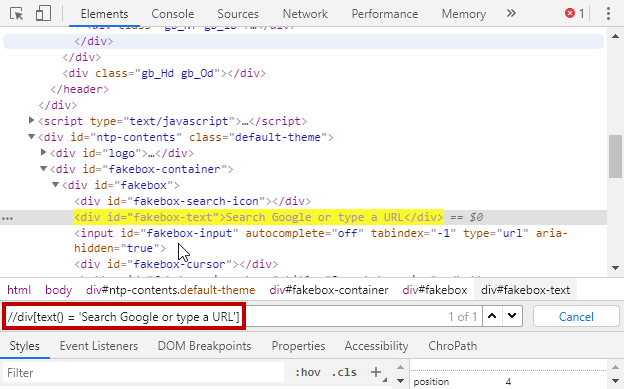
XPath 中 AND 和 OR 的使用
AND 和 OR 用于结合两个或多个条件来查找节点。
例子:
//input[@value = 'Log In' or @type = 'submit']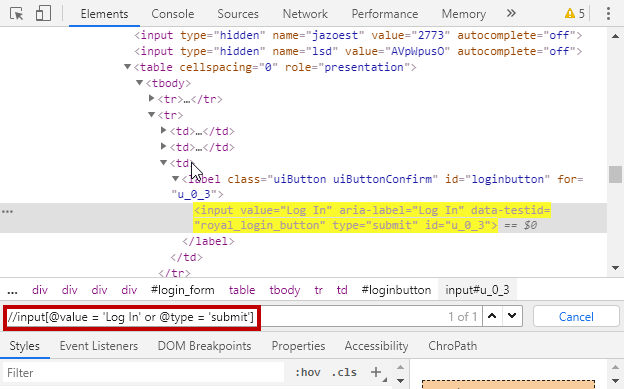
同样,我们可以在 XPath 中应用 AND运算符。